翻译论文:Deep Transfer Network: Unsupervised Domain Adaptation
深度迁移网络:无监督域适应
- 摘要
- 介绍
- 深度迁移网路
- 问题定义
- 初步
- 匹配边缘分布
- 匹配条件分布
- 最终目标函数
- DTN的优化
- 优化过程
- 计算复杂度
- 实验
- 基于小规模数据集的域适应
- 基于大规模数据集的域适应
- 参数灵敏度
- 结论
摘要
域适应旨在在一个数据集中训练分类器并将其应用于相关但不相同的数据集。一成功使用域适应框架是学习转换以匹配特征的分布(边缘分布),以及给定的特征的标签分布(条件分布)。在本文中,我们提出一个名为Deep Transfer Network(DTN)的新的域适应框架,其中高度灵活的深度神经网络用于实现这种分布匹配过程。这是通过DTN中的两种类型的层实现的:共享特征提取层,它们学习共享特征子空间,其中源和目标样本的边缘分布被拉近,并且其中的判别层通过分类器转换匹配条件分布。我们还表明DTN具有线性的计算复杂度对训练样本的数量,使其适合大规模的问题。通过结合两个世界中的最佳范例(识别中的深度神经网络,以及域适应中的边缘和条件分布的匹配),我们通过大量实验证明DTN在执行时间和分类准确性方面比以前的方法有显着改善。
介绍
传统的机器学习需要大量的训练样本才能训练可靠的模型。 然而在很多现实世界的应用中,它是很昂贵的,有时甚至不可能获得足够的标记训练数据。 一个直接的解决方案是在有标签的数据集上训练模型,与目标任务相关但不相同,并应用
模型到正在考虑的数据。 不幸的是,该领域迁移的模型性能可能会急剧下降,由于不同的特征和标签分布[5]。 为了解决这个问题,域适应的目标是从一个数据集(源数据集)学习并将知识迁移到相关但不相同的数据集(目标数据集),这成为了一个活跃的研究课题[25]。 这些方法被广泛用于目标分类[1],目标检测
[6,14]单样本学习[9]等
大多数领域自适应方法的关键是学习特征变换,以减少源数据集和目标数据集之间分布的差异。有不同的情况在现实世界的问题中。1)边缘分布不同,条件分布相似。2)边缘分布相似,条件分布不同。 3)边缘分布和条件分布都是不同的[30]。
实例重加权[3,4]和子空间学习[12,11,19,27,24]是两种典型的领域适应学习策略[22]。前者通过在源样本上重新加权来减小分布差异,并在已经加权的源样本上训练分类器。后者试图找到一个共享的特征空间,其中两个数据集的分布是匹配的。还有方法同时执行实例重加权和子空间学习,并实现最先进的结果是在许多基准数据集中[22]。
分类器转换代表了另一个独立的领域适应研究线[20]。它将分布适应和模型正则化结合起来,直接设计了一种自适应分类器。 [7,23,20]一种典型的策略是在优化过程中对条件分布进行一定的正则化。例如,最小化两者间的度量,分类器的输出可以减少源和目标数据集的条件分布的差异[20],从而可以训练自适应分类器。
近年来,在许多具有挑战性的情况下,边缘分布和条件分布在不同的域之间都可能存在差异。同时将两者结合在一起能够很好地提高最终分类器的性能[30,22,20]。属于该类别的方法在基准数据集上取得了优异的性能。然而,它们中的许多都有很高的计算量(O(N2)和[20]中的O(N3)。这使得大型问题的计算成本过高。
基于神经网络的深度学习方法在机器学习和模式识别方面取得了许多令人鼓舞的成果[17]。近年来,神经网络在求解域适应中得到了成功的应用。例如情感分类[10]和行人检测[29]。然而,很少有用于解决一般域适配问题的工作通过神经网络显式匹配数据集的分布。 这种明确的匹配策略已被证明是最先进的方法[30,22,20]的关键。
在本工作中,我们提出了深度迁移网络(DTN),该网络利用深度神经网络对边缘分布和条件分布进行建模和匹配。深层神经网络和域适配的结合为我们提供了三个独特的优势。
- 神经网络结构使我们的模型适合于同时匹配边缘分布和条件分布来实现域迁移。我们通过两种不同的类型来实现这一点在DTN中:学习子空间以匹配源和目标样本的边缘分布的共享特征提取层和判别层匹配分类器转换的条件分布(第二节)。
- 与以前的工作相比,所提出的方法可以在O(n)时间内进行优化,其中n是训练数据点的数量。与其他方法([21,22]中的O(n2)和[20]中的O(n3))相比,它更适合于处理大规模域适应问题(第3节和第4节)。
- 通过将两个世界的最佳范例(识别神经网络,以及匹配域适应中的边缘分布和条件分布)结合起来,我们通过广泛的实验证明了所提出的方法在计算时间和精度上都优于目前最先进的方法.为了在大规模设置上演示我们的方法,我们在两个数据集上进行了测试,其中是广泛使用的Office-Caltech数据集的10倍。令人印象深刻的是,在USPS/MNIST数据集上,DTN的准确度提高了28.95%(第四节)。
深度迁移网路
问题定义
设x∈R(d)是d维列向量.x_s∈R(d)和x_t∈R(d)分别表示源数据集和目标数据集中的样本。y∈R是x的对应标签。 给定有标签的源数据集![]() 和无标签的目标数据集
和无标签的目标数据集![]() ,其中ns和nt是数据点的数目,领域自适应的目标是学习一个统计模型,使用所有给定的数据来最小化预测误差
,其中ns和nt是数据点的数目,领域自适应的目标是学习一个统计模型,使用所有给定的数据来最小化预测误差![]() 在目标域数据集中,其中
在目标域数据集中,其中![]() 是是模型中第i个目标数据点的预设标签。。 模型的T数据点,
是是模型中第i个目标数据点的预设标签。。 模型的T数据点,![]() 是对应的真实标签,在训练中未知。我们考虑的情况,其中源和目标数据集的边缘分布和条件分布是不同的。在本文中,P(Xs)和P(Xt)分别表示源数据集和目标数据集的边缘分布,而P(Ys|xs)和P(Yt|xt)则表示源数据集和目标数据集的条件分布。
是对应的真实标签,在训练中未知。我们考虑的情况,其中源和目标数据集的边缘分布和条件分布是不同的。在本文中,P(Xs)和P(Xt)分别表示源数据集和目标数据集的边缘分布,而P(Ys|xs)和P(Yt|xt)则表示源数据集和目标数据集的条件分布。
初步
在DTN中,采用了分布匹配策略。为了匹配这些分布,需要定义两个分布之间的差异度量。我们遵循[19]并采用经验性的最大平均偏差(MMD)为非参数度量。
由于MMD在计算和优化上的效率,是衡量两种分布差异的常用度量[26]。表示![]() 和
和![]() 分别作为Ds和DT的数据矩阵。将数据矩阵X=[xs,xt]表示为xs和xt的组合。然后将源和目标数据集的边缘分布之间的mmd定义为:
分别作为Ds和DT的数据矩阵。将数据矩阵X=[xs,xt]表示为xs和xt的组合。然后将源和目标数据集的边缘分布之间的mmd定义为:
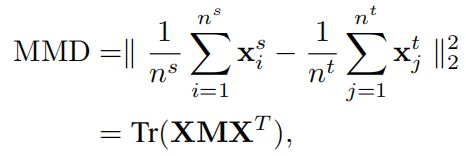 (1)
(1)
其中M是MMD矩阵。设Mij是M.Mij的一个元素,可以计算为:
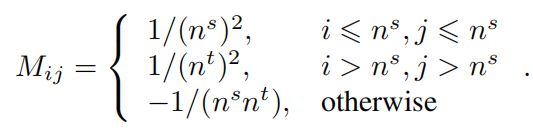 (2)
(2)
典型的神经网络由两种类型的层组成:
- 特征提取层,通过线性投影(或卷积)将输入数据投影到另一个空间,然后是一个非线性激活函数。
- 判别层,其中的最终标签预测是预先形成的。
例如,在卷积神经网络(CNNs)中,特征提取层由卷积层和全连接层组成,判别层由Softmax回归层组成。在具有L层的多层感知机(Mlps)中(如图1所示),前L-1的完全连接的层是特征提取层,而最后的Softmax回归层是判别层。在下面,我们将开发基于MLPs的DTN。我们的方法可以很容易地推广到其他类型的神经网络。
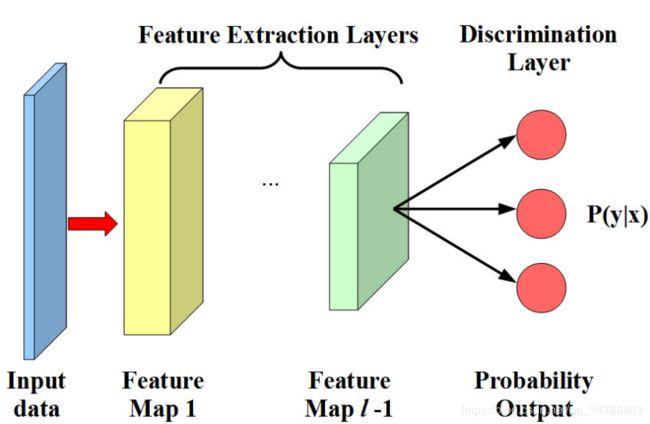
图1.具有L层的MLP示例。前L-1层是特征提取层,最后一层是判别层。
匹配边缘分布
MLP定义功能系列。我们首先考虑单层神经网络。单层神经网络通过线性投影将x映射到k维特征向量 h 以及非线性向量值激活函数f(·):
h = f(Wx), (3)
其中 W 是k×d投影矩阵。f(·)的典型选择有:![]() 和
和![]() 。该单层神经网络可以连接成一个深层神经网络,其中一个层的输出作为另一个层的输入。
。该单层神经网络可以连接成一个深层神经网络,其中一个层的输出作为另一个层的输入。
对于具有l层的MLP,前L-1层都是特征提取层。设h(L-1)是在第L-1层中x的特征。表示P(hs(L-1)和P(ht(L-1)作为源和目标数据集的特征分布。该方法的目的是使P(hs(L-1)和P(ht(L-1)接近。这是通过在训练特征映射功能时最小化mmd来实现的。
设![]() 是源数据集的特征矩阵,而ht(L-1)=
是源数据集的特征矩阵,而ht(L-1)=![]() 是目标数据集的特征矩阵。H(L-1)=[HS(L-1),Ht(L-1)]是HS(L-1)和Ht(L-1)的组合。P(hs(L-1)与P(ht(L-1)之间的距离用边缘MMD建模如下:
是目标数据集的特征矩阵。H(L-1)=[HS(L-1),Ht(L-1)]是HS(L-1)和Ht(L-1)的组合。P(hs(L-1)与P(ht(L-1)之间的距离用边缘MMD建模如下:
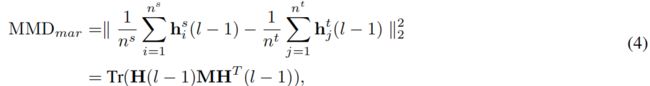
其中M是例2中定义的MMD矩阵。稍后,我们将展示如何将上述内容最小化。
匹配条件分布
本文将Logistic回归作为判别层的模型。它将输入数据点投影到一组超平面,到平面的距离反映了后验概率。假设数据集中共有C类。对于任意的C类,c类的超平面表示为Wc。y=c给定特征x的后验概率可以建模为:
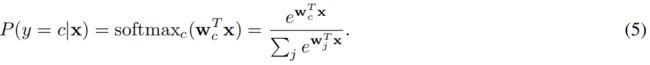
源与目标数据集之间的的条件分布距离是由有条件MMD度量的,被定义为:
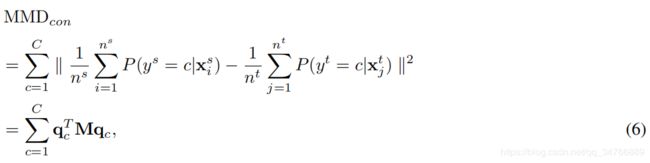
其中![]() 是C类所有数据点的后验分布输出向量,M是例2中定义的MMD矩阵。条件MMD越小,源和目标数据集的条件分布越接近。稍后,我们将展示如何将上述内容最小化。
是C类所有数据点的后验分布输出向量,M是例2中定义的MMD矩阵。条件MMD越小,源和目标数据集的条件分布越接近。稍后,我们将展示如何将上述内容最小化。
为了估计目标样本的条件分布,需要给出目标样本的标签。然而,在无监督域自适应中,目标标签是未知的。在这种情况下,我们可以使用一些基本分类器,例如SVMs、MLPs来获得目标样本的伪标签。本文采用非传递神经网络作为分类器. 我们迭代地更新目标样本的标签,以确保良好的性能(该过程在第3节中展示)。这在经验上提供了良好的性能。
最终目标函数
利用最后一个特征提取层的输出作为判别层的输入,得到DTN。特征提取层找到一个共享的子空间,在该子空间中, 源数据集和目标数据集特征的边缘分布是匹配的。然后在新的共享特征空间中训练自适应分类器以匹配条件分布。该部分给出了DTN的最终目标。
我们使用负对数似然,一个在目标函数中常用的损失函数.它的定义是:
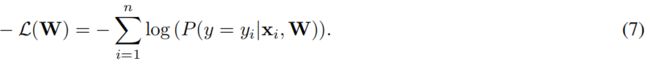
其中W是例3中神经网络的投影矩阵。通过整合等式4和6到7,得到DTN的最终目标函数:
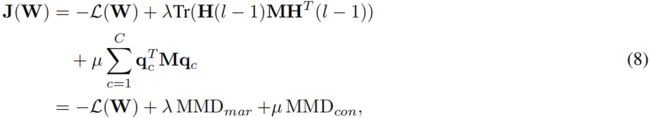
其中,λ和μ是边缘分布和条件分布的正则化参数,在第四节中将进一步讨论。然后,可以通过最小化例8来计算W。最终目标函数不依赖于损失函数的确切形式和网络的结构-人们可以很容易地将其扩展到其他类型的神经网络,如CNNs和深度置信网络(DBNs),除了MLPs之外。
DTN的优化
优化过程
我们首先介绍一些符号。对于任意训练样本x,表示该样本的最终分类器的后验(条件)概率输出为p.p∈R_C是一个C维向量。 每个维表示某一类别的后验概率。很容易证明:∇h(L-1)(MMDmar)=
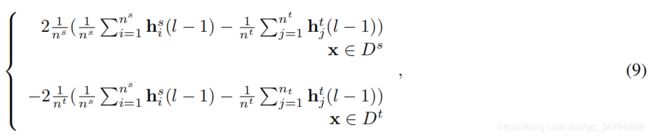
和∇p(MMDcon)=
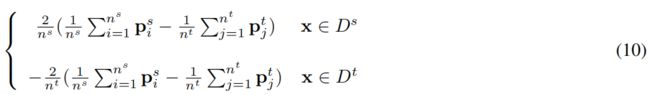
然后利用反向传播算法对神经网络进行优化。将W中的一个元素表示为Wij。例8中的Wij的偏导数。可写为:
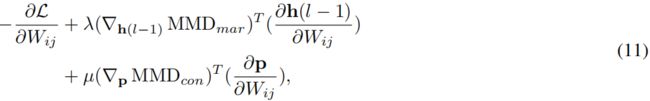
其中,∂h(L-1)/∂wij和∂ p/∂wij是由h(L-1)和p中每一个元素的偏导数组成的向量。如果给出网络的结构,它们可以很容易地计算出来。我们可以优化具有随机梯度下降的网络参数。
需要解决的一个问题是,边缘MMD或有条件MMD的计算需要考虑所有源和目标样本。这是非常低效的,特别是当训练数据集大的时候。灵感来源于小批次随机梯度下降的想法,我们将所有样本划分为不同批次。设N是我们想要构建的批数。源和目标数据集被划分为N个部分。训练批次由n(s)/N源样本和n(t)/N目标样本组成。很容易看到:
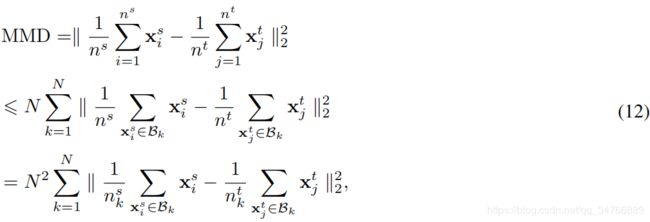
其中B是所有批次的集合,Bk是B中的第k批。![]() 是Bk中的源数据集和目标数据集的数目。因此,如果所有的小批次都匹配得很好,那么整个数据集就匹配了。我们没有计算整个数据集上的MMD,而是在每一批上计算MMD。
是Bk中的源数据集和目标数据集的数目。因此,如果所有的小批次都匹配得很好,那么整个数据集就匹配了。我们没有计算整个数据集上的MMD,而是在每一批上计算MMD。
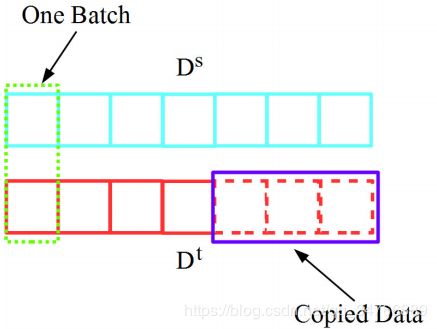
图2.构建批数据的方法。Dt中的样本被复制(虚线矩形),因此两个数据集具有相同的大小。然后随机挑选训练批次。 两个数据集的样本。

训练批次如下所示。首先,随机选择和复制较小数据集的样本,使源数据集和目标数据集具有相同的样本数。假设单个批次的大小为S,然后从源数据集中随机抽取S/2样本和从目标数据集中抽取其他S/2样本来填充批次,直到所有样本被选择为止。这个 批大小S应该足够大,以便每个小批次能够反映整个数据集的差异。第4节给出了对S的实证分析。图2说明了构建数据批次的过程。 成批的数据。最后,利用小批量梯度下降法对目标函数进行优化.
如第二节所述,非传递神经网络的输出被用作目标样本的伪标签。毫不奇怪,目标数据的标签越精确,最终分类器的性能就越好。特别是,DTN可以使用它的输出作为输入来改进自己。我们发现迭代更新目标样本的标签在训练过程中可以显着地提高DTN的性能,特别是在大规模数据集上.第四节分析了DTN算法的收敛性。算法1总结了DTN算法的最优性。
计算复杂度
设n=max(ns,nt)是较大数据集的大小,B中的批数为N,对于每个小批,计算公式的成本。9和10都是O(S),其中S是一批的大小。 当计算批上的梯度时,单个批处理中的多个样本会导致较高的计算成本。前向传播在一批上的计算复杂度也是O(S)。因为总共有N个批次和S×N=2n,DTN中整个数据集的反向传播的总计算复杂性为O(n)。与其他高阶域自适应算法不同。 例如,迁移联合匹配(O(N2)[22]和基于自适应正则化的正则最小二乘(O(N3)[20]等,DTN的执行时间随着输入样本的个数线性增长。因此,DTN适合于大规模数据集的应用.
