慎用MySQL replace语句
语法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
REPLACE
[LOW_PRIORITY | DELAYED]
[
INTO
] tbl_name
[PARTITION (partition_name,...)]
[(col_name,...)]
{
VALUES
| VALUE} ({expr |
DEFAULT
},...),(...),...
Or
:
REPLACE
[LOW_PRIORITY | DELAYED]
[
INTO
] tbl_name
[PARTITION (partition_name,...)]
SET
col_name={expr |
DEFAULT
}, ...
Or
:
REPLACE
[LOW_PRIORITY | DELAYED]
[
INTO
] tbl_name
[PARTITION (partition_name,...)]
[(col_name,...)]
SELECT
...
|
原理
replace的工作机制有点像insert,只不过如果在表里如果一行有PRIMARY KEY或者UNIQUE索引,那么就会把老行删除然后插入新行。如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
root@test 03:23:55>show
create
table
lingluo\G
*************************** 1. row ***************************
Table
: lingluo
Create
Table
:
CREATE
TABLE
`lingluo` (
`a`
int
(11)
NOT
NULL
DEFAULT
'0'
,
`b`
int
(11)
DEFAULT
NULL
,
`c`
int
(11)
DEFAULT
NULL
,
`d`
int
(11)
DEFAULT
NULL
,
PRIMARY
KEY
(`a`),
--------------------------同时存在PK约束
UNIQUE
KEY
`uk_bc` (`b`,`c`)
----------------唯一索引约束
) ENGINE=InnoDB
DEFAULT
CHARSET=gbk
1 row
in
set
(0.01 sec)
root@test 02:01:44>
select
*
from
lingluo;
Empty
set
(0.00 sec)
root@test 03:27:40>
replace
into
lingluo
values
(1,10000,3,4);
--------表里没有已存在的记录相当于insert
Query OK, 1 row affected (0.00 sec)
-----------------------affect_rows是1
|
binlog格式:
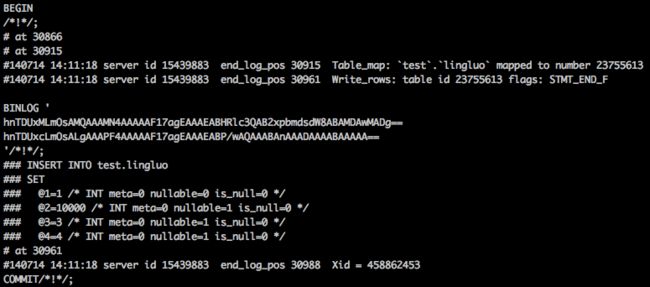
|
1
2
|
root@test 02:11:18>
replace
into
lingluo
values
(1,10000,3,5);
-------已经存在记录,且PK和UK同时冲突的时候,相当于先delete再insert
Query OK, 2
rows
affected (0.00 sec)
----------------------affect_rows是2,是delete和insert行数的总和
|
binlog格式:
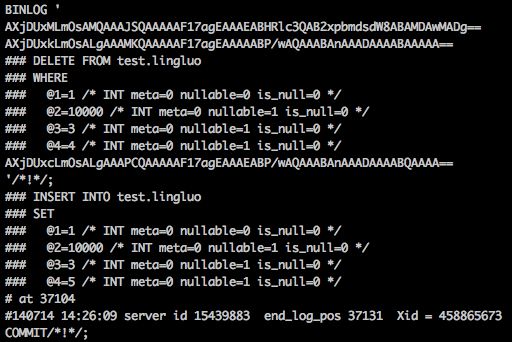
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
root@test 02:26:09>
select
*
from
lingluo;
+
---+-------+------+------+
| a | b | c | d |
+
---+-------+------+------+
| 1 | 10000 | 3 | 5 |
+
---+-------+------+------+
1 row
in
set
(0.00 sec)
root@test 02:31:54>
replace
into
lingluo
values
(1,10000,4,5);
-------已经存在记录,且PK同时冲突的时候,相当于先delete再insert
Query OK, 2
rows
affected (0.00 sec)
---------------------------------affect_rows是2,是delete和insert行数的总和
root@test 02:32:02>
select
*
from
lingluo;
+
---+-------+------+------+
| a | b | c | d |
+
---+-------+------+------+
| 1 | 10000 | 4 | 5 |
+
---+-------+------+------+
|
binlog格式:
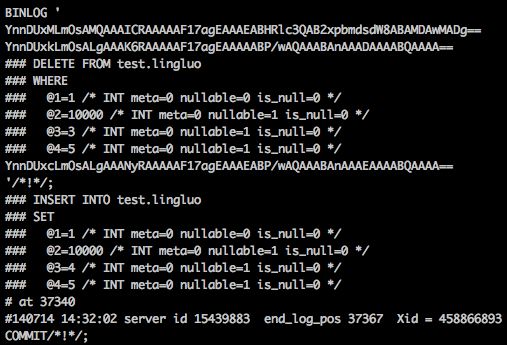
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
root@test 02:37:04>
replace
into
lingluo
values
(4,10000,6,5);
Query OK, 1 row affected (0.00 sec)
root@test 02:37:59>
replace
into
lingluo
values
(6,10000,6,5);
-------已经存在记录,且UK同时冲突的时候,直接update
Query OK, 2
rows
affected (0.00 sec)
---------------------------------affect_rows是2
root@test 02:40:31>
select
*
from
lingluo;
+
---+-------+------+------+
| a | b | c | d |
+
---+-------+------+------+
| 1 | 10000 | 4 | 5 |
| 3 | 10000 | 5 | 5 |
| 6 | 10000 | 6 | 5 |
+
---+-------+------+------+
3
rows
in
set
(0.00 sec)
|
疑问:
既然uk冲突的时候是update,那么为什么affect_rows都是2呢?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
指定列
replace
:
root@test 03:34:37>
select
*
from
u;
+
----+------+------+
| id | age | d |
+
----+------+------+
| 0 | 1 | 126 |
| 1 | 0 | 1 |
| 3 | 1 | 123 |
| 4 | 1 | 127 |
| 5 | 0 | 12 |
| 7 | 2 | 129 |
+
----+------+------+
6
rows
in
set
(0.00 sec)
root@test 03:34:37>
select
*
from
u;
+
----+------+------+
| id | age | d |
+
----+------+------+
| 0 | 1 | 126 |
| 1 | 0 | 1 |
| 3 | 1 | 123 |
| 4 | 1 | 127 |
| 5 | 0 | 12 |
| 7 | 2 | 129 |
+
----+------+------+
6
rows
in
set
(0.00 sec)
root@test 03:34:40>
replace
into
u (age,d)
values
(0,130);
Query OK, 2
rows
affected, 1 warning (0.01 sec)
root@test 03:40:39>show warnings;
+
---------+------+-----------------------------------------+
|
Level
| Code | Message |
+
---------+------+-----------------------------------------+
| Warning | 1364 | Field
'id'
doesn't have a
default
value |
+
---------+------+-----------------------------------------+
1 row
in
set
(0.00 sec)
root@test 03:40:47>
select
*
from
u;
+
----+------+------+
| id | age | d |
+
----+------+------+
| 0 | 0 | 130 |
-----------------因为id是parimary但是没有auto_creasement,由126变成130
| 1 | 0 | 1 |
| 3 | 1 | 123 |
| 4 | 1 | 127 |
| 5 | 0 | 12 |
| 7 | 2 | 129 |
+
----+------+------+
6
rows
in
set
(0.00 sec)
|
用的时候需要注意的是:
-
如果指定replace列的话,尽量写全,要不然没有输入值的列数据会被赋成默认值(因为是先delete在insert),就和普通的insert是一样的,所以如果你要执行replace语句的话是需要insert和delete权限的。
如果你需要执行
SET,就相当于执行col_name=col_name+ 1col_name= DEFAULT(col_name) + 1 -
replace语句如果不深入看的话,就和insert一样,执行完后没什么反应
例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
root@test 04:20:04>
select
*
from
u;
+
----+------+------+
| id | age | d |
+
----+------+------+
| 0 | 0 | 130 |
| 1 | 0 | 1 |
| 3 | 1 | 123 |
| 4 | 1 | 127 |
| 5 | 0 | 12 |
| 7 | 2 | 129 |
+
----+------+------+
6
rows
in
set
(0.00 sec)
root@test 04:20:10>
replace
into
u (id,d)
values
(8,232);
Query OK, 1 row affected (0.01 sec)
root@test 04:20:39>
select
*
from
u;
+
----+------+------+
| id | age | d |
+
----+------+------+
| 0 | 0 | 130 |
| 1 | 0 | 1 |
| 3 | 1 | 123 |
| 4 | 1 | 127 |
| 5 | 0 | 12 |
| 7 | 2 | 129 |
| 8 |
NULL
| 232 |
+
----+------+------+
7
rows
in
set
(0.00 sec)
root@test 04:20:43>
replace
into
u (id,d)
values
(7,232);
Query OK, 3
rows
affected (0.01 sec)
----------注意这里affect_rows是3,因为主键7已经存在,唯一索引232已经存在,所以需要删除id为7和8的行,然后插入新行
root@test 04:20:52>
select
*
from
u;
+
----+------+------+
| id | age | d |
+
----+------+------+
| 0 | 0 | 130 |
| 1 | 0 | 1 |
| 3 | 1 | 123 |
| 4 | 1 | 127 |
| 5 | 0 | 12 |
| 7 |
NULL
| 232 |
+
----+------+------+
6
rows
in
set
(0.00 sec)
root@test 04:20:55>
|
MySQL给replace和load data....replace用的算法是:
-
尝试向表里插入新行
-
当表里唯一索引或者primary key冲突的时候:
a. delete冲突行
b.往表里再次插入新行
如果遇到重复行冲突,存储过程很可能当作update执行,而不是delete+insert,但是显式上都是一样的。这里没有用户可见的影响除了存储引擎层Handler_xxx的状态变量。
因为REPLACE ... SELECT语句的结果依赖于select的行的顺序,但是顺序没办法保证都是一样的,有可能从master和slave的都不一样。正是基于这个原因,MySQL 5.6.4以后,REPLACE ... SELECT语句被标记为基于statement的复制模式不安全的。基于这个变化,当使用STATEMENT记录二进制日志的时候,如果有这样的语句就会在log里面输出一个告警,同样当使用MIXED行复制模式也会记录告警。
在MySQL5.6.6之前的版本,replace影响分区表就像MyISAM使用表级锁锁住所有的分区表一样。当使用 REPLACE ... PARTITION语句时确实会发生上述情况。(使用基于行锁的InnoDB引起不会发生这种情况。)在MySQL 5.6.6以后的版本MySQL使用分区锁,只有当分区(只要没有分区表的列更新)包含了REPLACE语句并且WHERE实际匹配到的才会锁住那个分区;否则的话就会锁住整个表。
操作形式:
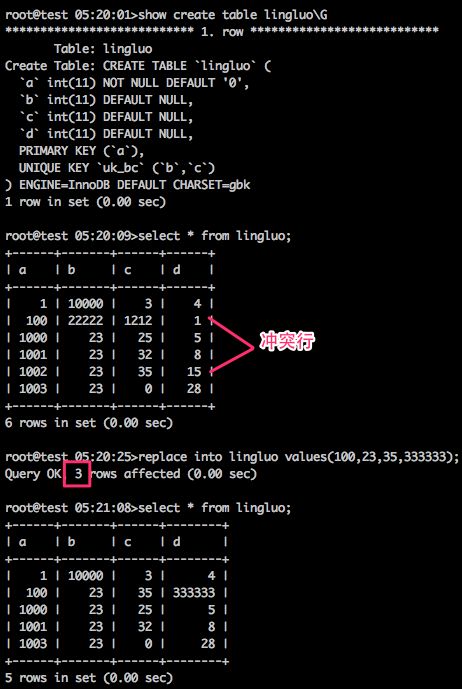
binlog格式:
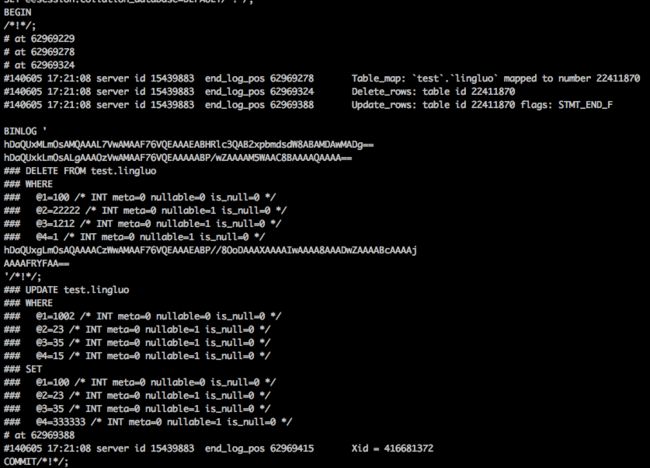
结论
-
当存在pk冲突的时候是先delete再insert
-
当存在uk冲突的时候是直接update
那了解了这个,对我们有什么用呢?
举两个例子:
1. 主备复制
主库上如上执行后,备库里如果是auto_increment是不会变的!这会有什么问题呢?把这个 slave 提升为 master 之后,由于 AUTO_INCREMENT 比实际的 next id 还要小,写入新记录时就会发生 duplicate key error,每次冲突之后 AUTO_INCREMENT += 1,直到增长为 max(id) + 1 之后才能恢复正常。
那么对于这种问题的解决办法是什么呢?@ 小强-zju 同学已经在这里给出了答案: http://bugs.mysql.com/bug.php?id=73563
2. 数据迁移
莫名其妙发现有些字段的值被覆盖
鉴于此,很多使用 REPLACE INTO 的场景,实际上需要的是 INSERT INTO … ON DUPLICATE KEY UPDATE,在正确理解 REPLACE INTO 行为和副作用的前提下,谨慎使用 REPLACE INTO。