MySQL逻辑层的两层结构

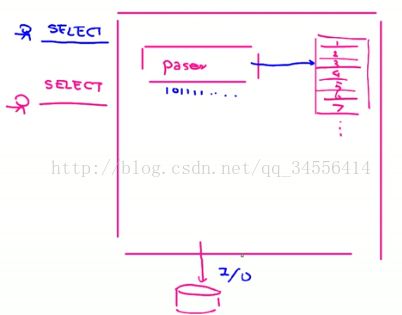
在客户端连接后,客户端会发出一些特定的查询。比如说筛选数据,插入数据,和删除数据。用的是结构化查询语句。但是这种语句最终要转化为机器可以读懂的1,0这种二进制的语句。所以在服务器上面又将刚刚执行的指令分成了两层结构进行处理。第一层结构就是SQL语句的解释器。会将SQL翻译成机器执行的代码,并且还有一个优化器,优化器就是查询的数据可以来源于内存呢还是可以来源于磁盘。
MySQL解析器由两部分组成:
1.词法分析
扫描字符流,根据构词规则识别单个单词。
MySQL使用Flex来生成词法扫描程序
在sql/lex.h中定义了MySQL关键字和函数关键字,用两个数组存储
2.语法分析
在词法分析的基础上将单词序列组成语法短语,最后生成语法树,提交给优化器
语法分析器使用Bison,在sql/sql_yacc.yy中定义了语法规则。
根据关系代数理论生成语法树
3.在sql目录下,有许多以sql_开头命名的文件,用于接受语法树,执行不同的查询,如sql_select.cc用于select查询
当用户连接进来的时候,输入一条select语句时候,首先通过SQL解释器对代码进行转换,转换之后就变为机器可以识别的二进制1,0,这种二进制流的代码。之后,如果是第一次查询,毫无疑问去硬盘上读取数据,如果查询过以后,会将查询后的数据驻留在内存当中。当再有用户连接进去查询的语句和之前的用户查询的因素相同的时候。比如说淘宝,第一个用户打开的首页和其他之后用户打开的首页看到的内容都是一样的,由于查询内容是完全。那么查询的时候就通过SQL优化器去内存拿取出来,减少磁盘的I/0。
MySQL会和其他的数据库有很大的区别,如Oracle数据库只有一种特定的存储引擎。SqlServer只有一种特定的存储引擎。但是在MySQL里面有各种各样的复杂的存储引擎。这样存储引擎是一个模块化的结构。可以筛选选择合适存储引擎存储。
不同引擎存储的方式也不同,比如说有Myisam引擎,专门做事务处理的Innodb引擎,还可以使用内存作为引擎。他们以不同的形态进行数据的保存。
使用Innodb进行存储的时候会将整个数据存储在表空间里面。
Myisam和innodb不同,会将每个表分别形成三个文件。.MYI 存放索引 .MYD存放数据 .FRM存放表结构。
上面语句解释器,下面模块化选择的引擎的两层结构。


mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |