LSTM输入输出详解,tensorflow.nn.bidirectional_dynamic_rnn()函数的用法
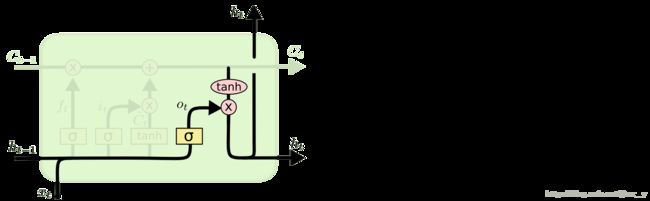
LSTM结构

参数介绍:

分步介绍:



LSTM 的变种 GRU:

数学原理:
公式参数:
xt∈Rd x t ∈ R d : input vector to the LSTM unit
ft∈Rhft∈Rh f t ∈ R h f t ∈ R h : forget gate’s activation vector
it∈Rhit∈Rh i t ∈ R h i t ∈ R h : input gate’s activation vector
ot∈Rhot∈Rh o t ∈ R h o t ∈ R h : output gate’s activation vector
ht∈Rhht∈Rh h t ∈ R h h t ∈ R h : output vector of the LSTM unit
ct∈Rhct∈Rh c t ∈ R h c t ∈ R h : cell state vector
W∈Rh×dW∈Rh×d,U∈Rh×hU∈Rh×handb∈Rhb∈Rh W ∈ R h × d W ∈ R h × d , U ∈ R h × h U ∈ R h × h a n d b ∈ R h b ∈ R h : weight matrices and bias vector parameters which need to be learned during training
tensorflow.nn.bidirectional_dynamic_rnn()函数的用法
def bidirectional_dynamic_rnn(
cell_fw, # 前向RNN
cell_bw, # 后向RNN
inputs, # 输入
sequence_length=None,# 输入序列的实际长度(可选,默认为输入序列的最大长度)
initial_state_fw=None, # 前向的初始化状态(可选)
initial_state_bw=None, # 后向的初始化状态(可选)
dtype=None, # 初始化和输出的数据类型(可选)
parallel_iterations=None,
swap_memory=False,
time_major=False,
# 决定了输入输出tensor的格式:如果为true, 向量的形状必须为 `[max_time, batch_size, depth]`.
# 如果为false, tensor的形状必须为`[batch_size, max_time, depth]`.
scope=None
)返回值:
元组: (outputs, output_states)
其中,
outputs为(output_fw, output_bw),是一个包含前向cell输出tensor和后向cell输出tensor组成的元组。假设 time_major=false, 而且tensor的shape为[batch_size, max_time, depth]。实验中使用tf.concat(outputs, 2)将其拼接。
output_states为(output_state_fw, output_state_bw),包含了前向和后向最后的隐藏状态的组成的元组。
output_state_fw和output_state_bw的类型为LSTMStateTuple。
LSTMStateTuple由(c,h)组成,分别代表memory cell和hidden state。
LSTM应用到双向RNN中
而cell_fw和cell_bw的定义是完全一样的。如果这两个cell选LSTM cell整个结构就是双向LSTM了。
# lstm模型正方向传播的RNN
lstm_fw_cell = tf.nn.rnn_cell.BasicLSTMCell(embedding_size, forget_bias=1.0)
# 反方向传播的RNN
lstm_bw_cell = tf.nn.rnn_cell.BasicLSTMCell(embedding_size, forget_bias=1.0)但是看来看去,输入两个cell都是相同的啊?
其实在bidirectional_dynamic_rnn函数的内部,会把反向传播的cell使用array_ops.reverse_sequence的函数将输入的序列逆序排列,使其可以达到反向传播的效果。
在实现的时候,我们是需要传入两个cell作为参数就可以了:
(outputs, output_states) = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell, lstm_bw_cell, embedded_chars, dtype=tf.float32)embedded_chars为输入的tensor,[batch_szie, max_time, depth]。batch_size为模型当中batch的大小,应用在文本中时,max_time可以为句子的长度(一般以最长的句子为准,短句需要做padding),depth为输入句子词向量的维度。
代码示例
import tensorflow as tf
import numpy as np
X = np.random.randn(2, 10, 8)
# The second example is of length 6
X[1, 6:] = 0
X_lengths = [10, 6]
cell = tf.nn.rnn_cell.LSTMCell(num_units=5, state_is_tuple=True)
outputs, states = tf.nn.bidirectional_dynamic_rnn(
cell_fw=cell, cell_bw=cell, dtype=tf.float64, sequence_length=X_lengths, inputs=X
)
output_fw, output_bw = outputs
states_fw, states_bw = states
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
states_shape = tf.shape(states)
print(states_shape.eval())
c, h = states_fw
o = output_fw
print('c\n', sess.run(c))
print('h\n', sess.run(h))
print('o\n', sess.run(o))输出结果

讨论
LSTMStateTuple, LSTM state tuple是tensorflow用来表示state的一种格式定义,tensorflow的state_size, zero_state, and output state都是用LSTMStateTuple表示的。LSTMStateTuple包括(c, h) => c 是hidden state,h是output state,如果不清楚可以和上面LSTM结构图片对比。
c和h长什么样?
代码中以前向LSTM(states_fw)为例,输出了的c, 和 h。
c, h都是(2, 5),2是因为有两个batch input,5是因为cell unit is 5。所以每对于一个batch input,lstm 都给一个forward state,forwarding state分成c (hidden state), 和h (output state). 然后分别是unit size的vector。backward state也是一样。
Output长什么样
Output也分为forward cell和backward_cell的,我们就看forward cell
output_fw的size是(2, 10, 5)。所以对于一个batch中的每一个input vector (本例中每一个batch是10 × 8,所以有10个vector),lstm都输出一个5的vector(5 is unit size)。
然后我们可以发现,之前state中的h,就是output中的最后一组vector!第二组h不是0, 是因为sequance_length参数 (也就是走了6个lstm就结束了)!
所以如果只需要take lstm中的final output,而不在乎中间过程(比如建一个classifier,而不是seq2seq)。直接take state output就可以了。