MongoDB on SparkSql的读取和写入操作(Python版本)
MongoDB on SparkSql的读取和写入操作(Python版本)
1.1 读取mongodb数据
python方式需要使用pyspark 或者 spark-submit的方式进行提交。
- 下面pyspark启动的方式:
1.1.1 使用pyspark启动命令行
# 本地安装的spark版本为2.3.1,如果是其他版本需要修改版本号和scala的版本号
pyspark --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1
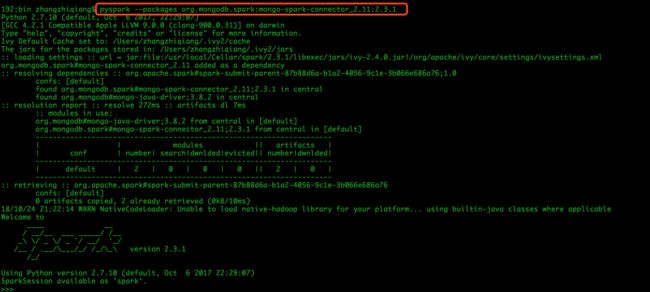
1.1.2 在pyspark shell脚本输入如下代码:
spark = SparkSession \
.builder \
.appName('MyApp') \
.config('spark.mongodb.input.uri', 'mongodb://127.0.0.1/test.user') \
.getOrCreate()
df = spark.read.format('com.mongodb.spark.sql.DefaultSource').load()
df.createOrReplaceTempView('user')
resDf = spark.sql('select name,age,sex from user')
resDf.show()
spark.stop()
exit(0)
结果输出:
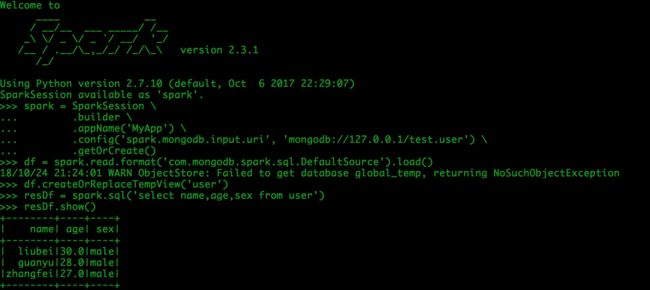
mongo中查询的结果:

- 使用spark-submit的方式启动
1.1.3 编写read_mongo.py脚本,脚本内容如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
# pyspark 的方式启动,这里我本地的spark使用的是spark 2.3.1 版本。如果是其他spark版本,mongo-spark-connector的版本号是不一样的,具体查看mongodb的官方文档
# pyspark --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1
# spark-submit的方式提交,我才用的是nohup的方式提交
# nohup spark-submit --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1 /Users/zhangzhiqiang/Documents/pythonproject/demo/mongodb-on-spark/read_mongo.py >> /Users/zhangzhiqiang/Documents/pythonproject/demo/mongodb-on-spark/read_mongo.log &
if __name__ == '__main__':
spark = SparkSession \
.builder \
.appName('MyApp') \
.config('spark.mongodb.input.uri', 'mongodb://127.0.0.1/test.user') \
.getOrCreate()
df = spark.read.format('com.mongodb.spark.sql.DefaultSource').load()
df.createOrReplaceTempView('user')
resDf = spark.sql('select name,age,sex from user')
resDf.show()
spark.stop()
exit(0)
1.1.4 使用spark-submit的方式提交
这里我采用的是nohup的方式提交,结果输出在log文件中
nohup spark-submit --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1 /Users/zhangzhiqiang/Documents/pythonproject/demo/mongodb-on-spark/read_mongo.py >> /Users/zhangzhiqiang/Documents/pythonproject/demo/mongodb-on-spark/read_mongo.log &
1.2 读取mongo数据,使用Schema约束
1.2.1 采用pyspark的方式
在命令行中编写如下代码:
# 导入包
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession \
.builder \
.appName('MyApp') \
.config('spark.mongodb.input.uri', 'mongodb://127.0.0.1/test.user') \
.getOrCreate()
# 如果mongodb中的json字段太多,我们也可以通过schema限制,过滤掉不要的数据
# name 设置为StringType
# age 设置为IntegerType
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
df = spark.read.format('com.mongodb.spark.sql.DefaultSource').schema(schema).load()
df.createOrReplaceTempView('user')
resDf = spark.sql('select * from user')
resDf.show()
spark.stop()
exit(0)
输出结果:

1.3 写入mongodb数据
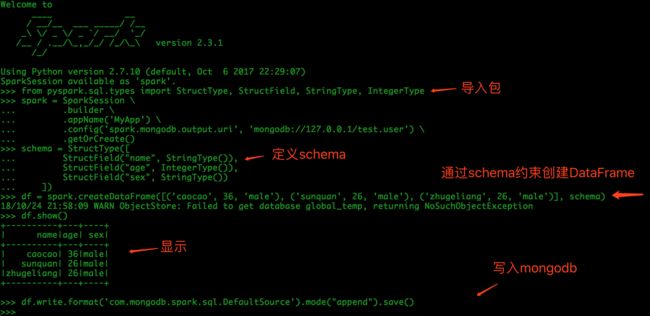
1.3.1 在pyspark中编写
# 导入包
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession \
.builder \
.appName('MyApp') \
.config('spark.mongodb.output.uri', 'mongodb://127.0.0.1/test.user') \
.getOrCreate()
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType()),
StructField("sex", StringType())
])
df = spark.createDataFrame([('caocao', 36, 'male'), ('sunquan', 26, 'male'), ('zhugeliang', 26, 'male')], schema)
df.show()
df.write.format('com.mongodb.spark.sql.DefaultSource').mode("append").save()
spark.stop()
exit(0)
结果:
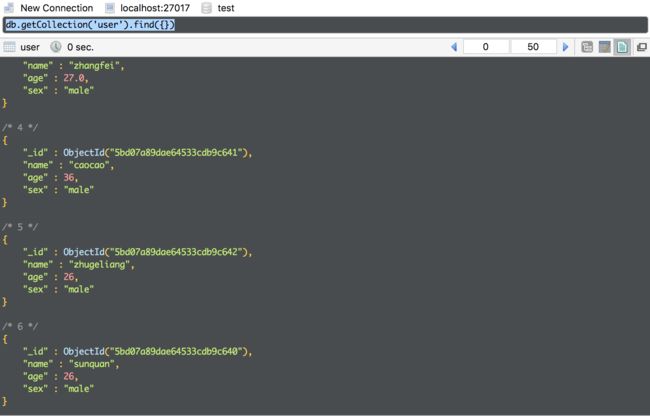
mongo中查询的结果:
这里补充一个知识点
pyspark --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1
上面使用 --package的方式可以直接在代码中通过配置写入,如下:
spark = SparkSession \
.builder \
.appName("Test") \
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/test.user") \
.config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.11:2.3.1') \
.getOrCreate()
这样便可以不通过shell启动了,还可以方便断点调试了。
github源代码示例
参考文档:
Mongo on Spark Python
How to connect to MongoDB