mysql主从同步概念(转载)
参考:https://www.cnblogs.com/kevingrace/p/10228694.html
参考:https://www.cnblogs.com/kevingrace/p/6256603.html
Mysql复制概念
Mysql内建的复制功能是构建大型高性能应用程序的基础, 将Mysql数据分布到多个系统上,这种分布机制是通过将Mysql某一台主机数据复制到其它主机(slaves)上,并重新执行一遍来实现的。复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。当一个从服务器连接主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。
Mysql支持哪些复制
- 基于语句的复制: 在主服务器执行SQL语句,在从服务器执行同样语句。MySQL默认采用基于语句的复制,效率较高。一旦发现没法精确复制时, 会自动选基于行的复制。
- 基于行的复制: 把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从mysql5.0开始支持
- 混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
Mysql复制解决的问题
- 数据分布 (Data distribution )
- 负载平衡(load balancing)
- 据备份(Backups) ,保证数据安全
- 高可用性和容错行(High availability and failover)
- 实现读写分离,缓解数据库压力
Mysql主从复制原理
master服务器将数据的改变都记录到二进制binlog日志中,只要master上的数据发生改变,则将其改变写入二进制日志;salve服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O Thread请求master二进制事件,同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后I/O Thread和SQL Thread将进入睡眠状态,等待下一次被唤醒。
需要理解:
- 从库会生成两个线程,一个I/O线程,一个SQL线程;
- I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
- 主库会生成一个log dump线程,用来给从库I/O线程传binlog;
- SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;
这里注意几点:
- master将操作语句记录到binlog日志中,然后授予slave远程连接的权限(master要开启binlog二进制日志功能;通常为了数据安全考虑,slave也开启binlog);
- slave开启两个线程:IO线程和SQL线程。其中:IO线程负责读取master的binlog内容到中继日志relay log里;SQL线程负责从relay log日志里读出binlog内容,并更新到slave的数据库里,这样就能保证slave数据和master数据保持一致了;
- mysql复制至少需要两个Mysql的服务,当然Mysql服务可以分布在不同的服务器上,也可以在一台服务器上启动多个服务;
- mysql复制最好确保master和slave服务器上的Mysql版本相同(如果不能满足版本一致,那么要保证master主节点的版本低于slave从节点的版本);
- master和slave两节点间时间需同步;
Mysql复制流程图
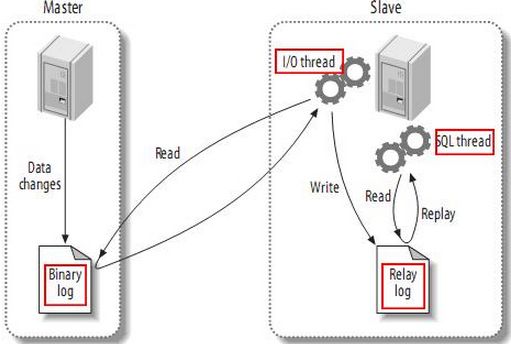
如上图所示:
- Mysql复制过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的 语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务;
- 第二部分就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程(I/O线程)。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志;
- SQL slave thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与 I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小;
- 此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制, 即复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
Mysql复制方案
主从复制: 主库授权从库远程连接,读取binlog日志并更新到本地数据库的过程;主库写数据后,从库会自动同步过来(从库跟着主库变);
主主复制: 主从相互授权连接,读取对方binlog日志并更新到本地数据库的过程;只要对方数据改变,自己就跟着改变;
Mysql主从复制优点
在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
在从主服务器进行备份,避免备份期间影响主服务器服务;(确保数据安全)
当主服务器出现问题时,可以切换到从服务器。(提升性能)
Mysql主从复制工作流程关键细节
1) MySQL支持单向、异步复制,复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。MySQL复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新、删除等等)。因此,要进行复制,必须在主服务器上启用二进制日志。每个从服务器从主服务器接收主服务器上已经记录到其二进制日志的保存的更新。当一个从服务器连接主服务器时,它通知主服务器定位到从服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,并在本机上执行相同的更新。然后封锁并等待主服务器通知新的更新。从服务器执行备份不会干扰主服务器,在备份过程中主服务器可以继续处理更新。
2) MySQL使用3个线程来执行复制功能,其中两个线程(Sql线程和IO线程)在从服务器,另外一个线程(IO线程)在主服务器。当发出START SLAVE时,从服务器创建一个I/O线程,以连接主服务器并让它发送记录在其二进制日志中的语句。主服务器创建一个线程将二进制日志中的内容发送到从服务器。该线程可以即为主服务器上SHOW PROCESSLIST的输出中的Binlog Dump线程。从服务器I/O线程读取主服务器Binlog Dump线程发送的内容并将该数据拷贝到从服务器数据目录中的本地文件中,即中继日志。第3个线程是SQL线程,由从服务器创建,用于读取中继日志并执行日志中包含的更新。在从服务器上,读取和执行更新语句被分成两个独立的任务。当从服务器启动时,其I/O线程可以很快地从主服务器索取所有二进制日志内容,即使SQL线程执行更新的远远滞后。
mysql 主从复制注意事项小结
Mysql主从数据完成同步的过程
1) 在Slave 服务器上执行sart slave命令开启主从复制开关,开始进行主从复制。
2) 此时,Slave服务器的IO线程会通过在master上已经授权的复制用户权限请求连接master服务器,并请求从执行binlog日志文件的指定位置(日志文件名和位置就是在配置主从复制服务时执行change master命令指定的)之后开始发送binlog日志内容
3) Master服务器接收到来自Slave服务器的IO线程的请求后,其上负责复制的IO线程会根据Slave服务器的IO线程请求的信息分批读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端的IO线程。返回的信息中除了binlog日志内容外,还有在Master服务器端记录的IO线程。返回的信息中除了binlog中的下一个指定更新位置。
4) 当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件(Mysql-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容
5) Slave服务器端的SQL线程会实时检测本地Relay Log 中IO线程新增的日志内容,然后及时把Relay LOG 文件中的内容解析成sql语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用这样sql语句,并在relay-log.info中记录当前应用中继日志的文件名和位置点.
