java基础巩固,中级篇(集合)
本博客仅用于自己学习跟分享给大家参考而已
其实数组是有局限性,比如 声明长度是10的数组,不用的数组就浪费了,超过10的个数,又放不下。所以集合就出来了。
为了解决数组的局限性,引入容器类的概念。 最常见的容器类就是 ArrayList ,容器的容量"capacity"会随着对象的增加,自动增长
capacity的初始容量是10,但是也有说是0的,我也没有去做深入研究。
ArrayList
ArrayList的常用方法有,add(增加),contains(是否存在),get(获取指定位置的对象),indexOf(获取对象存在的位置),
remove(删除),set(替换),size(大小),toArray(转为数组),addAll(把另一个容器所有对象都加进来),clear(清空)。底层是有序数组。
LinkedList
和ArrayList相似的还有一个LinkedList ,与ArrayList一样,LinkedList也实现了List接口,诸如add,remove,contains等等方法
除了实现了List接口外,LinkedList还实现了双向链表结构Deque,可以很方便的在头尾插入删除数据。
LinkedList 除了实现了List和Deque外,还实现了Queue接口(队列)。
Queue是先进先出队列 FIFO(还有一个队列是FILO,先进后出),常用方法:
offer 在最后添加元素
poll 取出第一个元素
peek 查看第一个元素
与FIFO(先入先出的)队列类似的一种数据结构是FILO先入后出栈Stack
根据接口Stack :实现类:MyStack
List
ArrayList实现了接口List,常见的写法会把引用声明为接口List类型,注意:是java.util.List,而不是java.awt.List
//常见的写法会把引用声明为接口List类型
//注意:是java.util.List,而不是java.awt.List
//接口引用指向子类对象(多态)
List a = new ArrayList();
集合的遍历
for,iterator(迭代器),for:(增强for循环)
HashMap
HashMap储存数据的方式是—— 键值对,键不能重复,值可以重复,对于HashMap而言,key是唯一的,不可以重复的。 所以,以相同的key 把不同的value插入到 Map中会导致旧元素被覆盖,只留下最后插入的元素。 不过,同一个对象可以作为值插入到map中,只要对应的key不一样。HashMap的性能由负载因子影响,负载因子是0.75,HashMap有一个初始容量大小,默认是16,为了减少冲突概率,当HashMap的数组长度达到一个临界值就会触发扩容,把所有元素rehash再放回容器中,这是一个非常耗时的操作。而这个临界值由负载因子和当前的容量大小来决定,HashMap的扩容是*2的 初始16扩容就是32了,java8中对HashMap做了优化,这里就不详细讲了。
HashSet
Set中的元素,不能重复Set中的元素,没有顺序。 严格的说,是没有按照元素的插入顺序排列,HashSet的具体顺序,既不是按照插入顺序,也不是按照hashcode的顺序,Set不提供get()来获取指定位置的元素 ,所以遍历需要用到迭代器,或者增强型for循环。
HashSet和HashMap的关系
通过观察HashSet的源代码可以发现HashSet自身并没有独立的实现,而是在里面封装了一个Map,HashSet是作为Map的key而存在的,而value是一个命名为PRESENT的static的Object对象,因为是一个类属性,所以只会有一个。
Collection
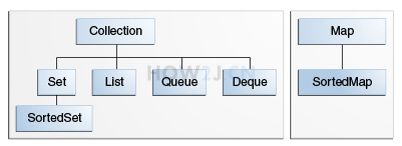
Collection是一个接口,Collection是 Set List Queue和 Deque的接口,Queue: 先进先出队列,Deque: 双向链表,Collection和Map之间没有关系,Collection是放一个一个对象的,Map 是放键值对的,Deque 继承 Queue,间接的继承了 Collection
Collections
Collections是一个类,容器的工具类,就如同Arrays是数组的工具类,常用的方法是reverse(反转),shuffle(混淆,打乱),
sort(排序),swap(交互),rotate(滚动),synchronizedList(线程安全化)。
ArrayList vs HashSet
ArrayList: 有顺序
HashSet: 无顺序
HashSet的具体顺序,既不是按照插入顺序,也不是按照hashcode的顺序
List中的数据可以重复
Set中的数据不能够重复
重复判断标准是:
首先看hashcode是否相同
如果hashcode不同,则认为是不同数据
如果hashcode相同,再比较equals,如果equals相同,则是相同数据,否则是不同数据
ArrayList vs LinkedList
ArrayList 插入,删除数据慢
LinkedList, 插入,删除数据快
ArrayList是顺序结构,所以定位很快,指哪找哪。 就像电影院位置一样,有了电影票,一下就找到位置了。
LinkedList 是链表结构,就像手里的一串佛珠,要找出第99个佛珠,必须得一个一个的数过去,所以定位慢
HashMap和HashTable
HashMap和Hashtable都实现了Map接口,都是键值对保存数据的方式
区别1:
HashMap可以存放 null
Hashtable不能存放null
区别2:
HashMap不是线程安全的类
Hashtable是线程安全的类
HashSet LinkedHashSet TreeSet
HashSet: 无序
LinkedHashSet: 按照插入顺序
TreeSet: 从小到大排序
HashCode原理
所有的对象,都有一个对应的hashcode(散列值)
Hashcode就是通过hash函数得来的,通俗的说,就是通过某一种算法得到的,hashcode就是在hash表中有对应的位置
HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的
如果两个对象equals相等,那么这两个对象的HashCode一定也相同
如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置