深度学习Caffe实战之人脸检测
此篇文章是对tyd老师的人脸检测课程的自我总结,按需查看,概不负责。
一、目的:
检测到人脸框,效果图如下:

二、数据分析&预处理:
2.1 数据获取
网站下载benchmark
1、论坛:http://www.thinkface.cn/portal.php
2、MPII数据集:http://human-pose.mpi-inf.mpg.de/
3、FDDB数据集:http://vis-www.cs.umass.edu/fddb/index.html#download
4、GitHub扒源码 ......
2.2 二分类问题
0类人脸,1类非人脸
0类人脸数据:路径;(左上角x坐标,左上角y坐标,右上角x坐标,右上角y坐标)
eg.20,60,247,287【可以有其他人脸框形式,不是非得坐标】
1类非人脸数据:非人脸的都行
2.3 数据集规模
越大越好
三、环境:
Linux:Ubuntu
四、制作数据源:
先引入一个概念IOU(intersection of union)即裁剪框之间的重叠比例:
 eg.此图A、B框就没有交叉,即IOU为0。
eg.此图A、B框就没有交叉,即IOU为0。
做法:利用opencv工具对收集到的数据集图像进行裁剪,根据标注坐标的样式来复现人脸块。
截出来这么多框,把0.3≤IOU≤0.7(IOU自己根据项目具体需求设定)的框去掉,因为这种框说人脸也不算,说非人脸也不算。而非人脸数据框则IOU≤0.3,人脸数据框则IOU≥0.7(对于人脸遮蔽不全等现象效果会提高一些)。
再人工检查数据集制作的有没有问题,可能出现的问题:
一幅图中有两张人脸,但是该图label仅有一个,那么就是一个被标定,另一个没有。致使在制作非人脸数据集时混入了另一个人脸数据。那么怎么办呢?很简单,请个实习生筛。
什么?你没钱没时间?那么就随便找个其他的自然、物体数据集作为非人脸数据集咯~怎么裁剪都不会带有人脸~
裁剪好的正样本人脸图如下所示:

五、训练分类网络:
具体的不写了,写一些注意事项:
1、lmdb格式适用于单label,对于多label(eg.坐标)数据源用hdf5
2、统一网络输入图像size(vgg固定227)
3、最后一层全连接层改为需分类个数
4、改变层baselr*10,decaymult不变
5、bias影响不大,重点关注weights
6、solver文件:
test_iter:测试一次多少batch,覆盖整个测试集,样本个数=test_iter*test_batch_size;
test_interval:测试一次训练迭代多少次,覆盖整个训练集,样本个数=test_interval*train_batch_size;
7、训练时候先打开solver文件,接下来找到net,再将参数填进去按学习策略训练。
8、网络训练速度:1)模型网络结构越深,训练速度越慢;2)数据输入越大,训练速度越慢;2)影响更大
9、网络loss值:浮动的,只要趋势下降即可
10、过拟合后,将学习率调小一些
这一步主要是得到分类人脸的caffemodel!!!得到这个模型后我们咋办?接着往下看
六、代码实现人脸检测
问题一:
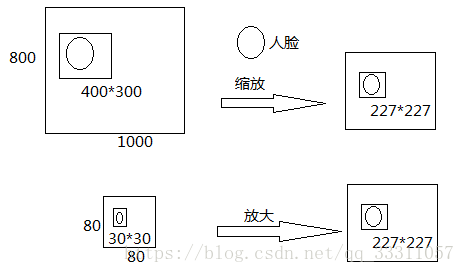
假设我们训练的网络输入图像大小是227*227,那么我们得到的测试图像一定是227*227的吗?
不见得吧?那么我们该怎么办?
用一个227*227的滑动窗口滑过待测原始图像不就得了?你以为这就行了?nonono~
有的人脸在原始图像上特别小或者特别大怎么办,并不是正正好好满足227*227的啊,怎么办?
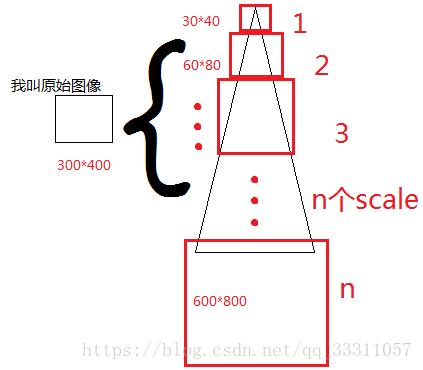
对原始图像进行多尺度变换不就可以了?做法如下图所示:
那么问题又来了,我们该缩放多少倍呢?其实这没有一个准确的答案,我们只能做到设定确定个数的scale,然后进行缩放。
如下为图解:
用我们训练模型的输入大小m*m滑动去框,直到出现某scale图,网络识别出了人脸(万一好几个scale,网络都说识别出了人脸呢,那就都算咯~)。
问题二:
人脸识别的具体流程是搞明白了,但是测试图像集里边的图像大小一定是相同的吗?
caffe的net里fc层前边特征图大小是固定不可变的,那么对于不同大小的图肯定是不可行的。那么怎么办呢?
设置模型网络结构的时候,将fc层转换为kernelsize为1*1的conv层不就好了。

具体更改方式详情参考:
http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/net_surgery.ipynb
其实这一步主要是按官网修改caffemodel~
后续再加。(博客会一点点从私密转为公开)