yolov--14--轻量级模型MobilenetV2网络结构解析--概念解读
Yolov-1-TX2上用YOLOv3训练自己数据集的流程(VOC2007-TX2-GPU)
Yolov--2--一文全面了解深度学习性能优化加速引擎---TensorRT
Yolov--3--TensorRT中yolov3性能优化加速(基于caffe)
yolov-5-目标检测:YOLOv2算法原理详解
yolov--8--Tensorflow实现YOLO v3
yolov--9--YOLO v3的剪枝优化
yolov--10--目标检测模型的参数评估指标详解、概念解析
yolov--11--YOLO v3的原版训练记录、mAP、AP、recall、precision、time等评价指标计算
yolov--12--YOLOv3的原理深度剖析和关键点讲解
yolov--13--voc的xml转json格式出现问题-Converting PASCAL VOC dataset... Index exceeds matrix dimensions- 解决方法
卷积层和池化层后输出大小计算公式
卷积后图片输出大小几个数
W:图像宽,H:图像高,D:图像深度(通道数)
F:卷积核宽高,N:卷积核(过滤器)个数
S:步长,P:用零填充个数
卷积后输出图像大小:
Width=(W-F+2P)/S+1
Height=(H-F+2P)/S+1
卷积后输出图像深度:
N=D
输出图像大小: (width,height,N)
weight个数:
F*F*D*N
bias个数:
N
总结:卷积输出大小=[(输入大小-卷积核(过滤器)大小+2*P)/步长]+1
通用的卷积时padding 的选择
如卷积核宽高为3时 padding 选择1
如卷积核宽高为5时 padding 选择2
如卷积核宽高为7时 padding 选择3
池化后图片输出大小及个数
W:图像宽,H:图像高,D:图像深度(通道数)
F:卷积核宽高,S:步长
池化后输出图像大小:
W=(W-F)/S+1
H=(H-F)/S+1
池化后输出图像深度:
N=D
总结:池化输出大小=[(输入大小-卷积核(过滤器)大小)/步长]+1
参考:
https://blog.csdn.net/ddy_sweety/article/details/79798117
多输出通道:
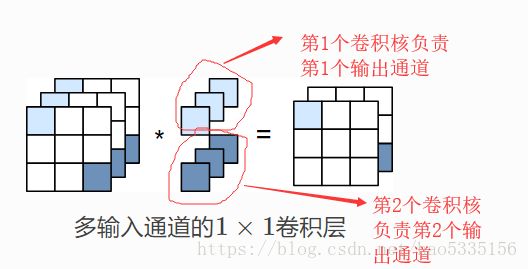
(n个输出通道需要用n个卷积核)
https://blog.csdn.net/hao5335156/article/details/80554951
在深度学习中,卷积核的个数,就是就是经过该卷积核之后的输出的通道数。
对于输入的每个通道,输出的每个通道上的卷积核是不一样的,类似于图片中的样子。
比如:
输入是28 * 28 * 192,然后经过尺寸为3 * 3,通道数为128的卷积核,那么卷积核的参数是:
3 * 3 * 192 * 128
原文链接:https://blog.csdn.net/zh_ch_yu/article/details/88383196
一种卷积核得到一个通道,所以特征图个数=输出通道数=卷积核个数。
MobilenetV2网络函数调用
# coding: utf-8
import tensorflow as tf
from model.layers import *
def MobilenetV2(input_data, training):
with tf.variable_scope('MobilenetV2'):
conv = convolutional(name='Conv', input_data=input_data, filters_shape=(3, 3, 3, 32),
training=training, downsample=True, activate=True, bn=True) #卷积核的尺寸filters_shape为:宽*高*输入通道数*输出通道数
conv = inverted_residual(name='expanded_conv', input_data=conv, input_c=32, output_c=16,
training=training, t=1)
conv = inverted_residual(name='expanded_conv_1', input_data=conv, input_c=16, output_c=24, downsample=True,
training=training)
conv = inverted_residual(name='expanded_conv_2', input_data=conv, input_c=24, output_c=24, training=training)
conv = inverted_residual(name='expanded_conv_3', input_data=conv, input_c=24, output_c=32, downsample=True,
training=training)
conv = inverted_residual(name='expanded_conv_4', input_data=conv, input_c=32, output_c=32, training=training)
feature_map_s = inverted_residual(name='expanded_conv_5', input_data=conv, input_c=32, output_c=32,
training=training)
conv = inverted_residual(name='expanded_conv_6', input_data=feature_map_s, input_c=32, output_c=64,
downsample=True, training=training)
conv = inverted_residual(name='expanded_conv_7', input_data=conv, input_c=64, output_c=64, training=training)
conv = inverted_residual(name='expanded_conv_8', input_data=conv, input_c=64, output_c=64, training=training)
conv = inverted_residual(name='expanded_conv_9', input_data=conv, input_c=64, output_c=64, training=training)
conv = inverted_residual(name='expanded_conv_10', input_data=conv, input_c=64, output_c=96, training=training)
conv = inverted_residual(name='expanded_conv_11', input_data=conv, input_c=96, output_c=96, training=training)
feature_map_m = inverted_residual(name='expanded_conv_12', input_data=conv, input_c=96, output_c=96,
training=training)
conv = inverted_residual(name='expanded_conv_13', input_data=feature_map_m, input_c=96, output_c=160,
downsample=True, training=training)
conv = inverted_residual(name='expanded_conv_14', input_data=conv, input_c=160, output_c=160, training=training)
conv = inverted_residual(name='expanded_conv_15', input_data=conv, input_c=160, output_c=160, training=training
conv = inverted_residual(name='expanded_conv_16', input_data=conv, input_c=160, output_c=320, training=training)
feature_map_l = convolutional(name='Conv_1', input_data=conv, filters_shape=(1, 1, 320, 1280),
training=training, downsample=False, activate=True, bn=True)
return feature_map_s, feature_map_m, feature_map_l