center loss 翻译
深度人脸识别的判别特征学习方法(Center Loss)
文章目录
- 深度人脸识别的判别特征学习方法(Center Loss)
- 摘要
- 1 简介
- 2 相关工作
- 3 建议的方法
- 3.1 一个玩具的例子
- 3.2 中心损失
- 3.3 讨论
- 4 实验
- 4.1 实施细节
- 4.2 参数λ和α的实验
- 4.3 LFW和YTF数据集的实验
- 4.4 MegaFace Challenge数据集的实验
- 5 结论
- 6 致谢
- 参考
摘要
卷积神经网络(CNNs)已被广泛应用于计算机视觉领域,显着提高了现有技术水平。在大多数可用的CNN中,softmax损失函数被用作训练深度模型的监督信号。为了增强深度学习特征的判别力,本文提出了一种新的监督信号,称为中心丢失,用于人脸识别任务。具体而言,中心损失同时学习每个类别的深度特征的中心并且惩罚深度特征与其对应的类中心之间的距离。更重要的是,我们证明了所提出的中心损失函数是可训练的并且易于在CNN中进行优化。通过对softmax损失和中心损失的联合监督,我们可以训练强大的CNN,以尽可能地获得具有两个关键学习目标,课间分散和课内紧凑性的深层特征,这对于人脸识别是非常必要的。 。令人鼓舞的是,我们的CNN(通过这种联合监督)在几个重要的人脸识别基准,野外标签面(LFW),YouTube Faces(YTF)和MegaFace挑战中达到了最先进的准确性。特别是,我们的新方法在MegaFace(最大的公共领域基准测试版)下,在小型训练集(包含500000以下图像和20000人以下)的协议下取得了最佳结果,显着改善了之前的结果并设置了新的状态。 - 用于面部识别和面部验证任务
关键词:卷积神经网络,人脸识别,判别特征学习,中心损失
1 简介
卷积神经网络(CNNs)在视觉社区取得了巨大成功,显着提高了分类问题的现状,如对象[18,28,33,12,11],场景[42,41],动作[3] ,36,16]等等。 它主要受益于大规模的培训数据[8,26]和端到端的学习框架。 最常用的CNN执行特征学习和标签预测,将输入数据映射到深层特征(最后隐藏层的输出),然后映射到预测标签,如图1所示。
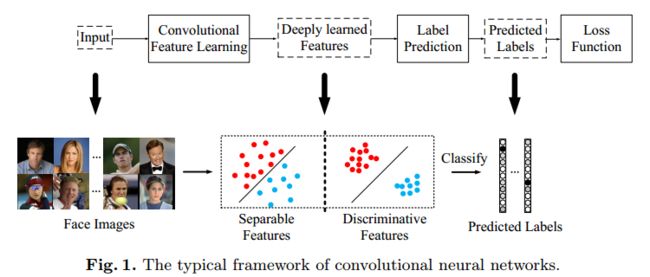
图1.卷积神经网络的典型框架。
在通用对象,场景或动作识别中,可能的测试样本的类别在训练集内,其也被称为近集识别。 因此,预测标签在性能上占主导地位,而softmax损失能够直接解决分类问题。 通过这种方式,标签预测(最后一个完全连接的层)就像一个线性分类器,并且深度学习的特征易于分离。
对于面部识别任务,深度学习的特征不仅需要分离,还需要具有辨别力。 由于预先收集用于训练的所有可能的测试身份是不切实际的,因此CNN中的标签预测并不总是适用的。 深度学习的特征需要具有辨别力和概括性,以便在没有标签预测的情况下识别新的看不见的类。 判别力表征了紧凑的类内变化和可分离的类间差异,如图1所示。判别特征可以通过最近邻(NN)[7]或k近邻(k-NN)进行良好分类。 )[9]算法,它们不一定依赖于标签预测。 然而,softmax损失仅鼓励特征的可分离性。 所得到的特征对于面部识别不是足够有效的。
为CNN中的判别特征学习构建高效的损失函数是非常重要的。 因为随机梯度下降(SGD)[19]基于小批量优化CNN,这不能很好地反映深度特征的全局分布。 由于训练集的规模庞大,在每次迭代中输入所有训练样本是不切实际的。 作为替代方法,对比度损失[10,29]和三重态损失[27]分别构建图像对和三元组的损失函数。 然而,与图像样本相比,训练对或三元组的数量急剧增加。 它不可避免地导致收敛缓慢和不稳定。 通过仔细选择图像对或三元组,可以部分地缓解该问题。 但是它显着增加了计算复杂性并且训练过程变得不方便
在本文中,我们提出了一种新的损失函数,即中心损失,以有效地增强神经网络中深度学习特征的判别力。具体来说,我们学习一个中心(一个与特征具有相同维度的向量),用于每个类的深层特征。在训练过程中,我们同时更新中心并最小化深度特征与其相应的班级中心之间的距离。 CNN在softmax损失和中心损失的联合监督下进行训练,具有超参数以平衡两个监督信号。直观地说,softmax损失迫使不同类别的深层特征保持分开。中心损失有效地将同一级别的深层特征带到了他们的中心。通过联合监督,不仅扩大了班级间的特征差异,而且减少了班级内的特征变化。因此,可以极大地增强深度学习的特征的辨别力。我们的主要贡献总结如下。
- 我们提出了一种新的损失函数(称为中心损失),以最小化深部特征的类内距离。 据我们所知,这是第一次尝试使用这种损失函数来帮助监督CNN的学习。 通过对中心损失和softmax损失的联合监督,可以获得高度辨别的特征,用于鲁棒的人脸识别,这得到了我们的实验结果的支持。
