PyInstaller打包Scrapy+PyQt5+selenium解决问题
首先,打包命令去掉所有不必要附加选项:比如 pyInstaller main.py -y
项目目录结构:
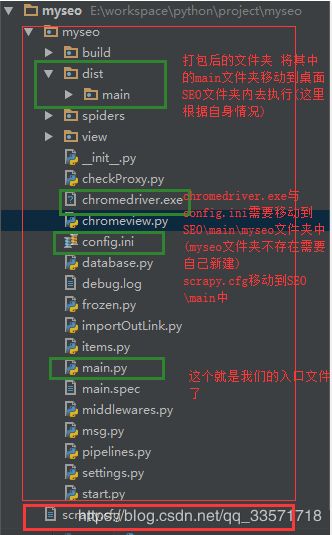
说明一下打包遇到的问题:
1.打包PyQt5缺少Qt动态库
2.Scrapy VERSION 文件不存在
3.打包Scrapy爬虫缺少各种scrapy模块(scrapy自己定义的pipelines,middlewares,settings)
4.缺少配置文件(这里我自己有定义一个config.ini的配置文件,以及chromedriver.exe)
5.scrapy 自己定义的pipelines,middlewares,settings无效
解决方法:(注意文中图片的备注)
1.添加以下代码到入口文件引入PyQt5模块的上方:
import sys, os
if hasattr(sys, 'frozen'):
os.environ['PATH'] = sys._MEIPASS + ";" + os.environ['PATH']2.在解决第一个问题后,项目中使用了scrapy爬虫的框架,所以会报一个错误;如下:
FileNotFoundError: [Errno 2] No such file or directory:'C:\\Users\\LENOVO\\Desktop\\SEO\\main\\scrapy\\VERSION'
[10816] Failed to execute script main
这里表示缺失文件C:\\Users\\LENOVO\\Desktop\\SEO\\main\\scrapy\\VERSION;
检查桌面SEO\main文件夹中是否缺少VERSION文件或缺少scrapy文件夹(一般情况下都是缺少的:缺少就先创建scrapy文件夹);
接下来我们去到Scrapy的安装目录D:\soft\Anaconda3\envs\python36\Lib\site-packages\scrapy(我这里是这个目录),将mime.types以及VERSION文件复制到桌面上SEO\main\scrapy文件夹中
3.解决上一步后,自己可以测试一下,测试后会出现缺少scrapy模块的问题,这里直接贴代码了
# 这里是必须引入的
# import robotparser
import scrapy.spiderloader
import scrapy.statscollectors
import scrapy.logformatter
import scrapy.dupefilters
import scrapy.squeues
import scrapy.extensions.spiderstate
import scrapy.extensions.corestats
import scrapy.extensions.telnet
import scrapy.extensions.logstats
import scrapy.extensions.memusage
import scrapy.extensions.memdebug
import scrapy.extensions.feedexport
import scrapy.extensions.closespider
import scrapy.extensions.debug
import scrapy.extensions.httpcache
import scrapy.extensions.statsmailer
import scrapy.extensions.throttle
import scrapy.core.scheduler
import scrapy.core.engine
import scrapy.core.scraper
import scrapy.core.spidermw
import scrapy.core.downloader
import scrapy.downloadermiddlewares.stats
import scrapy.downloadermiddlewares.httpcache
import scrapy.downloadermiddlewares.cookies
import scrapy.downloadermiddlewares.useragent
import scrapy.downloadermiddlewares.httpproxy
import scrapy.downloadermiddlewares.ajaxcrawl
import scrapy.downloadermiddlewares.chunked
import scrapy.downloadermiddlewares.decompression
import scrapy.downloadermiddlewares.defaultheaders
import scrapy.downloadermiddlewares.downloadtimeout
import scrapy.downloadermiddlewares.httpauth
import scrapy.downloadermiddlewares.httpcompression
import scrapy.downloadermiddlewares.redirect
import scrapy.downloadermiddlewares.retry
import scrapy.downloadermiddlewares.robotstxt
import scrapy.spidermiddlewares.depth
import scrapy.spidermiddlewares.httperror
import scrapy.spidermiddlewares.offsite
import scrapy.spidermiddlewares.referer
import scrapy.spidermiddlewares.urllength
import scrapy.pipelines
import scrapy.settings
import scrapy.middleware
import scrapy.core.downloader.handlers.http
import scrapy.core.downloader.contextfactory
import scrapy.core.downloader.handlers.ftp
import scrapy.core.downloader.handlers.s3
import scrapy.core.downloader.handlers.file
import scrapy.core.downloader.handlers.datauri这写代码直接添加到模块引入代码的最后即可;提一句 如果你还有用到其它模块请自行导入
4.因为程序中用到数据库,所以将数据库配置写在config.ini中;以及使用到了Chrome浏览器;所以这两个配置文件也需要复制到桌面文件夹中;
这里就不多说了,这个可以打印一下自己使用配置文件的实际路径,然后将配置文件放到相应的文件夹下面,比如config.ini 在database.py中用到,打印路径后显示的相对路径为myseo\database.py;所以,我们需要在SEO\main\中新建myseo文件夹,然后将config.ini复制到SEO\main\myseo文件夹中(这里注意,一定以你自己的路径为准)
5.如果以上4步都已经解决,你的程序应该可以正常运行起来了,但是你会发现,我们自己定义的中间件,以及数据操作都不会生效,这里是因为我们定义的爬虫规则都在settings中配置的,而在打包的时候,没有找到我们配置的settings,所以pipelines,middlewares会不生效
首先,我们将scrapy.cfg文件复制到SEO\main中。为什么复制它,因为cfg文件中指定了我们配置的settings配置文件的相对路径;内容如下:
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = myseo.settings
[deploy]
#url = http://localhost:6800/
project = myseo到这里还没完。记得在第三步时提到需要其它模块需要自己导入;所以这里就需要导入我们用到的模块,也就是我们自己定义的pipelines,middlewares;接着导入:
import myseo.settings
import myseo.middlewares
import myseo.pipelines以上5个问题,5个解决步骤到此就完了,程序启动,运行正常;如果你有遇到以上问题,可以参考我的解决方法