实验
在这一部分中,我们进行了全面的实验来评估DTN的性能。除了现有文献中广泛使用的标准域适配数据集外,我们还开发了两个新的设置。 它们拥有的样本数比现有数据集多10倍。
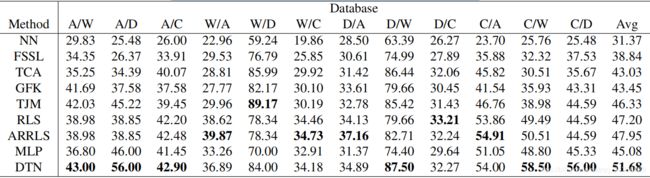
表1.Office-Caltech数据集的分类准确率(%)
基于小规模数据集的域适应
我们使用公开的Office-Caltech数据集1来评估小规模数据集上的域适配算法。Office-Caltech数据集,由龚等人首次发布。[12],由OFFICE数据集和Caltech-256数据集组成。Office数据集包含三个域:Amazon(从www.amazon.com下载的在线商家图像)、DSLR(DSLR捕获的相应商家的图像使用现实环境中的摄像机)和webcam(由摄像头拍摄的图像)。Caltech-256数据集有256个类别的30,607幅图像.四个域(Amazon(A)、WebCAM(W)、DSLR(D)和Caltech© )共享10个对象类别。在相应类别中,分别有958、295、157和1123个图像样本,共有2533幅图像。对于所有的图像,从亚马逊的一组图像中提取SURF特征并将其量化为800箱直方图,并使用代码本进行训练。数据集是评估域自适应算法的标准基准。随机 从四个域中选取两个不同的域组成源和目标数据集,我们可以有12个源/目标交叉域对,标记为A/W、A/D、A/C。…、C/D.
我们报告了所有12对的DTN结果,并与[20]和[22]中报道的方法进行了比较。这些方法包括:
- 1-最近邻分类器(NN)
- 联合特征选择与子空间学习(FSSL)[13]神经网络
- 迁移成分分析(TCA)[24]+NN。
- 测地流核(GfK)[12]NN
- 迁移联合匹配[22]NN
- 正则最小二乘(RLS)
- 基于自适应正则化的正则化最小二乘(ARRLS)[20]
- 多层感知机(MLP)
其中,NN、MLP和RLS是无知识迁移的基本分类器。FSSL、TCA、GfK、TJM是子空间学习方法,ARRLS是分类器转换方法。特别是MLP 是DTN的非传递基分类器。ARRLS是与DTN最密切相关的方法,因为它们都使用边缘MMD和条件MMD来评价分布之间的差异。 然而,其基础分类模型不同。DTN使用并行Python软件包Theano实现[2]。
我们在评价中遵循[19,22]中的相同方案。DTN的性能取决于神经网络的结构。除了神经网络的结构之外,DTN还涉及四个元参数:边缘分布匹配的正则化参数λ,条件分布匹配的正则化参数µ,批大小S-它决定了小批次的大小。 迭代次数T控制目标样本的标签在训练过程中更新多少次。对于小型数据集,在训练期间,我们只使用非转移的MLP标签。
在本实验中,我们只使用一个带一个隐层的神经网络。也就是说,基本的神经网络只有一个特征提取层和一个判别层。隐藏节点数为500。在整个数据集中,我们使用默认设置λ=µ=10。我们经验性地设定了批次大小S=200,这意味着每一小批由100个源样本和100个目标样本组成。然而,由于dslr和webcam域中的样本太少为了构建足够多的训练批,我们为所有涉及DSLR或/和webcam域的源/目标对设置了s=100。如[19,22]所述,分类精度被用作评价标准。
表1显示了DTN的Office-Caltech数据集和所有八种基线方法中所有源/目标对所获得的分类精度。。我们观察到,DTN在12个数据集中有6个数据集的性能最好和另外2个数据集上,DTN的性能仅比最佳基线方法稍差(不到分类精度的1%)。DTN的12个数据集的平均分类准确率为51.68%,比最佳基线法ARRLS提高了3.73%。与非传输基分类器MLP相比,DTN在所有12个数据集上都得到了改进,最终在平均精度上优于MLP 6.60%。这一事实证明了,同时最小化边缘分布和条件分布的MMD。 源和目标数据集可以显着地提高训练后的分类器在无标签目标数据集上的性能。
我们还注意到DTN的性能优于ARRLS。这两种方法都使用MMD来评价两个数据集之间的边缘分布和条件分布差异。唯一的区别是基本分类器,DTN使用MLP,ARRLS使用RLS。这证明了两个世界的最佳范例的结合(神经网络的识别,并匹配域自适应中的边缘分布和条件分布)工作得很好。我们还观察到,与边缘分布和条件分布(TJM、ARRLS和DTN)匹配的方法的性能总是好于只匹配边缘分布(TCA和GfK)。这是因为,在现实问题中,边缘分布和条件分布都可能在不同的领域发生变化。匹配边缘分布仅不能保证条件分布之间的小差异,源和目标域的区分方向可能仍然不同[20]。
基于大规模数据集的域适应
表2.大规模基准数据的分类准确率(%)

为了评估领域自适应算法的性能,我们开发了两种新的大规模设置,即USPS/MNIST数据集和CIFAR/VOC数据集。这两个数据集几乎是原来的10倍。 而不是当前的数据集。对于这两个设置,我们使用一个数据集作为源集,另一个作为目标集来评估我们的方法。
USPS/MNIST. USPS和MNIST数据集是两种广泛应用于分类算法评估的手写数据集。USPS数据集由10000个训练和测试图像组成,图像大小为16×16,MNIST数据集有5万幅训练图像,图像大小为28×28。我们在[19]中遵循同样的预处理过程。然而,我们使用的不是随机抽样的子集,我们使用USPS数据集中的所有训练和测试图像作为源样本,以MNIST数据集中的所有训练样本作为目标样本。因此,我们的USPS/MNIST数据集共有60000个样本。 比[19]中使用的大20倍。
CIFAR/VOC. CIFAR-10数据集4[16]是8000万张微型图像数据集的一个有标签子集。它由60000,32×32幅彩色图像组成,共10大类,每类6000幅。Pascal VOC 2012数据集5[8]是为在真实场景中识别对象而设计的。它有20个类,共有11 530幅图像。CIFAR-10和Pascal VOC 2012的一些示例图像如图3所示。CIFAR-10数据集由非常小的图像组成,而Pascal VOC 2012中的图像看起来像从互联网上获取的图像。它们遵循非常不同的分布。CIFAR-10数据集和Pascal VOC 2012 数据集共有6个语义范畴:“飞机/飞机”、“鸟”、“车”、“猫”、“狗”和“马”。因此,我们从CIFAR-10数据集中随机抽取15,000幅图像(每类2,500幅),构建CIFAR/VOC数据集,形成源数据集,并选择Pascal VOC 2012数据中的所有样本。 设置为形成目标数据集。对于所有17720个图像样本,提取DeCAF特征[15]。我们使用第6层的输出,这将导致4096维特征。
将卷积神经网络(CNN)应用于USPS/MNIST数据集,作为基本分类器。CNN是以LeNet模型为基础的,这个模型是在[18]中首次提出的。它有两个卷积和最大池化层基于过滤器尺寸为3×3和一个有500个节点的全连接层。将具有3个隐藏层的多层感知器用作CIFAR/VOC数据集的基本分类器。每个隐藏层的节点数分别是2000,1 000和500。对于参数设置,我们还设置了分布调节参数。为默认设置λ=µ=10。minst/usps的小批次大小S设置为4000,这意味着一个小批量由2,000个源样本和2,000个目标样本组成。.对于CIFAR/VOC,S=2,000。迭代次数T被设置为20,这意味着目标样本的标签在训练期间重复更新20次。

图3.CIFAR/VOC数据集中的示例图像。
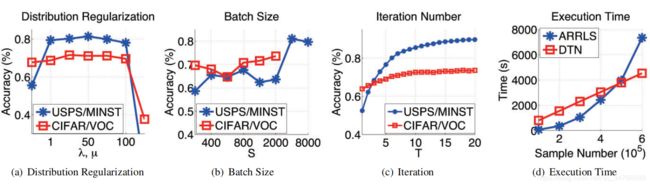
图4.USPS/MNIST和CIFAR/VOC数据集的参数分析和不同大小USPS/MNIST
数据集的执行时间。
表3.大规模基准数据集的执行时间
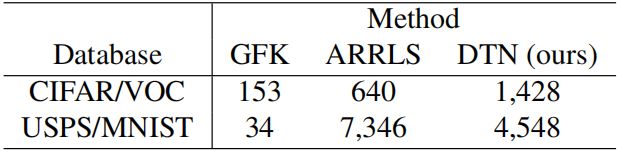
表2显示了DTN和一些基线方法的结果。观察到DTN对USPS/MNIST和CIFAR/VOC数据集的分类准确率分别为81.04%和73.60%。与非传递基分类器神经网络相比,它实现了分别为36.57%和14.56%的改进.最优的基线方法是ARRLS,准确率分别为52.09%和71.73%,它的非传递基分类器RLS提高了35.52%和9.3%。与最佳基线法(ARRLS)相比,DTN提高了28.95%和1.87%。我们观察到DTN的性能明显优于USPS/MNIST数据集上的其他基线方法。这是因为它的基本分类器CNN在数字识别方面的卓越性能。
表3显示了在大规模数据集中运行的一些算法的执行时间。与具有最佳性能的基线方法(ARRLS)相比,DTN具有竞争性的速度。为了直接显示计算复杂度,我们随机抽取不同大小的USPS/MNIST样本,从10,000到60,000,并在图4(D)中绘制DTN和ARRLS的执行时间。结果表明,DTN的执行时间与训练样本数几乎成线性关系,但ARRLS的增长要快得多。这里还应该指出,ARRLS需要超过100 GB的内存来保存内核矩阵。 然而小于3GB的视频内存足以满足DTN的需要。实验结果表明,DTN能够处理具有良好传输性能的超大规模数据集。
参数灵敏度
我们在USPS/MNIST和CIFAR/VOC数据集上进行了参数敏感性实验。预估了分布匹配参数λ、µ、最小批数S的大小和迭代次数T.
分布正则化参数λ, μ. λ控制边缘分布匹配的水平,μ控制条件分布匹配的水平。值越大,分布的差异就越小。为了简化,我们设置了λ=μ。图4(A)显示了来自{0、1、5、10、50、100、500}的不同值的分类精度。我们注意到λ且可以从[1100]中选择。在整个实验部分,我们选择λ=μ=10作为默认值。
批量S 小批量是评价数据库分布和优化目标函数的基本单元。尺寸S应该足够大,以便在批次中包含足够多的样本。 它能反映整个数据集的分布情况。图4(B)显示了来自{200、400、600、800、1000、2000、4000、8000}的不同值的分类精度。我们注意到越大的批处理总是会带来更好的性能。对于大规模数据集,S可以从[2000,8000]中选择.另一方面,由于GPU内存有限,批处理的大小不应太大。 (CIFAR/VOC批量大小分别为4,000和8,000的实验由于视频内存不足而失败)。最后,我们选择S=4,000作为USPS/MNIST,S=2,000用于CIFAR/VOC。
迭代次数T. DTN可以使用它的输出作为输入,或者提高性能。T决定了在训练期间更新目标数据集的标签的次数。图4( c)随着迭代次数的增加,分类精度稳步提高,最终收敛(每4次迭代绘制USPS/MNIST分类精度图)。最后,我们选择 T=20用于大规模数据集的实验。无监督的DTN也可以很容易地扩展到半监督的版本.目标数据集中有标签的样本总是可以提供更好的目标数据分布的估计。
结论
我们提出了深度迁移网络(DTN),它结合了目标识别(神经网络)和域自适应(同时匹配边缘分布和条件分布)的最佳范例。神经网络的结构对匹配分布的过程进行了有效的建模和优化。
DTN具有计算复杂度O(N),使其适用于大规模域适应问题。综合实验表明,DTN对各种基准数据集都是有效的。 它的性能明显优于竞争方法,特别是在大规模问题上.