Python网络爬虫入门案例
一、什么是网络爬虫?
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,本质上是一段程序或脚本,可以自动化浏览网络中的信息,浏览信息时程序会按照一定的规则去浏览,这些规则我们称之为网络爬虫算法。
作用:
- 定制搜索引擎
- 自动去广告
- 爬取图片、文本
- 爬取金融信息进行投资分析
二、前置知识
- Http协议
- Html
- 正则表达式
- 一门编程语言(建议Python)
三、网络爬虫的核心步骤
- 选定爬取范围
- 分析网站结构特征
- 设计爬虫规则
- 编写爬虫脚本
四、案例 湖北师范大学“学校要闻”
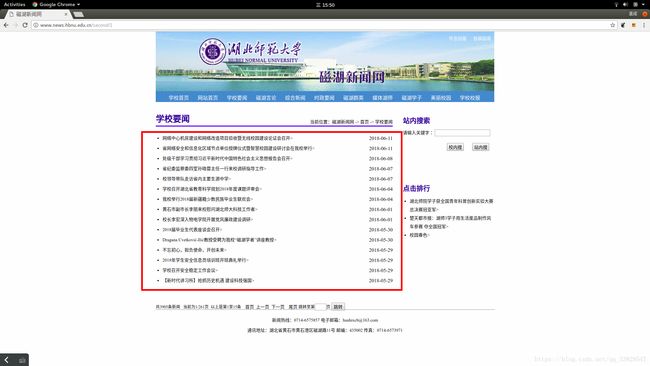
这个案例的的目标就是将上图红框所示中,学校要闻的新闻全部爬取到本地的txt文件中。案例网站链接。
好,现在已经选定了爬取范围,接下来就开始分析网站的特征结构,以及爬虫策略
按住Fn+F11调出控制台,在Element面板中查看网页的html标签结构,如下所示
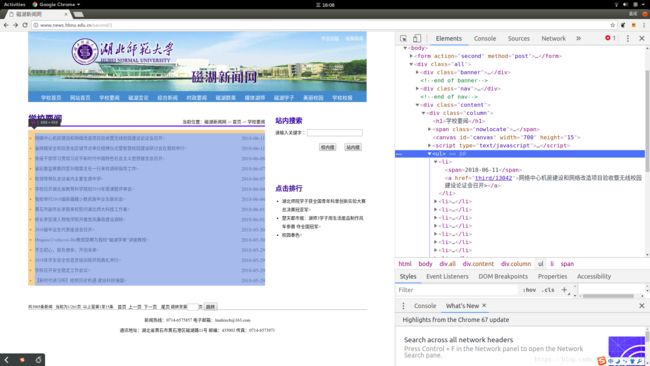
可以看到,页面主要的分为三个
- 标签,内部每个
- 标签都包含了一个标签,里面href属性中的值就是我们需要的,代表每一篇新闻页的地址。仔细观察的话还可以发现,新闻标题也在标签内部。
写到这里我们已经发现该页面的结构特征了,可以先动手写一段脚本来爬取这些内容。内容就暂时限定为新闻标题和对应的超链接,新闻内容的爬取待会再完善。
我们现在可以先写出下面的代码:
import urllib.request import re url = 'http://www.news.hbnu.edu.cn/second/1' # 构造网页的url response = urllib.request.urlopen(url) # 调用库来访问该url,获得响应 page = response.read().decode('utf-8') # 读取响应内容,并解码为utf-8,得到html文档 print('===================爬取下来网页的html文档===================') print(page) # 在控制台打印出来将完整的html # 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。 # 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体。 page = re.findall('.+?', page, re.S) page = re.findall('- .+?
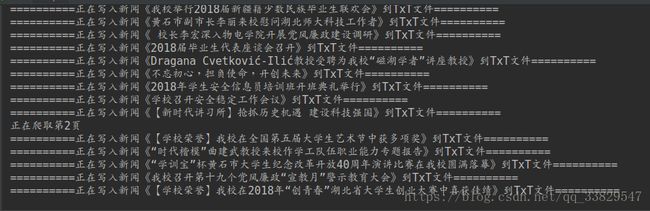
运行上述代码,可以在控制台中看到,包含新闻标题和正文超链接的标签全部被爬下来,以数组的形式存储,最后通过
for循环将数组每一项打印至控制台。如下图所示:

