JVM
初识JVM
JVM的概念
JVM是Java Virtual Machine的简称。意为Java虚拟机
虚拟机:指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。
有哪些虚拟:
VMWare
Visual Box
JVM
VMWare或者Visual Box都是使用软件模拟物理CPU的指令集
JVM使用软件模拟Java字节码的指令集
JVM的发展历史
1996年 SUN JDK 1.0 Classic VM
纯解释运行,使用外挂进行JIT,没有内置的即时编译的功能
1997年 JDK1.1 发布
AWT、内部类、JDBC、RMI、反射
1998年 JDK1.2 Solaris Exact VM
JIT 解释器混合
Accurate Memory Management 精确内存管理,数据类型敏感
提升的GC性能
JDK1.2开始 称为Java 2
J2SE J2EE J2ME 的出现
加入Swing Collections
2000年 JDK 1.3 Hotspot 作为默认虚拟机发布 加入JavaSound 声音相关的API
2002年 JDK 1.4 Classic VM退出历史舞 Assert 正则表达式 NIO IPV6 日志API 加密类库
2004年发布 JDK1.5 即 JDK5 、J2SE 5 、Java 5
泛型
注解
装箱
枚举
可变长的参数
Foreach循环
JDK1.6 JDK6
脚本语言支持
JDBC 4.0
Java编译器 API
2011年 JDK7发布
延误项目推出到JDK8
G1 GC收集器
动态语言增强 脚本语言
64位系统中的压缩指针
NIO 2.0
2014年 JDK8发布
Lambda表达式 模拟了函数式的编程语言的思想,试图去解决面向对象编程代码过程的问题
语法增强 Java类型注解
2016年JDK9
模块化 Java和JVM的历史 – 大事记
使用最为广泛的JVM为HotSpot
HotSpot 为Longview Technologies开发 被SUN收购
2006年 Java开源 并建立OpenJDK
HotSpot 成为Sun JDK和OpenJDK中所带的虚拟机
2008 年 Oracle收购BEA
得到JRockit VM
2010年Oracle 收购 Sun
得到Hotspot
Oracle宣布在JDK8时整合JRockit和Hotspot,优势互补
在Hotspot基础上,移植JRockit优秀特性JVM种类
各式JVM
KVM
SUN发布
IOS Android前,广泛用于手机系统
CDC/CLDC HotSpot
手机、电子书、PDA等设备上建立统一的Java编程接口
J2ME的重要组成部分
JRockit
BEA
IBM J9 VM
IBM内部
Apache Harmony
兼容于JDK 1.5和JDK 1.6的Java程序运行平台
与Oracle关系恶劣 退出JCP ,Java社区的分裂
OpenJDK出现后,受到挑战 2011年 退役
没有大规模商用经历
对Android的发展有积极作用Java语言规范
语法
语法定义:
IfThenStatement:
if ( Expression ) Statement
ArgumentList:
Argument
ArgumentList , Argument
if(true){do sth;}
add(a,b,c,d);词法结构:
\u + 4个16进制数字 表示UTF-16
行终结符: CR, or LF, or CR LF.
空白符
空格 tab \t 换页 \f 行终结符
注释
标示符
关键字
Identifier:
IdentifierChars but not a Keyword or BooleanLiteral or NullLiteral
IdentifierChars:
JavaLetter
IdentifierChars JavaLetterOrDigit
JavaLetter:
any Unicode character that is a Java letter (see below)
JavaLetterOrDigit:
any Unicode character that is a Java letter-or-digit (see below)
Int
0 2 0372 0xDada_Cafe 1996 0x00_FF__00_FF
Long
0l 0777L 0x100000000L 2_147_483_648L 0xC0B0L
Float
1e1f 2.f .3f 0f 3.14f 6.022137e+23f
Double
1e1 2. .3 0.0 3.14 1e-9d 1e137
操作
+= -= *= /= &= |= ^= %= <<= >>= >>>=变量、类型
类型和变量:
元类型
byte short int long float char
变量初始值
boolean false
char \u0000
泛型一个小例子:
class Value { int val; }
class Test {
public static void main(String[] args) {
int i1 = 3;
int i2 = i1;
i2 = 4;
System.out.print("i1==" + i1);
System.out.println(" but i2==" + i2);
Value v1 = new Value();
v1.val = 5;
Value v2 = v1;
v2.val = 6;
System.out.print("v1.val==" + v1.val);
System.out.println(" and v2.val==" + v2.val);
}
}
result:
i1==3 but i2==4
v1.val==6 and v2.val==6
i1 i2为不同的变量
v1 v2为引用同一个实例文法
赞略…………后面会补充
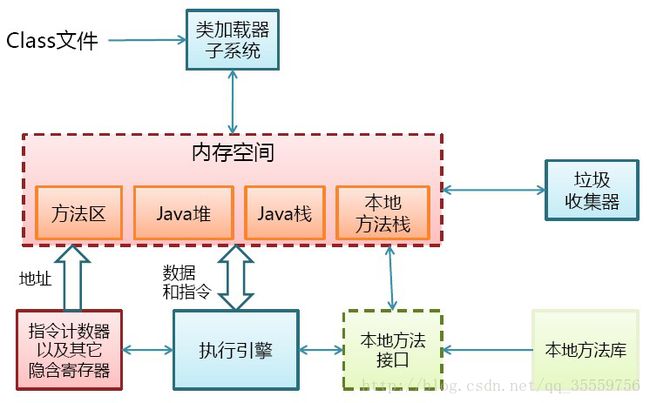
Java内存模型
类加载链接的过程
public static final abstract的定义
异常
数组的使用
…….
JVM规范
Java语言规范了什么是Java语言
Java语言和JVM相对独立
Groovy
Clojure
Scala
JVM主要定义二进制class文件和JVM指令集等Class 文件格式
数字的内部表示和存储
Byte -128 to 127 (-27 to 27 - 1)
returnAddress 数据类型定义
指向操作码的指针。不对应Java数据类型,不能在运行时修改。Finally实现需要
定义PC
堆
栈
方法区Class文件类型
运行时数据
帧栈
虚拟机的启动
虚拟机的指令集
整数的表示:
原码:第一位为符号位(0为正数,1为负数)
反码:符号位不动,原码取反
负数补码:符号位不动,反码加1
正数补码:和原码相同
打印整数的二进制表示
int a=-6;
for(int i=0;i<32;i++){
int t=(a & 0x80000000>>>i)>>>(31-i);
System.out.print(t);
}
result:
-6
原码: 10000110
反码: 11111001
补码: 11111010
5
00000101
-1
原码: 10000001
反码: 11111110
补码: 11111111为什么要用补码?
计算0的表示
0
负数:10000000
反码:11111111
补码:00000000
-6+5
11111010
+ 00000101
= 11111111Float的表示与定义
支持 IEEE 754
s eeeeeeee mmmmmmmmmmmmmmmmmmmmmmm
指数:8
尾数:23
e全0 尾数附加位为0 否则尾数附加位为1
s*m*2^(e-127)
例如:
-5
11000000101000000000000000000000
-1*2^(129-127)*(2^0+2^-2)
一些特殊的方法
类的初始化方法
对象的初始化方法 VM指令集
类型转化
l2i
出栈入栈操作
aload astore
运算
iadd isub
流程控制
ifeq ifne
函数调用
invokevirtual invokeinterface invokespecial invokestatic JVM需要对Java Library 提供支持
反射 java.lang.reflect
ClassLoader
初始化class和interface
安全相关 java.security
多线程
弱引用JVM的编译
源码到JVM指令的对应格式
Javap
JVM反汇编的格式
[ [ ... ]] []
例如:
void spin() {
int i;
for (i = 0; i < 100; i++) { ;
// Loop body is empty
}
}
0 iconst_0 // Push int constant 0
1 istore_1 // Store into local variable 1 (i=0)
2 goto 8 // First time through don't increment
5 iinc 1 1 // Increment local variable 1 by 1 (i++)
8 iload_1 // Push local variable 1 (i)
9 bipush 100 // Push int constant 100
11 if_icmplt 5 // Compare and loop if less than (i < 100)
14 return // Return void when done 小结:
JVM只是规范,Hospot只是实现JVM运行机制
JVM启动流程
Java XXX--->装载配置--->根据配置寻找JVM.dll--->初始化JVM获得JNIEnv接口--->找到main方法并运行
装载配置---根据当前路径和系统版本寻找jvm.cfg
根据配置寻找JVM.dll---JVM.dll为JVM主要实现
初始化JVM获得JNIEnv接口---JNIEnv为JVM接口,findClass等操作通过它实现JVM基本结构
PC寄存器
每个线程拥有一个PC寄存器
在线程创建时 创建
指向下一条指令的地址
执行本地方法时,PC的值为undefined方法区
保存装载的类信息
类型的常量池
字段,方法信息
方法字节码
通常和永久区(Perm)关联在一起
JDK6时,String等常量信息置于方法
JDK7时,已经移动到了堆Java堆
和程序开发密切相关
应用系统对象都保存在Java堆中
所有线程共享Java堆
对分代GC来说,堆也是分代的
GC的主要工作区间
eden-s0-s1-tenured
复制算法Java栈
线程私有
栈由一系列帧组成(因此Java栈也叫做帧栈)
帧保存一个方法的局部变量、操作数栈、常量池指针
每一次方法调用创建一个帧,并压栈Java栈-局部变量表 包含参数和局部变量
public class StackDemo {
public static int runStatic(int i,long l,float f,Object o ,byte b){
return 0;
}
public int runInstance(char c,short s,boolean b){
return 0;
}
}
running result:
0 int int i
1 long long l
3 float float f
4 reference Object o
5 int byte b
0 reference this
1 int char c
2 int short s
3 int boolean bJava栈 – 函数调用组成帧栈
public static int runStatic(int i,long l,float f,Object o ,byte b){
return runStatic(i,l,f,o,b);
}
running-result:
这是一个帧
省略:操作数栈 返回地址等
0 int int i
1 long long l
3 float float f
4 reference Object o
5 int byte b
0 int int i
1 long long l
3 float float f
4 reference Object o
5 int byte b
0 int int i
1 long long l
3 float float f
4 reference Object o
5 int byte bJava栈 – 操作数栈
Java没有寄存器,所有参数传递使用操作数栈
public static int add(int a,int b){
int c=0;
c=a+b;
return c;
}
0: iconst_0 // 0压栈
1: istore_2 // 弹出int,存放于局部变量2
2: iload_0 // 把局部变量0压栈
3: iload_1 // 局部变量1压栈
4: iadd //弹出2个变量,求和,结果压栈
5: istore_2 //弹出结果,放于局部变量2
6: iload_2 //局部变量2压栈
7: ireturn //返回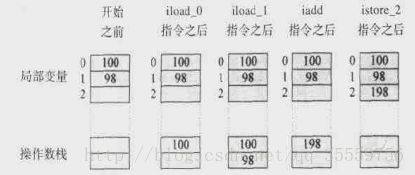
Java栈 – 栈上分配
C++ 代码示例
class BcmBasicString{ ....}
堆上分配 每次需要清理空间
public void method(){
BcmBasicString* str=new BcmBasicString;
.... delete str;
}
栈上分配 函数调用完成自动清理
public void method(){
BcmBasicString str;
....
}Java栈 – 栈上分配
public class OnStackTest {
public static void alloc(){
byte[] b=new byte[2];
b[0]=1;
}
public static void main(String[] args) {
long b=System.currentTimeMillis();
for(int i=0;i<100000000;i++){
alloc();
}
long e=System.currentTimeMillis();
System.out.println(e-b);
}
}
-server -Xmx10m -Xms10m
-XX:+DoEscapeAnalysis -XX:+PrintGC
输出结果 5
-server -Xmx10m -Xms10m
-XX:-DoEscapeAnalysis -XX:+PrintGC
……
[GC 3550K->478K(10240K), 0.0000977 secs]
[GC 3550K->478K(10240K), 0.0001361 secs]
[GC 3550K->478K(10240K), 0.0000963 secs]
564Java栈 – 栈上分配
小对象(一般几十个bytes),在没有逃逸的情况下,可以直接分配在栈上
直接分配在栈上,可以自动回收,减轻GC压力
大对象或者逃逸对象无法栈上分配栈、堆、方法区交互
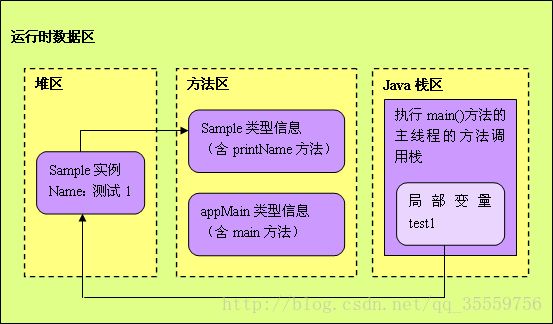
public class AppMain
//运行时, jvm 把appmain的信息都放入方法区
{
public static void main(String[] args)
//main 方法本身放入方法区。
{
Sample test1 = new Sample( " 测试1 " );
//test1是引用,所以放到栈区里, Sample是自定义对象应该放到堆里面
Sample test2 = new Sample( " 测试2 " );
test1.printName();
test2.printName();
}
}
}
public class Sample
//运行时, jvm 把appmain的信息都放入方法区
{
private name;
//new Sample实例后, name 引用放入栈区里, name 对象放入堆里
public Sample(String name)
{
this .name = name;
}
//print方法本身放入 方法区里。
public void printName()
{
System.out.println(name);
}
}
为了能让递归函数调用的次数更多一些,应该怎么做呢?
内存模型
每一个线程有一个工作内存和主存独立
工作内存存放主存中变量的值的拷贝
read,load-> use->
主内存<------->线程工作内存<--------->线程执行引擎
<-store,write <-assign
当数据从主内存复制到工作存储时,必须出现两个动作:第一,由主内存执行的读(read)操作;第二,由工作内存执行的相应的load操作;当数据从工作内存拷贝到主内存时,也出现两个操作:第一个,由工作内存执行的存储(store)操作;第二,由主内存执行的相应的写(write)操作
每一个操作都是原子的,即执行期间不会被中断
对于普通变量,一个线程中更新的值,不能马上反应在其他变量中
如果需要在其他线程中立即可见,需要使用 volatile 关键字

volatile:
当一个线程修改共享数据时需要立即让其他线程保持数据实时有效性
public class VolatileStopThread extends Thread{
private volatile boolean stop = false;
public void stopMe(){
stop=true;
}
public void run(){
int i=0;
while(!stop){//线程不停监听值
i++;
}
System.out.println("Stop thread");
}
public static void main(String args[]) throws InterruptedException{
VolatileStopThread t=new VolatileStopThread();
t.start();
Thread.sleep(1000);
t.stopMe();
Thread.sleep(1000);
}
}
没有volatile -server 运行 无法停止
volatile 不能代替锁
一般认为volatile 比锁性能好(不绝对)
选择使用volatile的条件是:
语义是否满足应用几个跟内存模型相关的概念:
可见性:
一个线程修改了变量,其他线程可以立即知道
保证可见性的方法:
volatile
synchronized (unlock之前,写变量值回主存)
final(一旦初始化完成,其他线程就可见)
有序性:
在本线程内,操作都是有序的
在线程外观察,操作都是无序的。(指令重排 或 主内存同步延时)
指令重排:
线程内串行语义
写后读 a = 1;b = a; 写一个变量之后,再读这个位置。
写后写 a = 1;a = 2; 写一个变量之后,再写这个变量。
读后写 a = b;b = 1; 读一个变量之后,再写这个变量。
以上语句不可重排
编译器不考虑多线程间的语义
可重排: a=1;b=2;
指令重排 – 破坏线程间的有序性:
class OrderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1;
flag = true;
}
public void reader() {
if (flag) {
int i = a +1;
……
}
}
}
线程A首先执行writer()方法
线程B线程接着执行reader()方法
线程B在int i=a+1 是不一定能看到a已经被赋值为1
因为在writer中,两句话顺序可能打乱
线程A
flag=true
a=1
线程B
flag=true(此时a=0)
指令重排 – 保证有序性的方法:
class OrderExample {
int a = 0;
boolean flag = false;
public synchronized void writer() {
a = 1;
flag = true;
}
public synchronized void reader() {
if (flag) {
int i = a +1;
……
}
}
}
同步后,即使做了writer重排,因为互斥的缘故,reader 线程看writer线程也是顺序执行的。
线程A
flag=true
a=1
--------------
线程B
flag=true(此时a=1)
加锁之后,多线程执行方法时会保持串行而不是并行
指令重排的基本原则:
程序顺序原则:一个线程内保证语义的串行性
volatile规则:volatile变量的写,先发生于读
锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
传递性:A先于B,B先于C 那么A必然先于C
线程的start方法先于它的每一个动作
线程的所有操作先于线程的终结(Thread.join())
线程的中断(interrupt())先于被中断线程的代码
对象的构造函数执行结束先于finalize()方法
例:
a=4;
b=a+4;编译和解释运行的概念
解释运行
解释执行以解释方式运行字节码
解释执行的意思是:读一句执行一句
编译运行(JIT)即时编译
将字节码编译成机器码
直接执行机器码
运行时编译
编译后性能有数量级的提升
性能相差10倍以上常用JVM配置参数
Trace跟踪参数
-verbose:gc
-XX:+printGC
打开GC的开关
可以打印GC的简要信息
[GC 4790K->374K(15872K), 0.0001606 secs]
[GC 4790K->374K(15872K), 0.0001474 secs]
[GC 4790K->374K(15872K), 0.0001563 secs]
[GC 4790K->374K(15872K), 0.0001682 secs]
-XX:+PrintGCDetails
打印GC详细信息
-XX:+PrintGCTimeStamps
打印CG发生的时间戳
例
[GC[DefNew: 4416K->0K(4928K), 0.0001897 secs] 4790K->374K(15872K), 0.0002232 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-XX:+PrintGCDetails在程序运行后堆信息的输出
Heap
def new generation total 13824K, used 11223K [0x27e80000, 0x28d80000, 0x28d80000)
eden space 12288K, 91% used [0x27e80000, 0x28975f20, 0x28a80000)
from space 1536K, 0% used [0x28a80000, 0x28a80000, 0x28c00000)
to space 1536K, 0% used [0x28c00000, 0x28c00000, 0x28d80000)
tenured generation total 5120K, used 0K [0x28d80000, 0x29280000, 0x34680000)
the space 5120K, 0% used [0x28d80000, 0x28d80000, 0x28d80200, 0x29280000)
compacting perm gen total 12288K, used 142K [0x34680000, 0x35280000, 0x38680000)
the space 12288K, 1% used [0x34680000, 0x346a3a90, 0x346a3c00, 0x35280000)
ro space 10240K, 44% used [0x38680000, 0x38af73f0, 0x38af7400, 0x39080000)
rw space 12288K, 52% used [0x39080000, 0x396cdd28, 0x396cde00, 0x39c80000)
注:
total = edent space + from space
used [低边界(起始位置),当前边界,最高边界(最多能申请的位置)]
(0x28d80000-0x27e80000)/1024/1024=15M
from == to
ro,rw 共享区间大小
一般GC信息都是在控制台的不方便分析
-Xloggc:log/gc.log
指定GC log的位置,以文件输出
帮助开发人员分析问题
-XX:+PrintHeapAtGC
每次一次GC后,都打印堆信息
{Heap before GC invocations=0 (full 0):
def new generation total 3072K, used 2752K [0x33c80000, 0x33fd0000, 0x33fd0000)
eden space 2752K, 100% used [0x33c80000, 0x33f30000, 0x33f30000)
from space 320K, 0% used [0x33f30000, 0x33f30000, 0x33f80000)
to space 320K, 0% used [0x33f80000, 0x33f80000, 0x33fd0000)
tenured generation total 6848K, used 0K [0x33fd0000, 0x34680000, 0x34680000)
the space 6848K, 0% used [0x33fd0000, 0x33fd0000, 0x33fd0200, 0x34680000)
compacting perm gen total 12288K, used 143K [0x34680000, 0x35280000, 0x38680000)
the space 12288K, 1% used [0x34680000, 0x346a3c58, 0x346a3e00, 0x35280000)
ro space 10240K, 44% used [0x38680000, 0x38af73f0, 0x38af7400, 0x39080000)
