Kafka分布式消息队列的基本原理和使用
学习kafka
一、简介
- kafka是一个分布式的消息队列,可以集群部署,消息队列的作用如下。

-
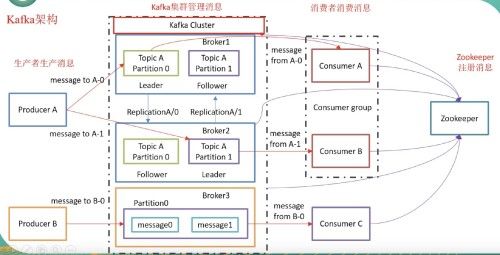
kafka对消息保存时根据Topic进行归类。发送消息者称为Producer,消息接受者称为Consumer。
kafka集群有多个kafka实例,每个实例称为broker。 -
无论是kafka就集群,还是consumer都依赖于
zookeeper集群保存一些meta信息,保证系统可用性。 -
kafka的Topic是分区的形式分布在不同的实例上,每个分区有N个副本,N个副本中有一个是Leader,N-1个Followers。
-
一个消费者组中的消费者不能同时消费同一个分区。
-
kafka的工作架构如下。
二、简单使用
以一个三节点的kafka集群为例(伪分布式方式)
2.1 配置文件
2.1.1 config/server.properties
conf/server.properties是kafka的主要配置文件,主要修改以下属性。
- listeners: 这个broker(kafka进程)监听的端口
- broker.id: 这个broker在zookeeper中注册的id号,全局唯一的,不同的broker一定不要相同。
- log.dirs: 日志的输出文件。
- zookeeper.connect: 集群中所有zookeeper的hostname:port ,逗号隔开。
2.1.2 config/zookeeper.properties
config/zookeeper.properties是zookeeper的配置文件,修改以下属性
- dataDir: 因为是伪分布式部署,所以数据文件路径最好不要相同
- clientPort: 伪分布式,端口不能相同。
2.2 启动集群zookeeper服务
因为是伪分布式,所以只要在其中一个节点启动kafka自带的zookeeper就好,其实在实际生产中,要自己下载安装zookeeper集群去维护meta信息。
./bin/zookeeper-server-start.sh ./config/zookeeper.properties &
用jps命令查看是否启动成功。如果启动成功,会出现三个QuorumPeerMain进程。
2.3 启动broker集群
在每个kafka解压目录下面启动。
./bin/kafka-server-start.sh ./config/server.properties &
使用JPS查看Java进程,若发现三个Kafka进程,则启动成功。
2.4 创建 topic
在任何一个节点的解压目录下,执行如下命令。
./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic test
其中
- bootstrap-server: 引导节点,由这个节点的kafka服务进行topic分区和副本的建立。
- replication-factor: 指定每个分区的副本数。
- partitions: 指定该topic的总分区数。
- topic: 指定创建的topic名称。
其实这时候三个kafka进程之间是share nothing的,上面创建了一个名为test的topic。该topic有三个分区,每个分区有三个副本,其中一个leader,两个follower,至于哪个是leader,是随机的。9块分区副本分布在三个kafka节点上,meta信息由zookeeper维护。
2.5 Producer 发送消息
我们简单的在console中发送消息给这个topic。
./bin/kafka-console-producer.sh --broker-list localhost:9092 -topic test
> message1...
> message2...
2.6 Consumer接收消息
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test
message1...
message2...
消费完所有消息后,consumer阻塞,等待新的消息push过来。
consumer消费数据之后,我们来用list命令查看现在
2.7 Describe查看Topic的分区状态
./bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic test
Topic:test PartitionCount:3 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: test Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
可以看到,test这个topic在9092端口对应的broker有三个分区副本,分别是分区0、1、2的副本。
- Partition: 这个broker拥有的分区号。
- Leader: 这个分区对应的Leader副本是那个,副本号。
- Replicas: broker的个数,包括已经挂掉的。
- Isr: Active的broker个数。
2.8 将文件作为kafka的输入
日常生产中会产生非常多的日志,kafka能够对正在写入的日志文件进行分析,文件中的每一行作为topic的一个record。我们看一下官方给的例子。
首先在当前目录下创建一个文件。
echo -e "foo\nbar" > test.txt
kafka官方为我们提供了一个bin文件bin/connect-standalone.sh,负责建立文件输入topic,有三个配置文件。
- config/connect-standalone.properties 里面是bootstrap和plugin的相关配置。
- config/connect-file-source.properties 源文件名、topic名的一些配置。
- config/connect-file-sink.properties
执行如下命令,启动standalone脱机处理,意思就是以文件为输入。
./bin/connect-standalone.sh ./config/connect-standalone.properties ./config/connect-file-source.properties ./config/connect-file-sink.properties
会在当前目录生成一个test.sink.txt的文件,这个其实是kafka在对test.txt进行流处理之后的输出文件
配置文件中topic name是connect-test,所以执行以下命令。
/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
...
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
可以看到,文件中的两行数据,foo和bar都被当作topic connect-test的record输入了。如果消费这个topic,可以获得每行信息。
三、一些基本原理
3.1 分区和副本
- Kafka的副本一定是保存在不同的broker上,同一个Broker保存两个副本没有意义。
- Kafka的分区方式可以自己自定义的方式指定,比如Hash的方式,轮询的方式等等。
- 同一个消费者组中的消费者不能消费同一个分区。消费者组内的消费者是多线程的,每个线程对应一个消费者,每个线程消费自己的分区,可能是多个分区。
3.2 zookeeper的作用
- broker注册:broker在zookeeper中以/brokers/ids/#id的方式注册自己,让其他broker发现自己。
- 消费者注册:消费者会在zookeeper的/consumers/[group_id]/ids/[consumer_id]下注册自己。
- 保存topic的meta信息:也就是topic的分区信息,分区副本分布在哪些broker上。
- 生产者负载均衡:生产者将消息生产到不同的分区,分区位置是通过zookeeper获得的。
- 消费者负载均衡:每个消费者只消费一个分区的消息,这个关系也是zookeeper维护的,/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]。
3.2 关于Producer
producer有个概念叫做 ACK应答机制 。producer在生产消息的时候,会指定有一个应答策略,0,1,all三种。
- 0:不需要任何分区应答,producer只管写数据。速度很快,但容易丢数据。
- 1:只需要leader分区应答ack。速度中等,不丢数据,但可能会产生leader和followers的数据不一致。
- all:leader和所有followers都需要做ack应答,速度慢,但数据一致性强。
四 Java API的使用方式
见代码