现在我们要做的就很清晰了,通过超链接访问新闻正文,将新闻标题和正文爬取到本地的txt文件中。继续扩展代码,使用超链接获取新闻正文页的响应,再继续分析html结构特征,爬取标题和正文内容。
代码如下:
import urllib.request import re url = 'http://www.news.hbnu.edu.cn/second/1' # 构造网页的url response = urllib.request.urlopen(url) # 调用库来访问该url,获得响应 page = response.read().decode('utf-8') # 读取响应内容,并解码为utf-8,得到html文档 # 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。 # 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体。 page = re.findall('.+?', page, re.S) page = re.findall('- .+?
(.+?)', html, re.S) title = re.findall('(.+?)
', str(title))[0] # 匹配标题内容 article = re.findall('(.+?)
', str(html)) # 匹配正文内容 content = '' # 定义存放正文内容的变量 for p in article: p = re.findall('>(.+?)<', p) # 尽量只匹配标签之间的纯文字内容 if len(p) != 0: # 去除空元素,防止下标越界 for text in p: if '<' not in text: # 跳过包含标签的元素 content += text # 再次过滤按照之前规则没法过滤掉的html元素 content = content.replace('“', '').replace('”', '').replace(' ', '') # 打印文章标题 print('==========' + title[0] + '==========') # 打印文章内容 print(content)运行上述代码,可以在控制台看到纯净的新闻标题和正文文本,如下图所示:

接下来我们要做的就是将标题和正文输出到文件中。代码修改如下:
import urllib.request import re import os url = 'http://www.news.hbnu.edu.cn/second/1' # 构造网页的url response = urllib.request.urlopen(url) # 调用库来访问该url,获得响应 page = response.read().decode('utf-8') # 读取响应内容,并解码为utf-8,得到html文档 # 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。 # 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体。 page = re.findall('.+?', page, re.S) page = re.findall('- .+?
(.+?)', html, re.S) title = re.findall('(.+?)
', str(title))[0] # 匹配标题内容 article = re.findall('(.+?)
', str(html)) # 匹配正文内容 content = '' # 定义存放正文内容的变量 for p in article: p = re.findall('>(.+?)<', p) # 尽量只匹配标签之间的纯文字内容 if len(p) != 0: # 去除空元素,防止下标越界 for text in p: if '<' not in text: # 跳过包含标签的元素 content += text # 再次过滤按照之前规则没法过滤掉的html元素 content = content.replace('“', '').replace('”', '').replace(' ', '') # 打印进度 print('==========正在写入新闻《' + title + '》到TxT文件==========') # 在源代码同目录创建名“新闻”为文件夹 existed = os.path.exists('./新闻') if not existed: os.makedirs('./新闻') # 写入内容至文件 txt = open("./新闻/" + title + ".txt", "wb") txt.write(content.encode()) txt.close()运行代码后,控制台可以看到爬虫进度:

在代码同目录可以看到生成了“新闻”文件夹,里面存放已经写入完毕的txt文件:

打开txt文件,可以看到新闻正文内容:

