分布式锁-Redission
Redission 分布式锁
简介
Redission 为 Redis 官网分布式解决方案
官网: https://redisson.org/
github: https://github.com/redisson/redisson#quick-start
功能

usedBy

API

使用
org.redisson
redisson
3.10.4
// 1. Create config object
Config = ...
// 2. Create Redisson instance
RedissonClient redisson = Redisson.create(config);
// 3. Get Redis based object or service you need
RMap map = redisson.getMap("myMap");
RLock lock = redisson.getLock("myLock")
lock.lock();
//业务代码
lock.unlock(); 原理
分析
加锁机制
源码分析:
//org.redisson.RedissonLock#tryLockInnerAsync
return this.commandExecutor.evalWriteAsync(this.getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);"
, Collections.singletonList(this.getName()), new Object[]{this.internalLockLeaseTime, this.getLockName(threadId)});
为何要使用lua语言?
因为一大堆复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性
lua字段解释:
KEYS[1]代表的是你加锁的那个key,比如说:
RLock lock = redisson.getLock("myLock");
这里你自己设置了加锁的那个锁key就是“myLock”。
ARGV[1]代表的就是锁key的默认生存时间,默认30秒。
ARGV[2]代表的是加锁的客户端的ID,类似于下面这样:
8743c9c0-0795-4907-87fd-6c719a6b4586:1
第一段if判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。
如何加锁呢?很简单,用下面的命令:
hset myLock
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:
myLock:
{
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
}接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒(默认)
锁互斥机制
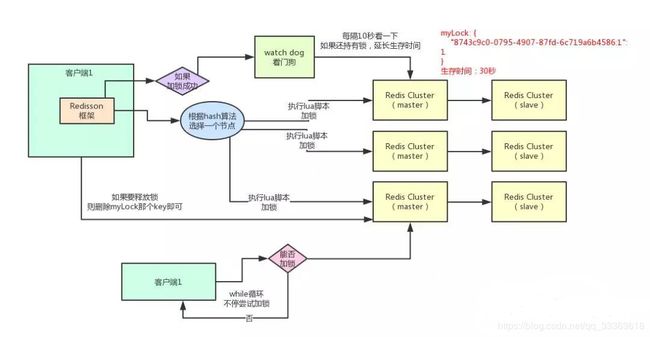
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?
很简单,第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。
此时客户端2会进入一个while循环,不停的尝试加锁。
watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
可重入加锁机制
如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?
RLock lock = redisson.getLock("myLock")
lock.lock();
//业务代码
lock.lock();
//业务代码
lock.unlock();
lock.unlock();分析上面那段lua脚本。
第一个if判断肯定不成立,“exists myLock”会显示锁key已经存在了。
第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock
8743c9c0-0795-4907-87fd-6c71a6b4586:1 1
通过这个命令,对客户端1的加锁次数,累加1。
此时myLock数据结构变为下面这样:
myLock:
{
8743c9c0-0795-4907-87fd-6c719a6b4586:1 2
}释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。
其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:
“del myLock”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
这就是所谓的分布式锁的开源Redisson框架的实现机制。
一般我们在生产系统中,可以用Redisson框架提供的这个类库来基于redis进行分布式锁的加锁与释放锁。
封装工具类
import java.util.concurrent.TimeUnit;
import com.caisebei.aspect.lock.springaspect.lock.DistributedLocker;
import org.redisson.api.RLock;
/**
* redis分布式锁帮助类
* @author caisebei
*
*/
public class RedissLockUtil {
private static DistributedLocker redissLock;
public static void setLocker(DistributedLocker locker) {
redissLock = locker;
}
/**
* 加锁
* @param lockKey
* @return
*/
public static RLock lock(String lockKey) {
return redissLock.lock(lockKey);
}
/**
* 释放锁
* @param lockKey
*/
public static void unlock(String lockKey) {
redissLock.unlock(lockKey);
}
/**
* 释放锁
* @param lock
*/
public static void unlock(RLock lock) {
redissLock.unlock(lock);
}
/**
* 带超时的锁
* @param lockKey
* @param timeout 超时时间 单位:秒
*/
public static RLock lock(String lockKey, int timeout) {
return redissLock.lock(lockKey, timeout);
}
/**
* 带超时的锁
* @param lockKey
* @param unit 时间单位
* @param timeout 超时时间
*/
public static RLock lock(String lockKey, TimeUnit unit ,int timeout) {
return redissLock.lock(lockKey, unit, timeout);
}
/**
* 尝试获取锁
* @param lockKey
* @param waitTime 最多等待时间
* @param leaseTime 上锁后自动释放锁时间
* @return
*/
public static boolean tryLock(String lockKey, int waitTime, int leaseTime) {
return redissLock.tryLock(lockKey, TimeUnit.SECONDS, waitTime, leaseTime);
}
/**
* 尝试获取锁
* @param lockKey
* @param unit 时间单位
* @param waitTime 最多等待时间
* @param leaseTime 上锁后自动释放锁时间
* @return
*/
public static boolean tryLock(String lockKey, TimeUnit unit, int waitTime, int leaseTime) {
return redissLock.tryLock(lockKey, unit, waitTime, leaseTime);
}
}
优点
支持redis单实例、redis哨兵、redis cluster、redis master-slave等各种部署架构,基于Redis 所以具有Redis 功能使用的封装,功能齐全。许多公司试用后可以用到企业级项目中,社区活跃度高。
在springboot 中单机及哨兵自动装配如下
/**
* 哨兵模式自动装配
* @return
*/
@Bean
@ConditionalOnProperty(name="redisson.master-name")
RedissonClient redissonSentinel() {
Config config = new Config();
SentinelServersConfig serverConfig = config.useSentinelServers().addSentinelAddress(redssionProperties.getSentinelAddresses())
.setMasterName(redssionProperties.getMasterName())
.setTimeout(redssionProperties.getTimeout())
.setMasterConnectionPoolSize(redssionProperties.getMasterConnectionPoolSize())
.setSlaveConnectionPoolSize(redssionProperties.getSlaveConnectionPoolSize());
if(StringUtils.isNotBlank(redssionProperties.getPassword())) {
serverConfig.setPassword(redssionProperties.getPassword());
}
return Redisson.create(config);
}
/**
* 单机模式自动装配
* @return
*/
@Bean
@ConditionalOnProperty(name="redisson.address")
RedissonClient redissonSingle() {
Config config = new Config();
SingleServerConfig serverConfig = config.useSingleServer()
.setAddress(redssionProperties.getAddress())
.setTimeout(redssionProperties.getTimeout())
.setConnectionPoolSize(redssionProperties.getConnectionPoolSize())
.setConnectionMinimumIdleSize(redssionProperties.getConnectionMinimumIdleSize());
if(StringUtils.isNotBlank(redssionProperties.getPassword())) {
serverConfig.setPassword(redssionProperties.getPassword());
}
return Redisson.create(config);
}
缺点
最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
致谢:石杉相关文章