主从复制条件
- 开启Binlog功能
- 主库要建立账号
- 从库要配置master.info (CHANGE MASTER to...相当于配置密码文件和Master的相关信息)
- start slave 开启复制功能
主从复制时需要理解
- 3个线程,主库IO,从库IO和SQL及作用
- master.info(从库)作用
- relay-log 作用
- 异步复制
- binlog作用 (如果需要级联需要开启Binlog)
主从复制时注意事项
- 主从复制是异步逻辑的SQL语句级的复制
- 复制时,主库有一个I/O线程,从库有两个线程,I/O和SQL线程
- 实现主从复制的必要条件是主库要开启记录binlog功能
- 作为复制的所有Mysql节点的server-id都不能相同
- binlog文件只记录对数据库有更改的SQL语句(来自主库内容的变更),不记录任何查询(select,show)语句
彻底解除主从复制关系
- stop slave;
- reset slave; 或直接删除master.info和relay-log.info这两个文件;
- 修改my.cnf删除主从相关配置参数。
让slave不随MySQL自动启动
| 1 |
|
主从复制实现后,使用mysqldump备份数据时,注意按照下面方式
| 1 2 |
|
需要限定同步哪些数据库,有3个思路
- 在执行grant授权的时候就限定数据库;
- 在主服务器上限定binlog_do_db = 数据库名;
- 主服务器上不限定数据库,在从服务器上限定replicate-do-db = 数据库名;
如果想实现"主-从(主)-从" 这样的链条式结构,需要设置
| 1 2 3 4 |
|
Mysql主从同步时过滤部分库或表的设置
Mysql复制过滤
让从节点仅仅复制指定的数据库,或指定数据库的指定数据表。主服务器有10个数据库,而从节点只需要同步其中的一两个数据库。这个时候就需要复制过滤。复制过滤器可以在主节点中实现,也可以在从节点中实现。Mysql主从同步部分数据有两个思路: master只发送需要的;Slave只接收想要的。
master主节点
在主节点的二进制事件日志中仅记录与指定数据库(数据表)相关的事件日志,但是主节点的二进制日志不完整,没有记录所有对主节点的修改操作。如果要使用该方式,则在主节点的配置文件中添加如下参数:
| 1 2 |
|
slave从节点
从服务器SQL Thread在Replay中继日志中的事件时仅读取于特定数据库相关的事件,并应用于本地. (但是浪费I/O ,浪费带宽) 推荐使用从节点复制过滤相关设置项:
| 1 2 3 4 5 6 7 |
|
当在主库存在的库而从库不存在的库同步时,会出现sql错误,这时候可以排除或者从库手动导入主库数据库;
从库可以使用通配符"库名.%"方式过滤主从同步时某个库的设置
| 1 2 |
|
特别注意: 生产库上一般不建议设置过滤规则, 如果非要设置, 强烈建议从库使用通配符方式过滤某个库
| 1 2 |
|
而不建议从库使用DB方式过滤某个库:
| 1 2 |
|
mysql主从/主主同步环境部署记录
1)环境描述
| 1 2 3 4 5 6 7 8 9 |
|
2)主从复制实现过程记录
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 |
|
------------------------------------------------------------------------------------------------------------------------------
注意:
Mysql主从环境部署一段时间后,发现主从不同步时,如何进行数据同步至一致?
有以下两种做法:
1)参考:mysql主从同步(2)-问题梳理 中的第(4)步的第二种方法
2)参考:mysql主从同步(3)-percona-toolkit工具(数据一致性监测、延迟监控)使用梳理
-----------------------------------------------------------------------------------------------------------------------------
3)主主复制实现过程记录
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 |
|