kafka消费慢的的一次排错过程
环境:centos6.5,cdh5.7.1,kafka 0.9.0.1。
我们的topic有12个partitions分布在12个broker,副本数3。用的old higth level API。分别在12台机器上启动消费者,每个都是单线程,所以就是一个consumer消费一个partition。但是呢,消费就是有积压。
解决:嗯,1消费者拉取数据2处理3数据流向下个目的地。一个一个确定是哪个环节出问题了。
由于我刚进公司两个礼拜。对整个集群还不是太了解。所以第一想到的就是去看看这1(几)一个topic
cd到kafka bin目录下,执行 kafka-topics.sh --zookeeper xxxx:2181,xxxx:2181.. --describe --topic topicName。如果你的kafka集群环境没问题,应该看到如下情景
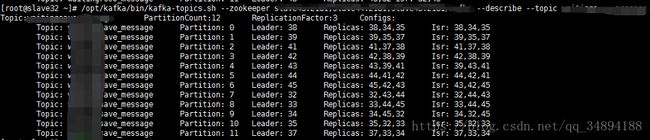
描述topic,partitionCount:12,12个partition ;ReplicationFactor:3,configs:默认
第一列 topic名字,第二列partition编号0~11,第三列副本应该在的位置,第四列已经同步的副本列表。而且leader均匀分布
这个是正常的,比如0号parititon的副本应该在38,34,35上,同步列表中显示副本确实在38,34,35中同步了(follwer复制成功且通知leader).
但是我最开始显示的却不是这样,第四列isr,只有2个partition显示3台机器,剩下的只有两个或者一个,这.....
查看每台broker的进程,嗯,kafka进程都在,那再看一下其他topic,发现isr与Replication都不一致。emmm这肯定是一个严重的问题,但是不确定和消费慢有没有关系,可能是io慢,导致消息不能及时复制。
把上图中的内容复制到atom.分析,发现isr中没有的全部集中在4台机器,而这4台机器上也没有任何leader,甚至有的topic的partition 显示-1.原因是这个partition的leader和follwer刚好都在这4台机器上,机器出问题,选不出leader.
拿出上面4台机器,机器本身没问题。干脆重启一下kafka吧,但是呢,执行stop-server.sh没反应。kill-9,然后在启动。继续去看topic情况,正常了!!!,isr副本数正常,原先partition显示-1的现在也正常显示leader所在的机器。
但是,经过之前的波折,leader分布不均匀了。去kafka官网:http://kafka.apache.org/090/documentation.html#operations
此项操作项里Balancing leadership,点进去看完发现一个功能强大的命令
kafka-reassign-partitions.sh --zookeeper xxx.2181.. --reassignment-json-file ./xxx.json --execute
这个命令可以在kafka不停止的情况下,移动分区和修改副本数。
我的xxx.json是这样的
{"partitions":
[{"topic": "xx", "partition": 0,"replicas": [32,33]},
{"topic": "xx", "partition": 1,"replicas": [33,34] },
{"topic": "xx", "partition": 2,"replicas": [34,35] },
{"topic": "xx", "partition": 3,"replicas": [35,37] },
{"topic": "xx", "partition": 4,"replicas": [37,38] },
{"topic": "xx", "partition": 5,"replicas": [38,39] },
{"topic": "xx", "partition": 6,"replicas": [39,41] },
{"topic": "xx", "partition": 7,"replicas": [41,42] },
{"topic": "xx", "partition": 8,"replicas": [42,43] },
{"topic": "xx", "partition": 9,"replicas": [43,44] },
{"topic": "xx", "partition": 10,"replicas": [44,45] },
{"topic": "xx", "partition": 11,"replicas": [45,32] }],
"version":1
}
执行完上面的语句之后,应该会显示两个东西,一个是topic原先的分布情况,一个是程序运行成功,及之后的topic分布情况。
别急,虽然报successfuly ,并不是说明重新分成功了。把之前的命令最后execute换成verify验证一下,

这种就是成功了,如果你立即执行这个语句,可能有的partition会显示 in progress,这是说,数据还在分配中,视数据量等待的时间也不同,不过不会对消费有很大的影响。像我们有个topic每条的数据量都在5M以上,就等了一个小时才跑完。
也有情况是会报有的partition failed,那应该是目的机器的kakfa进程有问题。
然后观察了一晚,发现消费者速度正常了。应该就是有4台kafka 挂掉的原因,但是进程却在,原因以后有时间再研究吧。