- 我们证明了所提出的损失函数在CNN中很容易实现。 我们的CNN型号可以训练,可以通过标准SGD直接优化。
- 我们在MegaFace Challenge [23](具有100万个面孔的最大公共领域人脸数据库)的数据集上进行了大量实验,并在小型训练集的评估协议下设置了新的最新技术。 我们还验证了我们在野外Labeled Faces(LFW)[15]和YouTube Faces(YTF)数据集[38]中的新方法的出色表现。
2 相关工作
通过深度学习进行人脸识别已经在这些年中取得了一系列突破[30,34,29,27,25,37]。 将一对人脸图像映射到一定距离的想法从[6]开始。 他们训练暹罗网络以推动相似性度量对于正对而言较小,对于负对则则较大。 胡等人。 [13]学习非线性变换并产生判别性深度量,在正面和负面图像对之间有一个边界。 有方法需要图像对作为输入。
最近,[34,31]通过挑战识别信号(softmax损失函数)来监督CNN中的学习过程,该信号将更丰富的身份相关信息带入深度学习的特征。 之后,[29,37]采用联合识别 - 验证监督信号,导致更多的判别特征。 [32]通过向每个卷积层添加完全连接的层和损失函数来增强监督。 [27,25,21]证明了三重态损失的有效性。 通过深嵌入,锚和正之间的距离最小化,而锚和负之间的距离最大化,直到满足边界。 它们在LFW和YTF数据集中实现了最先进的性能。
3 建议的方法
在本节中,我们将详细介绍我们的方法。我们首先使用一个玩具示例直观地显示深层学习的特性的分布。受此分布的启发,我们提出了利用中心损耗来提高深层学习特征的识别能力,并进行了一些讨论。
表1.我们在玩具示例中使用的CNN架构,称为 L e N e t s + + \mathbf{LeNets ++} LeNets++。 一些卷积层之后是最大池化。
( 5 , 32 ) / 1 , 2 × 2 (5,32)/_{1,2}×2 (5,32)/1,2×2 表示2个级联卷积层,具有32个大小为5×5的滤波器,其中步幅和填充分别为1和2。
2 / 2 , 0 2 /_{2,0} 2/2,0 表示网格为2×2的最大池化层,其中步幅和填充分别为2和0。
在 L e N e t s + + \mathbf{LeNets}++ LeNets++中,我们使用参数整流线性单元( P R e L U \mathbf{PReLU} PReLU)[12]作为非线性单元。

3.1 一个玩具的例子
在本节中,介绍了 M N I S T \mathbf{MNIST} MNIST [20]数据集上的玩具示例。 我们将 L e N e t s \mathbf{LeNets} LeNets [19]修改为更深更广的网络,但将最后一个隐藏层的输出数量减少到2(这意味着深度特征的维度为2)。 因此,我们可以直接绘制 2 D \mathbf{2D} 2D 表面上的特征以进行可视化。 表1中给出了网络架构的更多细节 s o f t m a x \mathbf{softmax} softmax 损失函数如下所示:
L s = − ∑ i = 1 m log e W y i T x i + b y i ∑ j = 1 n e w j T x i + b j L_s = - \sum^m_{i=1} \log\frac{e^{W^T_{y_i}x_i+b_{y_i}}}{\sum^n_{j=1}e^{w^T_jx_i+b_j}} Ls=−i=1∑mlog∑j=1newjTxi+bjeWyiTxi+byi
在等式1中, x i ∈ R d x_i \in \R^d xi∈Rd表示第 i i i 个深部特征,属于第 y y y 类。 d d d 是要素尺寸。 W j ∈ R d W_j \in \R^d Wj∈Rd表示最后完全连接层中权重 W ∈ R d × n W \in \R^{d×n} W∈Rd×n的第 j j j 列, b ∈ R n b \in \R^n b∈Rn 是偏置项。 小批量的大小和类的数量分别为 m m m 和 n n n 。 我们省略了简化分析的偏见。 (事实上,表现几乎没有差别)。
得到的二维深度特征绘制在图2中,以说明分布。 由于最后一个完全连接的层就像一个线性分类器,不同类的深层特征由决策边界区分。 从图2中我们可以观察到:i)在 s o f t m a x \mathbf{softmax} softmax 损失的监督下,深度学习的特征是可分离的,并且ii)深度特征没有足够的辨别力,因为它们仍然显示出显着的类内变化。 因此,不适合直接使用这些特征进行识别
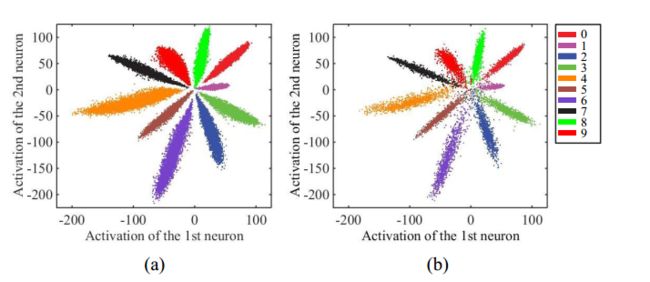
图2。深入学习的特征在(a)训练集(b)测试集中的分布,在软最大损失的监督下,我们使用50K/10K的训练/测试分割。具有不同颜色的点表示来自不同类的特征。颜色最好看。
3.2 中心损失
因此,如何开发有效的损失函数来提高深度学习特征的判别力直观地说,最小化类内变化同时保持不同类的特征可分离是关键。 为此,我们提出了中心损失函数,如公式2所示。
L c = 1 2 ∑ i = 1 m ∣ ∣ x i − c y i ∣ ∣ 2 2 L_c = \frac{1}{2} \sum^m_{i=1} ||x_i - c_{yi}||^2_2 Lc=21i=1∑m∣∣xi−cyi∣∣22
c y i ∈ R d c_{yi} \in \R^d cyi∈Rd 表示深部特征的第 y i y_i yi 类中心。 该公式有效地表征了类内变化。 理想情况下,随着深层特征的改变,应该更新 c y i c_{y_i} cyi。 换句话说,我们需要考虑整个训练集并在每次迭代中平均每个类的特征,这是低效的,甚至是不切实际的。 因此,中心损失不能直接使用。 这可能是迄今为止这种中心丢失从未在CNN中使用过的原因。
为了解决这个问题,我们进行了两次必要的修改。 首先,我们不是根据整个训练集更新中心,而是基于小批量执行更新。 在每次迭代中,通过平均相应类的特征来计算中心(在这种情况下,一些中心可能不会更新)。 其次,为了避免由少量错误标记的样本引起的大扰动,我们使用标量 α 来控制中心的学习率。 L c L_c Lc 相对于 x i x_i xi 的梯度和 c y i c_{y_i} cyi 的更新方程计算如下:
∂ L c ∂ x i = x i − c y i \frac{\partial L_c }{\partial x_i} = x_i - c_{y_i} ∂xi∂Lc=xi−cyi
Δ c j = ∑ i = 1 m δ ( y i = j ) ⋅ ( c j − x i ) 1 + ∑ i = 1 m δ ( y i = j ) \Delta c_j = \frac{\sum^m_{i=1} \delta (y_i = j )·(c_j -x_i)}{1+\sum ^m_{i=1}\delta (y_i=j)} Δcj=1+∑i=1mδ(yi=j)∑i=1mδ(yi=j)⋅(cj−xi)
其中,如果满足条件,则δ(条件)=1,如果不满足条件,则δ(条件)=0。α在 [ 0 , 1 ] [0,1] [0,1] 中受限。我们采用软最大损失和中心损失的联合监督来训练CNN进行鉴别特征学习。公式5给出。
$$
L = L_s +\lambda L_c \
= - \sum^m_{i=1} \log\frac{e{WT_{y_i}}x_i+b_{y_i}}{\sumn_{j=1}e{w^T_jx_i+b_j}} + \frac{\lambda}{2} \sum^m_{i=1} ||x_i - c_{yi}||^2_2
$$
显然,受中心损失监督的CNN是可训练的,可以通过标准 SGD 进行优化。 标量λ用于平衡两个损失函数。 如果将λ设置为0,则可以将传统的 softmax 损失视为该联合监督的特例。在算法1中,我们通过联合监督来总结CNN中的学习细节。
算法1判别特征学习算法:
输入:训练数据 { x i } \{\boldsymbol{x}_i\} {xi}。 卷积层中的初始化参数 θ C \theta _C θC。 参数 W W W 和 { c j ∣ j = 1 , 2 , ⋯ , n } \{c_j|j =1,2,\cdots,n\} {cj∣j=1,2,⋯,n} 分别在损耗层中。 超参数 λ \lambda λ, α \alpha α 和学习率 μ t \mu^t μt 。 迭代次数 t ← 0 t \leftarrow0 t←0。
输出:参数 θ C \theta_C θC。
1: 但没有收敛时,做如下操作
2: t ← t + 1 t \leftarrow t+1 t←t+1
3: 计算总损失: L t = L S t + L C t L^t = L^t_S+L^t_C Lt=LSt+LCt
4: 通过 ∂ L t ∂ x i t \frac{\partial L^t}{\partial x^t_i} ∂xit∂Lt 计算每个 i i i 的反向传播误差 $ \frac{\partial L^t}{\partial x^t_i}=\frac{\partial L^t_S}{\partial x^t_i}+\frac{\partial L^t_C}{\partial x^t_i}$
5: 通过 W t + 1 = W t − μ t ⋅ ∂ L t ∂ W t = W t − μ t ⋅ ∂ L S t ∂ W t W^{t+1}=W^t- \mu^t ·\frac{\partial L^t}{\partial W^t} = W^t-\mu^t·\frac{\partial L^t_S}{\partial W^t} Wt+1=Wt−μt⋅∂Wt∂Lt=Wt−μt⋅∂Wt∂LSt更新参数W.
6: 用 c t + 1 = c j t − α ⋅ Δ c j t c^{t+1} =c^t_j -\alpha· \Delta c^t_j ct+1=cjt−α⋅Δcjt 更新每个 j j j 的参数 c j c_j cj
7: 用 θ C t + 1 = θ C t − μ t ∑ i m ∂ L t ∂ x i t ⋅ ∂ x i t ∂ θ c t \theta^{t+1}_C = \theta^t_C -\mu^t \sum^m_i \frac{\partial L^t}{\partial x^t_i}·\frac{\partial x^t_i}{\partial \theta^t_c} θCt+1=θCt−μt∑im∂xit∂Lt⋅∂θct∂xit 更新参数 θ C \theta_C θC
8: 结束while

我们还进行了实验来说明λ如何影响分布。 图3显示不同的λ导致不同的深度特征分布。 通过适当的λ,可以显着增强深度特征的辨别力。 此外,特征在很宽的λ范围内具有辨别力。 因此,联合监督有利于深度学习特征的辨别力,这对于人脸识别至关重要。
3.3 讨论
- 联合监督的必要性。 如果我们仅使用softmax损失作为监督信号,则所得到的深度学习的特征将包含大的类内变化。 另一方面,如果我们只通过中心损失来监督CNN,那么深度学习的特征和中心将降级为零(此时,中心损失非常小)。 简单地使用它们中的任何一个都无法实现有区别的特征学习。 因此,正如我们的实验所证实的那样,有必要将它们结合起来共同监督CNN。
- 与对比损失和三重损失相比。 最近,还提出了对比度损失[29,37]和三重态损失[27],以增强深度学习的面部特征的辨别力。 然而,当构成来自训练集的样本对或样本三元组时,对比损失和三元组丢失都会遭受显着的数据扩展。 我们的中心损失与softmax损失具有相同的要求,并且不需要训练样本的复杂重组。 因此,我们对CNN的监督学习更有效且易于实施。 此外,我们的损失函数更直接地针对类内紧致性的学习目标,这对于辨别特征学习非常有益。
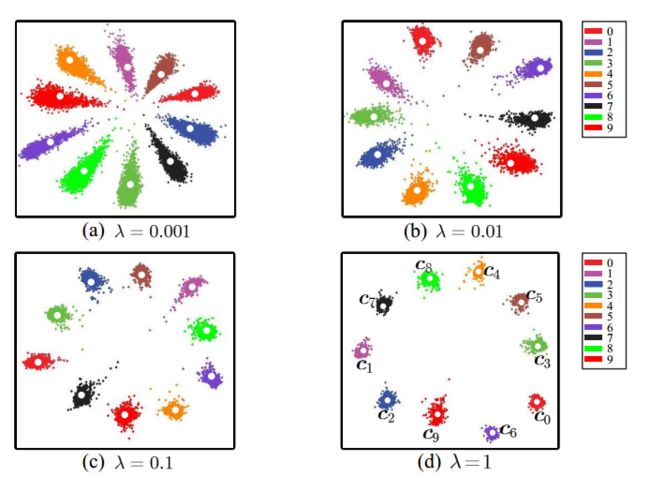
图3.在softmax损失和中心损失的联合监督下深度学习的特征的分布。 不同颜色的点表示来自不同类别的特征。 不同的λ导致不同的深度特征分布 α = 0.5 \alpha = 0.5 α=0.5。 白点 c 0 , c 1 , ⋯ , c 9 c_0,c_1,\cdots,c_9 c0,c1,⋯,c9 表示10个深级特征中心,最佳颜色。
4 实验
必要的实现细节在4.1节中给出。 然后我们研究了4.2节中参数λ和α的敏感性。 在4.3和4.4节中,对几个公共领域人脸数据集(LFW [15],YTF [38]和MegaFace Challenge [23])进行了大量实验,以验证所提方法的有效性。

图4.用于人脸识别实验的CNN架构。 采取联合监督。 卷积和局部卷积层中的滤波器大小为3×3,步长为1,其次为PReLU [12]非线性单位。 三个局部卷积层中的权重分别在4×4,2×2和1×1的区域中共享。 卷积层的特征映射数为128,本地卷积层的特征映射数为256。 最大池网格为2×2,步幅为2.第4汇集层和第3局部卷积层的输出连接为第1完全连接层的输入。 完全连接层的输出尺寸为512.最好以彩色显示。
4.1 实施细节
预处理。 图像中的所有面部及其地标都是由最近提出的算法检测出来的[40]。 我们使用5个地标(两只眼睛,鼻子和嘴角)进行相似性转换。 当检测失败时,我们只是丢弃图像(如果它在训练集中),但如果它是测试图像则使用提供的标记。 面被裁剪为112×96 RGB图像。 遵循先前的约定,RGB图像中的每个像素(在[0; 255]中)通过减去127.5然后除以128来归一化。
训练数据。 我们使用网络收集的培训数据,包括CASIAWebFace [39],CACD2000 [4],Celebrity + [22]。 在删除具有出现在测试数据集中的身份的图像之后,它大致达到17,18个独特人物的0.7M图像。 在4.4节中,我们仅使用0.49M训练数据,遵循小训练集的协议。 水平翻转图像以进行数据增强。 与[27](200M),[34](4M)和[25](2M)相比,它是一个小规模的训练集。
CNN中的详细设置。 我们使用Caffe [17]库实现了CNN模型并进行了修改。 本节中的所有CNN模型都是相同的结构,详细信息如图4所示。为了公平比较,我们分别在softmax损失(模型A),softmax损失和对比损失(模型B)的监督下训练三种模型。 ),softmax损失和中心损失(模型C)。 这些模型在两个GPU(TitanX)上以批量大小256进行训练。 对于模型A和模型C,学习速率从0.1开始,在16K,24K迭代时除以10。 完成28K迭代的完整培训,大约花费14个小时。 对于模型B,我们发现它收敛得更慢。 因此,我们将学习速率初始化为0.1,并将其切换为24K,36K迭代。 总迭代次数为42K,成本为22小时。
测试中的详细设置。 深度特征取自第一个FC层的输出。 我们为每个图像及其水平翻转的图像提取特征,并将它们连接为表示。 分数由PCA后两个特征的余弦距离计算。 最近邻居[7]和阈值比较用于识别和验证任务。 请注意,我们仅对所有测试使用单一模型
4.2 参数λ和α的实验
超参数λ支配类内变化,α控制模型C中心c的学习率。它们对我们的模型都是必不可少的。 因此,我们进行了两个实验来研究这两个参数的敏感性。
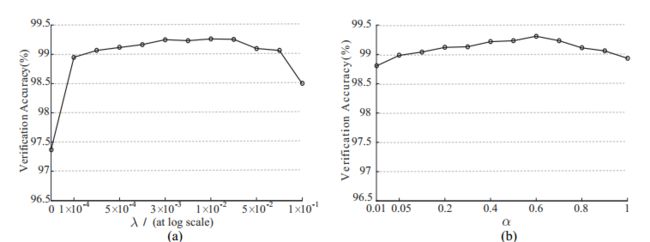
图5. LFW数据集的面验证精度分别由(a)具有不同λ和固定α= 0:5的模型实现。 (b)具有不同α和固定λ= 0:003的模型。
在第一个实验中,我们将α固定为0.5并将λ从0变为0.1以学习不同的模型。 LFW数据集上这些模型的验证精度如图5所示。很明显,简单地使用softmax损失(在这种情况下λ为0)不是一个好的选择,导致验证性能差。 正确选择λ的值可以提高深度学习的特征的验证准确性。 我们还观察到,我们模型的验证性能在很宽的λ范围内保持稳定。 在第二个实验中,我们修正λ= 0:003并将α从0.01变为1以学习不同的模型。 这些模型在LFW上的验证精度如图5所示。同样,我们模型的验证性能在很宽的α范围内基本保持稳定。

图6. LFW和YTF数据集中的一些人脸图像和视频。 绿色帧中的面部图像对是正对(同一个人),而红色帧中的面部图像对是负对。 每个图像中的白色边界框表示用于测试的面部
4.3 LFW和YTF数据集的实验
在这一部分中,我们在无约束环境中的两个着名的人脸识别基准,LFW和YTF数据集上评估我们的单一模型。 它们是图像和视频中人脸识别的优秀基准。 它们的一些例子如图6所示。我们的模型是在0.7M外部数据上训练的,没有人与LFW和YTF重叠。 在本节中,我们将λ固定为0.003,对于模型C,α为0.5。
LFW数据集包含来自5749个不同身份的13,233个网络收集的图像,在姿势,表情和照明方面有很大的变化。 遵循标准协议,不受限制的标记外部数据[14]。 我们测试了6,000个面对,并在表2中报告了实验结果。
YTF数据集包含3,425个1,595个不同的人的视频,平均每人2.15个视频。 剪辑持续时间从48帧到6,070帧不等,平均长度为181.3帧。 同样,我们遵循不受限制的标记外部数据协议,并在表2中的5,000个视频对上报告结果。
根据表2中的结果,我们得到以下观察结果。首先,模型C(由softmax损失和中心损失共同监督)击败基线1(模型A,仅由softmax损失监督),显着提高了性能(LFW为97.37%,YTF为91.1%) )至(LFW为99.28%,YTF为94.9%)。这表明联合监督可以显着提高深度学习特征的辨别力,体现中心损失的有效性。其次,与模型B(由softmax损失和对比损失的组合监督)相比,模型C实现了更好的性能(99.10%对比率99.28%和93.8%对比率94.9%)。这显示了中心损失优于设计的CNN中的对比损失的优点。最后,与两个数据库中的最新结果相比,所提出的模型C的结果(更少的训练数据和更简单的网络架构)始终位于基于这两个数据库的排名靠前的方法集中,表现优于表2中的大多数现有结果。这显示了所提出的CNN的优点。

表2. LFW和YTF数据集上不同方法的验证性能
4.4 MegaFace Challenge数据集的实验
MegaFace数据集最近作为测试基准发布。 这是一个非常具有挑战性的数据集,旨在评估数百万规模的干扰物(不在测试集中的人)的人脸识别算法的性能。 MegaFace数据集包括图库集和探针集。 画廊集包含来自690K不同个体的超过100万张图像,作为来自雅虎的Flickr照片[35]的子集。 在这次挑战中使用的探针集是两个现有的数据库:Facescrub [24]和FGNet [1]。 Facescrub数据集是公开可用的数据集,包含530个独特个体的100K照片(55,742个男性图像和52,076个女性图像)。 通过每个身份中的足够样本可以减少可能的偏差。 FGNet数据集是面部老化数据集,具有来自82个身份的1002个图像。 每个身份都有不同年龄的多个脸部图像(范围从0到69)
在两种协议(大型或小型训练集)下有几种测试场景(识别,验证和姿势不变性)。 如果训练集包含少于0.5M的图像和20K的主题,则定义为小。 按照小训练集的协议,我们将训练图像的大小减小到0.49M,但保持身份的数量不变(即17,189个对象)。 与Facescrub数据集重叠的图像将被丢弃。 为了公平比较,我们还在不同监督信号下的小训练集上训练了三种CNN模型。 得到的模型分别称为模型A-,模型B-和模型C-。 按照4.3节中的相同设置,在模型C-中λ为0.003,α为0.5。 我们使用提供的代码[23]进行实验,该代码仅在三个库(集合1)中的一个上测试我们的算法。

图7. MegaFace数据集中的一些示例面部图像,包括探针集和图库。 该画廊由至少一个正确的图像和数百万的干扰物组成。 由于每个主题和各种干扰因素的内部变化很大,识别和验证任务变得非常具有挑战性。
面部识别。 面部识别旨在将给定的探测图像与图库中具有相同人物的探测图像相匹配。 在此任务中,我们需要计算每个给定探测面图像和图库之间的相似性,其中包括至少一个与探测图像具有相同身份的图像。 此外,画廊包含不同规模的干扰物,从100万到100万,导致测试中的挑战越来越大。 更多细节可以在[23]中找到。 在面部识别实验中,我们通过累积匹配特征(CMC)曲线呈现结果。 它揭示了正确的画廊图像在top-K上排名的概率。 结果如图8所示。
面部验证。 对于面部验证,算法应该确定给定的一对图像是否是同一个人。 生成探针和图库数据集之间的40亿个负对。 我们计算真实接受率(TAR)和误接受率(FAR),并绘制图9中不同方法的接收器工作特性(ROC)曲线。
我们将我们的方法与许多现有方法进行比较,包括i)LBP [2]和JointBayes [5],ii)我们的基线深度模型(模型A-和模型B-),以及iii)其他组提交的深度模型。 从图8和图9中可以看出,手工工艺特征和浅模型表现不佳。 随着越来越多的干扰者,他们的准确性急剧下降。 此外,基于深度学习的方法比传统方法表现更好。 但是,性能改进仍有很大空间。 最后,在软最大损失和中心损失的联合监督下,模型C-实现了最佳结果,不仅超越了模型A-和模型B-,而且明显优于其他已发表的方法。
为了满足实际需求,人脸识别模型应该能够对数以百万计的干扰者实现高性能。 在这种情况下,只有至少1M干扰物的Rank-1识别率和低误接受率(例如10-6)的验证率是非常有意义的[23]。 我们报告了表3和表4中不同方法的实验结果。
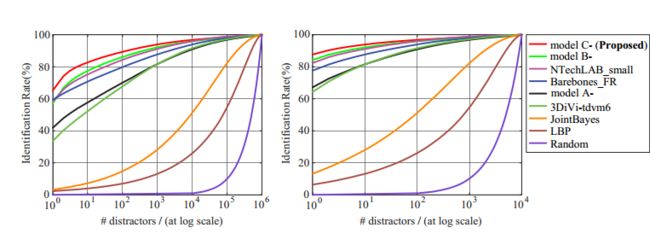
图8.不同方法(在小训练集的协议下)的CMC曲线,其中(a)1M和(b)第1组的10K干扰物。其他方法的结果由MegaFace团队提供。
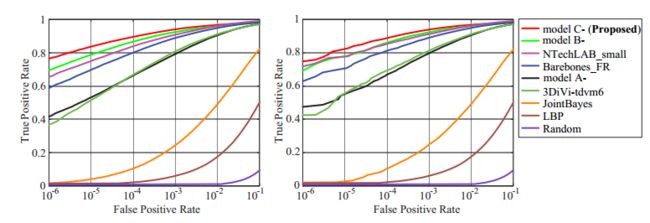
图9.不同方法(在小训练集的协议下)的ROC曲线,其中(a)1M和(b)第1组上的10K干扰物。其他方法的结果由MegaFace团队提供。
从这些结果我们得到以下观察结果。 首先,毫不奇怪,模型C-在面部识别和验证任务中始终优于模型A-和模型B-,证实了设计的损失函数的优势。 其次,在小训练集的评估协议下,所提出的模型C-在面部识别和验证任务中都取得了最好的结果,分别在面部识别和面部识别上分别优于5.97%和10.15%。 此外,值得注意的是,模型C-甚至超过了使用大型训练集训练的一些模型(例如,北京Facecall公司)。 最后,Google和NTechLAB的模型在大型训练集的协议下实现了最佳性能。 请注意,他们的私人培训集(Google为500M,NTechLAB为18M)远大于我们(0.49M)
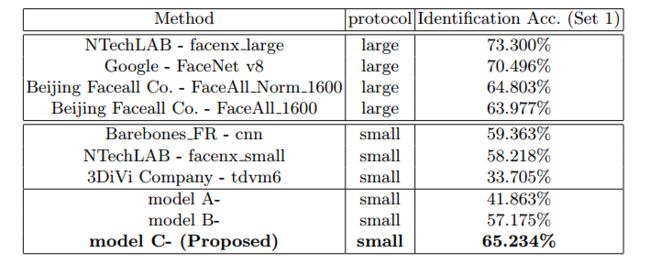
表3. MegaFace与1M干扰物的不同方法的鉴定率。
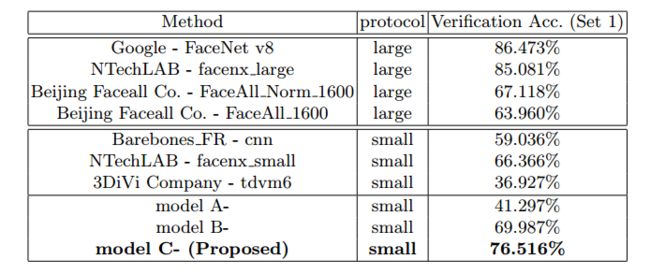
表4.使用1M干扰物的MegaFace上10-6 FAR的不同方法的验证TAR。
5 结论
在本文中,我们提出了一种新的损失函数,称为中心损失。 通过将中心损失与softmax损失相结合以共同监督CNN的学习,可以高度增强深度学习的特征的辨别力以用于鲁棒的面部识别。 对几个大规模面部基准的广泛实验已经令人信服地证明了所提出方法的有效性。
6 致谢
该项工作由中国科学院BIC对外合作项目(172644KYSB20160033,172644KYSB20150019),深圳研究计划(KQCX2015033117354153,JSGG20150925164740726,CXZZ20150930104115529和JCYJ20150925163005055),广东省研究计划(2014B050505017和2015B010129013),广东省自然科学基金( 2014A030313688)和中国科学院人体智能 - 协同系统重点实验室。
参考
-
Fg-net老化数据库。 在:http://www.fgnet.rsunit.com/(2010)
-
Ahonen,T.,Hadid,A.,Pietikainen,M。:具有局部二元模式的面部描述:面部识别的应用。 模式分析与机器智能,IEEE Transactions on 28(12),2037 {2041(2006)
-
Baccouche,M.,Mamalet,F.,Wolf,C.,Garcia,C.,Baskurt,A Sequential deep learning for human action recognition。在:人类行为理解,第29页{39。施普林格(2011年)
-
Chen,B.C.,Chen,C.S.,Hsu,W.H。:使用跨年龄参考编码与跨年龄名人数据集进行面部识别和检索。多媒体,IEEE Transactions on 17(6),804 {815(2015)
-
Chen,D.,Cao,X.,Wang,L.,Wen,F.,Sun,J。:重新审视贝叶斯面部:联合制定。在:计算机视觉{ECCV 2012,pp.566 {579。施普林格(2012)
-
Chopra,S.,Hadsell,R.,LeCun,Y。:有区别地学习相似性度量,应用于面部验证。在:计算机视觉和模式识别,2005年.CVPR 2005. IEEE计算机学会会议。第一卷。 1,pp.539 {546。 IEEE(2005)
-
封面,T.M.,Hart,P.E。:最近邻模式分类。信息理论,IEEE Transactions on 13(1),21 {27(1967)
-
Deng,J.,Dong,W.,Socher,R.,Li,L.J.,Li,K.,Fei-Fei,L。:Imagenet:一个大规模的分层图像数据库。在:计算机视觉和模式识别,2009年.CVPR 2009. IEEE会议。第248页{255。 IEEE(2009)
-
Fukunaga,K.,Narendra,P.M。:用于计算最近邻居的分支定界算法。计算机,IEEE Transactions on 100(7),750 {753(1975)
-
Hadsell,R.,Chopra,S.,LeCun,Y。:通过学习不变映射来降低维数。在:计算机视觉和模式识别,2006年IEEE计算机社会会议
上。第一卷。 2,pp.1735 {1742。 IEEE(2006) -
He,K.,Zhang,X.,Ren,S.,Sun,J。:用于图像识别的深度残差学习。 arXiv preprint arXiv:1512.03385(2015)
-
He,K.,Zhang,X.,Ren,S.,Sun,J。:深入研究整流者:超越图像网络分类的人类水平表现。在:IEEE计算机视觉国际会议论文集。第1026页{1034(2015)
-
Hu,J.,Lu,J.,Tan,Y.P。:用于野外面部验证的判别性深度量学习。在:IEEE计算机视觉和模式识别会议论文集。第1875页{1882(2014)
-
Huang,G.B.,Learned-Miller,E。:疯狂的标记面孔:更新和新的报告程序。 部门计算。 Sci。,Univ。 马萨诸塞州阿默斯特,阿默斯特,马萨诸塞州,美国,科技。 Rep pp.14 {003(2014)
-
Huang,G.B.,Ramesh,M.,Berg,T.,Learned-Miller,E。:野外标记的面孔:用于在无约束环境中研究人脸识别的数据库。技术。 代表,技术报告07-49,马萨诸塞大学阿默斯特分校(2007年)
-
Ji,S.,Xu,W.,Yang,M.,Yu,K。:用于人类行为识别的3d卷积神经网络。 模式分析与机器智能,IEEE Transactions on 35(1),221 {231(2013)
-
Jia,Y.,Shelhamer,E.,Donahue,J.,Karayev,S.,Long,J.,Girshick,R.,Guadarrama,S.,Darrell,T。:Caffe:用于快速特征嵌入的卷积结构。 在:ACM国际多媒体会议论文集。 第675页{678。 ACM(2014)
-
Krizhevsky,A.,Sutskever,I.,Hinton,G.E。:使用深度卷积神经网络的Imagenet分类。在:神经信息处理系统的进展。
第1097页{1105(2012) -
LeCun,Y.,Bottou,L.,Bengio,Y.,Haffner,P。:基于梯度的学习应用于
文件识别。 IEEE 86(11),2278 {2324(1998)的会议记录 -
LeCun,Y.,Cortes,C.,Burges,C.J。:手写数字的mnist数据库
(1998) -
Liu,J.,Deng,Y.,Huang,C。:针对最终准确性:通过面部识别
深嵌入。 arXiv preprint arXiv:1506.07310(2015) -
Liu,Z.,Luo,P.,Wang,X.,Tang,X。:在野外深刻学习面部属性。
