数据分析之旅(一)
数据分析过程
提出问题 <–> 数据再加工(包括数据采集和数据清理) <–> 数据探索(培养直觉,找出数据模式) –> 总结,进行预测 –> 与他人交流结果(博客、论文、电子邮件、PPT、面谈)
并且所有的过程都可能回到第一个阶段:提出问题
数据采集的方式
1. 下载文件;
2. 从API获取数据;
3. 从网页中爬取数据;
4. 对多种不同格式的数据进行合并;
CSV–Comma Separated Values
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。(摘自百度百科)
打开一个CSV文件:

对比一下在Sublime Text 3中打开:
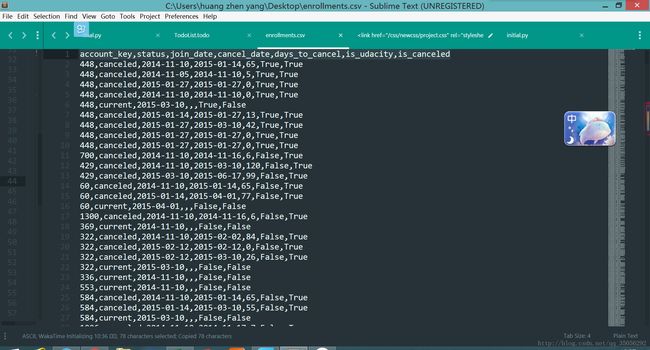
可以看到,每一个单元后面有一个逗号。因此,CSV文件容易通过编程来处理。
Python 与 CSV
CSV文件内容为一系列的行,而行的显示方式有两种:
1. 每一行都是一个列表,那么整个文件内容就是一系列的列表;
2. 每一行都是一个字典,用于 有标题行的文件(字典的关键字作为列的名字,字段则作为值),那么整个文件内容就是一系列的字典。
Python中有个库:unicodecsv(是 Anaconda 附带的模块,并且支持 unicode) 可以帮助我们读取CSV文件内容:
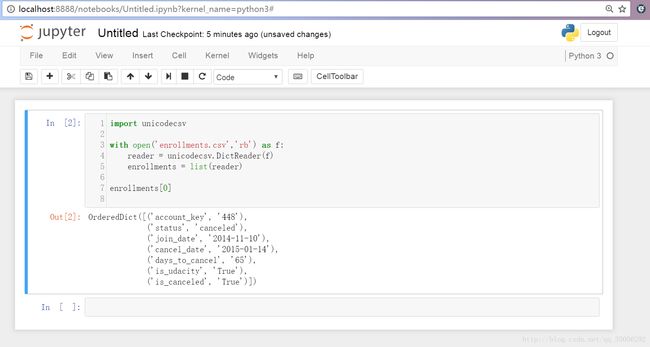
在这里第三行, 用到了DictReader,表明每一行都是一个字典
Attention:
1. 阅读器(reader)是一种迭代器 ;
2. CSV库不会检查各列的类型,因此需要修正数据类型,尽量在得到数据后就进行修正,避免后续的错误;
小练习之调查数据
在这次的小练习中,有四个CSV文件:
1.enrollments.csv; 学生注册信息文件
2.daily_engagement.csv;学生每一天的记录文件 3.project_submissions.csv;学生项目提交数据表文件
4.daily_engagement_full.csv;更完整的每日记录文件
任务:在前三个文件中,找出CSV文件中的总行数以及不重复学员的数量。
思路:
CSV文件总行数比较简单,用reader获取内容以后直接用Python的len()函数即可;
对于不重复的学员的数量。首先,我是先查看每一行的数据结构:
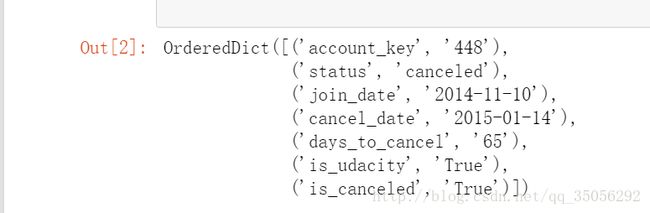
根据文档里所述,这里,account_key就是标识学员的id。
代码如下:
import unicodecsv
def read_csv(filename):
with open(filename, 'rb') as f:
reader = unicodecsv.DictReader(f)
return list(reader)
enrollments = read_csv('enrollments.csv')
daily_engagement = read_csv('daily_engagement.csv')
project_submissions = read_csv('project_submissions.csv')
def unique_students(csvlist,keyname):
s = set()
for each in csvlist:
s.add(each[keyname])
return s
enrollment_num_rows = len(enrollments)
enrollment_num_unique_students = len(unique_students(enrollments,"account_key"))
engagement_num_rows = len(daily_engagement)
engagement_num_unique_students = len(unique_students(daily_engagement,"acct"))
submission_num_rows = len(project_submissions)
submission_num_unique_students = len(unique_students(project_submissions,"account_key")) 结果:
第一个文件的行数:1640
有登记的学生数:1302
第二个文件行数:136240
有记录的学生数:1237
第三个文件行数:3642
有提交项目的学生数:743
可以看出,有登记的学生与有记录的学生数量并不一样。这里留到下一篇文章讲。
遇到的问题:

一开始一直遇到KeyError的问题。明明文件里有这个Key,却一直报错。而KeyError异常是在取不到对应key的value情况下报的。
解决:后来发现是因为第二个文件用来唯一标识学员用的是 “acct”。确实是人错了0 0不是机器错了。哭晕在厕所 /(ㄒoㄒ)/~~