这么快就要大功告成了吗?好了,别忘了,这个新闻页面是可以翻页的!!!!
你可以看到这个栏目一共有261页,我们不可能针对每一个页面去写一个爬虫,这样就失去了爬虫的意义。
所以现在我们需要做另一件事,继续分析翻页行为的细节。
首先观察,在翻页过程中,发现浏览器的URL并不包含页码信息,也没有发生改变,这说明这个案例不可能通过URL实现翻页效果。
那好吧,有些难度了,继续查看控制台,切换到NetWork面板,点击翻页,查看翻页动作触发了哪些http请求内容:
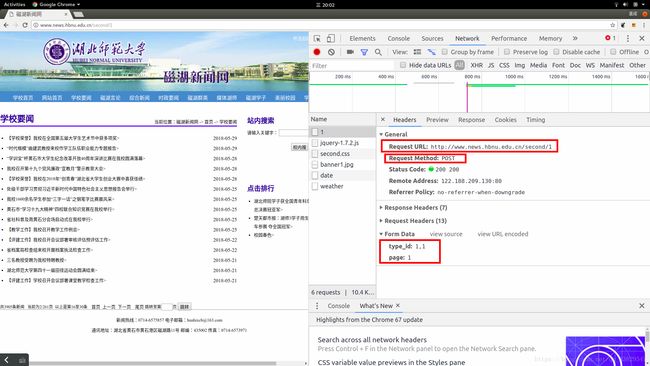
直觉得到,最可疑的就是那名字为**“1”**的请求了,点进去查看,果不其然,这是一个post请求,**请求data里面还包含了请求的页码信息。**如上图红框所示。那么我们就用Python构造个post请求来试一试,看看结果吧。
代码如下:
import requests url = 'http://www.news.hbnu.edu.cn/second/1' # 还有我们准备用Post传的值,这里值用字典的形式 values = { 'type_id': '1,2', 'page': '2' } html = requests.post(url, data=values).text # 获得新闻列表页html # 打印页面html至控制台 print(html)运行上述代码,还真得到了下一页面的html文档!而且文档结构特征和第一页完全一致!
这样就好办了,回到之前没写完的代码,继续补完利用post请求翻页的代码:
import urllib.request import urllib.parse import urllib.error import re import os import requests url = 'http://www.news.hbnu.edu.cn/second/1' # 构造网页的url index = 0 # 开始页码 while 1: # 打印当前页码 print('正在爬取第' + str(index + 1) + '页') # 还有我们准备用Post传的值,这里值用字典的形式 values = { 'type_id': '1,' + str(index), 'page': str(index) } index = index + 1 # 页码加1 page = '' # 为了避免碰上网络堵塞URLError:的异常,加上这个循环多试几次 while 1: try: page = requests.post(url, data=values).text # 获得新闻列表页html break except urllib.error.URLError as e: continue # 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。 # 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体。 page = re.findall('.+?', page, re.S) page = re.findall('- .+?
的异常,加上这个循环多试几次 while 1: try: response = urllib.request.urlopen(article_url) # 获得正文页相应 break except urllib.error.URLError as e: continue html = response.read().decode('utf-8') # 得到新闻正文页的完整html title = re.findall('(.+?)', html, re.S) title = re.findall('(.+?)
', str(title))[0] # 匹配标题内容 article = re.findall('(.+?)
', str(html)) # 匹配正文内容 content = '' # 定义存放正文内容的变量 for p in article: p = re.findall('>(.+?)<', p) # 尽量只匹配标签之间的纯文字内容 if len(p) != 0: # 去除空元素,防止下标越界 for text in p: if '<' not in text: # 跳过包含标签的元素 content += text # 再次过滤按照之前规则没法过滤掉的html元素 content = content.replace('“', '').replace('”', '').replace(' ', '') # 打印进度 print('==========正在写入新闻《' + title + '》到TxT文件==========') # 在源代码同目录创建名“新闻”为文件夹 existed = os.path.exists('./新闻') if not existed: os.makedirs('./新闻') # 写入内容至文件 txt = open("./新闻/" + title + ".txt", "wb") txt.write(content.encode()) txt.close()代码整合在一起,看起来稍微复杂,可以运行看看观看最终效果,结合代码帮助自己理解。
最终运行结果: