Kubernetes基础概念
1.Kubernetes架构
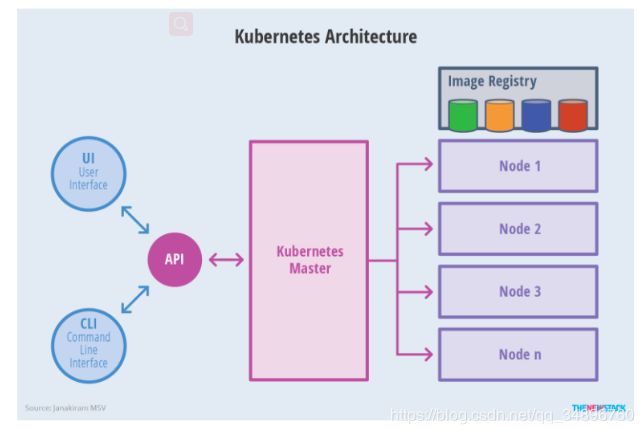
Kubernetes借鉴了Borg的设计理念,比如Pod、Service、Labels和单Pod单IP等。Kubernetes的整体架构跟Borg非常像,如下图所示

Kubernetes主要由以下几个核心组件组成:
etcd保存了整个集群的状态;
apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
kubelet负责维护容器的生命周期,同时也负责Volume(CSI)和网络(CNI)的管理;
Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的Add-ons:
kube-dns负责为整个集群提供DNS服务
Ingress Controller为服务提供外网入口
Heapster提供资源监控
Dashboard提供GUI
Federation提供跨可用区的集群
Kubernetes架构示意图

下面是更抽象的一个视图:
kubernetes整体架构示意图
Master架构

Node架构


K8S基础概念
概念详情www.jimmysong.io/kubernetes-handbook
1.Pod
Pod是kubernetes中你可以创建和部署的最小也是最简的单位。一个Pod代表着集群中运行的一个进程,每个pod都有一个根容器。
Pod中封装着应用的容器(有的情况下是好几个容器),存储、独立的网络IP,管理容器如何运行的策略选项。Pod代表着部署的一个单位:kubernetes中应用的一个实例,可能由一个或者多个容器组合在一起共享资源。
在Kubrenetes集群中Pod有如下两种使用方式:
- 一个Pod中运行一个容器。“每个Pod中一个容器”的模式是最常见的用法;在这种使用方式中,你可以把Pod想象成是单个容器的封装,kuberentes管理的是Pod而不是直接管理容器。
- 在一个Pod中同时运行多个容器。一个Pod中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以互相协作成为一个service单位——一个容器共享文件,另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
在pod中设置资源限制的时候是以千分单位算的,单位是m,比如设置100m就是代表cpu的使用为总CPU的0.1,没错单位为Mi,比如设置100Mi代表申请100M的内存
在kubernetes计算资源进行配额限定需要设定以下两个参数
requests:该资源的最小申请量,系统必须满足要求
limits:该资源最大的使用量,不能被突破,当容器试图使用超过这个量的资源时,可能会被kubernetes Kill并重启。

在使用实例中,redis和php如果为紧耦合,那么应该组合成一个整体对外提供服务,就将这两个容器打包为一个POD

2.master,Node
master指的是集群的控制节点,每个kubernetes都需要有一个master节点来负责整个集群的管理和控制,基本上整个集群的所以控制命令都有master负责执行的,master一旦宕机,整个集群将不可用。
master节点上运行着一下服务
kubernetes api server提供HTTP rest接口的关机服务,是所以服务增删改查的操作的唯一入口,也是集群控制的入口进程。
kubernetes controller manager 这个是kubernetes里所以资源对象的自动化控制中心
kubernetes scheduler负责资源调度
etcd数据保存进程
Node是kubernetes集群的工作节点,可以是物理机也可以是虚拟机。
node节点上运行的进程
kubelet:负责pod对应容器的创建,启停等任务,与master协作,实现集群管理的基本功能
kube-proxy:实现kubernetes server的同学与负载均衡机制的重要组件
docker:docker引擎,负责本机容器的创建和管理
node1节点可以动态的增加到kubernetes集群中,前提是设置好上面配置,这也是推荐的node管理方式。一旦注册成功。master就可以获取到node的信息
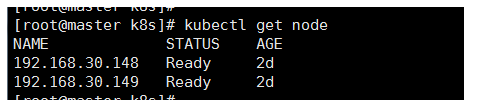
查看集群中node个数
[root@master k8s]#kubectl get nodes
查看某个node具体信息
[root@master k8s]# kubectl describe node 192.168.30.148

3.etcd
Etcd是Kubernetes集群中的一个十分重要的组件,用于保存集群所有的网络配置和对象的状态信息
整个kubernetes系统中一共有两个服务需要用到etcd用来协同和存储配置,分别是:
- 网络插件flannel、对于其它网络插件也需要用到etcd存储网络的配置信息
- kubernetes本身,包括各种对象的状态和元信息配置
4.控制器
Deployment
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationController 来方便的管理应用。典型的应用场景包括:
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
扩容/缩容:
kubectl scale deployment nginx-deployment --replicas 10
如果集群支持 horizontal pod autoscaling 的话,还可以为Deployment设置自动扩展:
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
更新镜像也比较简单:
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
回滚:
kubectl rollout undo deployment/nginx-deployment

DESIRED:Pod副本数量的期待值,即Deployment里定义的Replica
CURRENT:当前Replica的值,实际上是Deployment所创建的Replica Set里的Replica值,这个值不断增加,直到达到desired为止,表明部署完成
UP-TO-DATE:最新版本的Pod的副本数量,用于指示在滚动升级的过程中有多少个副本成功升级
AVAILABLE:当前集群中可用的Pod副本数量,即集群中存活的Pod数量
查看replica set设置
[root@master k8s]# kubectl get rs

StatefulSet
StatefulSet 作为 Controller 为 Pod 提供唯一的标识。它可以保证部署和 scale 的顺序。
StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
- 有序收缩,有序删除(即从N-1到0)
StatefulSet 适用于有以下某个或多个需求的应用:
- 稳定,唯一的网络标志。
- 稳定,持久化存储。
- 有序,优雅地部署和 scale。
- 有序,优雅地删除和终止。
- 有序,自动的滚动升级。
在上文中,稳定是 Pod (重新)调度中持久性的代名词。 如果应用程序不需要任何稳定的标识符、有序部署、删除和 scale,则应该使用提供一组无状态副本的 controller 来部署应用程序,例如 Deployment 或 ReplicaSet 可能更适合您的无状态需求。
限制
- StatefulSet 是 beta 资源,Kubernetes 1.5 以前版本不支持。
- 对于所有的 alpha/beta 的资源,您都可以通过在 apiserver 中设置 --runtime-config 选项来禁用。
- 给定 Pod 的存储必须由 PersistentVolume Provisioner 根据请求的 storage class 进行配置,或由管理员预先配置。
- 删除或 scale StatefulSet 将不会删除与 StatefulSet 相关联的 volume。 这样做是为了确保数据安全性,这通常比自动清除所有相关 StatefulSet 资源更有价值。
- StatefulSets 目前要求 Headless Service 负责 Pod 的网络身份。 您有责任创建此服务。
DaemonSet
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
使用 DaemonSet 的一些典型用法:
- 运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph。
- 在每个 Node 上运行日志收集 daemon,例如fluentd、logstash。
- 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、collectd、Datadog 代理、New Relic 代理,或 Ganglia gmond。
一个简单的用法是,在所有的 Node 上都存在一个 DaemonSet,将被作为每种类型的 daemon 使用。 一个稍微复杂的用法可能是,对单独的每种类型的 daemon 使用多个 DaemonSet,但具有不同的标志,和/或对不同硬件类型具有不同的内存、CPU要求。
ReplicationController(RC)和ReplicaSet
ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收。
在新版本的Kubernetes中建议使用ReplicaSet来取代ReplicationController。ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector。
虽然ReplicaSet可以独立使用,但一般还是建议使用 Deployment 来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet不支持rolling-update但Deployment支持)。
Job
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
Job Spec格式
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
- .spec.completions标志Job结束需要成功运行的Pod个数,默认为1
- .spec.parallelism标志并行运行的Pod的个数,默认为1
- spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
CronJob
Cron Job 管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
5.HPA
动态扩容
6.service
service是kubernetes里最核心的资源对象之一,kubernetes里的每一个service其实就是微架构中的一个“微服务”
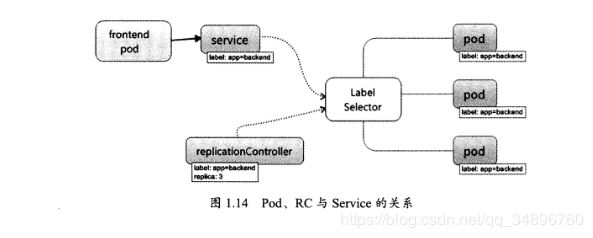
由图可以看出,service定义了一个服务的访问入口,前端应用POD通过这个入口访问后面的POD副本组成的集群实例,service与其后端的POD副本集群之间通过Label selector来实现“无缝对接”,而RC的作用是保证service的服务能力和服务质量始终处于预期标准上。
7.Volume
Volume是pod中能被多个容器访问的共享目录,和docker不同,kubernetes的volume定义在pod上,被一个pod里面的多个容器挂载在具体目录,其次,kubernetes中的volume和pod生命周期相同,但与容器的生命周期无关,当容器停止或重启,volume中的数据也不会丢失。

kubernetes提供了非常多的volume类型
1.emptyDir

2.hostPath

3.nfs

pod容器共享volume


8.Namespace
namespace是kubernetes系统中一个非常重要的概念,很多时候用于实现多租户的资源隔离,namespace通过将集群内部的资源对象“分配”到不同的namespace中,形成逻辑上分组不同的不同项目,小组,或用户组,便于不同分组在共享使用整个集群的资源的同时还能被分别管理。
kubernetes默认的namespace是“default”
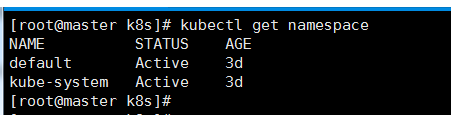

当创建完成后,就可以在创建资源对象时指定这个资源对象属于那个namespace。
比如定义一个名为busybox的pod,放入development这个namespace里。


# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure]#Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string