在:IEEE计算机视觉国际会议论文集。第
3730 {3738(2015) -
Miller,D.,Kemelmacher-Shlizerman,I.,Seitz,S.M。:Megaface:A million faces for
大规模认可。 arXiv preprint arXiv:1505.02108(2015) -
Ng,H.W.,Winkler,S。:清理大型面部数据集的数据驱动方法。在:
图像处理(ICIP),2014年IEEE国际会议。第343页{347。
IEEE(2014) -
Parkhi,O.M.,Vedaldi,A.,Zisserman,A。:深层识别。诉讼程序
英国机器视觉1(3),6(2015) -
Russakovsky,O.,Deng,J.,Su,H.,Krause,J.,Satheesh,S.,Ma,S.,Huang,Z。,
Karpathy,A.,Khosla,A.,Bernstein,M.,et al。:Imagenet大规模视觉识别挑战。国际计算机视觉杂志115(3),211 {252(2015) -
Schroff,F.,Kalenichenko,D.,Philbin,J。:Facenet:统一的面部嵌入
识别和聚类。在:IEEE计算机会议论文集
视觉和模式识别。第815页{823(2015) -
Simonyan,K.,Zisserman,A。:非常深刻的大规模卷积网络
图像识别。 arXiv preprint arXiv:1409.1556(2014) -
Sun,Y.,Chen,Y.,Wang,X.,Tang,X。:通过联合进行深度学习面部表征
身份验证。在:神经信息处理系统的进展。
pp.1988 {1996(2014) -
Sun,Y。,Wang,X.,Tang,X。:面部验证的混合深度学习。在:IEEE计算机视觉国际会议论文集。第1489页{1496
(2013) -
Sun,Y.,Wang,X.,Tang,X。:从预测中深入学习面部表征
10,000班。参见:IEEE计算机视觉与会议论文集
模式识别。第1891页{1898(2014) -
Sun,Y.,Wang,X.,Tang,X。:深刻学习的面部表征是稀疏,有选择性和强大的。在:IEEE计算机视觉会议论文集
和模式识别。第2892页{2900(2015) -
Szegedy,C.,Liu,W.,Jia,Y.,Sermanet,P.,Reed,S.,Anguelov,D.,Erhan,D。,
Vanhoucke,V.,Rabinovich,A。:进一步研究卷积。在:会议录
IEEE计算机视觉和模式识别会议。第1页{9
(2015) -
Taigman,Y.,Yang,M.,Ranzato,M.,Wolf,L。:Deepface:在面部验证中弥合人类绩效的差距。在:IEEE会议论文集
计算机视觉与模式识别。 pp.1701 {1708(2014) -
Thomee,B.,Shamma,D.A.,Friedland,G.,Elizalde,B.,Ni,K.,Poland,D.,Borth,
D.,Li,L.J。:多媒体研究中的新数据和新挑战。的arXiv
preprint arXiv:1503.01817(2015) -
Wang,L.,Qiao,Y.,Tang,X。:用轨迹汇集的深卷积描述符进行动作识别。在:IEEE计算机视觉和模式识别会议论文集。第4305页{4314(2015)
-
Wen,Y.,Li,Z.,Qiao,Y。:用于年龄不变人脸识别的潜在因子引导卷积神经网络。在:IEEE计算机视觉和模式识别会议论文集。第4893页{4901(2016)
-
Wolf,L.,Hassner,T.,Maoz,I。:在具有匹配背景相似性的无约束视频中的面部识别。在:计算机视觉和模式识别(CVPR),2011年IEEE会议。第529页{534。 IEEE(2011)
-
Yi,D.,Lei,Z.,Liao,S.,Li,S.Z。:从头开始学习面部表征。 arXiv preprint arXiv:1411.7923(2014)
-
Zhang,K.,Zhang,Z.,Li,Z.,Qiao,Y。:使用多任务级联卷积网络的联合面部检测和对准。 arXiv preprint arXiv:1604.02878(2016)
-
Zhou,B.,Khosla,A.,Lapedriza,A.,Oliva,A.,Torralba,A。:物体探测器出现在深度场景中。 arXiv preprint arXiv:1412.6856(2014)
-
Zhou,B.,Lapedriza,A.,Xiao,J.,Torralba,A.,Oliva,A。:使用场所数据库学习场景识别的深层特征。在:神经信息处理系统的进展。第487页{495(2014)