rw space 12288K, 52% used [0x39080000, 0x396cdd28, 0x396cde00, 0x39c80000)
[GC[DefNew: 2752K->320K(3072K), 0.0014296 secs] 2752K->377K(9920K), 0.0014604 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap after GC invocations=1 (full 0):
def new generation total 3072K, used 320K [0x33c80000, 0x33fd0000, 0x33fd0000)
eden space 2752K, 0% used [0x33c80000, 0x33c80000, 0x33f30000)
from space 320K, 100% used [0x33f80000, 0x33fd0000, 0x33fd0000)
to space 320K, 0% used [0x33f30000, 0x33f30000, 0x33f80000)
tenured generation total 6848K, used 57K [0x33fd0000, 0x34680000, 0x34680000)
the space 6848K, 0% used [0x33fd0000, 0x33fde458, 0x33fde600, 0x34680000)
compacting perm gen total 12288K, used 143K [0x34680000, 0x35280000, 0x38680000)
the space 12288K, 1% used [0x34680000, 0x346a3c58, 0x346a3e00, 0x35280000)
ro space 10240K, 44% used [0x38680000, 0x38af73f0, 0x38af7400, 0x39080000)
rw space 12288K, 52% used [0x39080000, 0x396cdd28, 0x396cde00, 0x39c80000)
}
[GC[DefNew: 2752K->320K(3072K), 0.0014296 secs] 2752K->377K(9920K), 0.0014604 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-XX:+TraceClassLoading
监控类的加载
[Loaded java.lang.Object from shared objects file]
[Loaded java.io.Serializable from shared objects file]
[Loaded java.lang.Comparable from shared objects file]
[Loaded java.lang.CharSequence from shared objects file]
[Loaded java.lang.String from shared objects file]
[Loaded java.lang.reflect.GenericDeclaration from shared objects file]
[Loaded java.lang.reflect.Type from shared objects file]
-XX:+PrintClassHistogram
按下Ctrl+Break后,打印类的信息:
num #instances #bytes class name
----------------------------------------------
1: 890617 470266000 [B
2: 890643 21375432 java.util.HashMap$Node
3: 890608 14249728 java.lang.Long
4: 13 8389712 [Ljava.util.HashMap$Node;
5: 2062 371680 [C
6: 463 41904 java.lang.Class
分别显示:序号、实例数量、总大小、类型堆的分配参数
-Xmx –Xms
指定最大堆和最小堆
-Xmx20m -Xms5m
运行代码:
System.out.print("Xmx=");
System.out.println(Runtime.getRuntime().maxMemory()/1024.0/1024+"M");
System.out.print("free mem=");
System.out.println(Runtime.getRuntime().freeMemory()/1024.0/1024+"M");
System.out.print("total mem=");
System.out.println(Runtime.getRuntime().totalMemory()/1024.0/1024+"M");
打印:
Xmx=19.375M
free mem=4.342750549316406M
total mem=4.875M 当前可用的,分配到的大小
----------------------------
继续运行:
byte[] b=new byte[1*1024*1024];
System.out.println("分配了1M空间给数组");
打印:
分配了1M空间给数组
Xmx=19.375M
free mem=3.4791183471679688M
total mem=4.875M
Java会尽可能维持在最小堆,5m,当没有办法维持在5m,则会扩容
----------------------
b=new byte[4*1024*1024];
打印:
分配了4M空间给数组
Xmx=19.375M
free mem=3.5899810791015625M
total mem=9.00390625M
这时,总内存变多了
----------------------
System.gc();
打印:
回收内存
Xmx=19.375M
free mem=6.354591369628906M
total mem=10.75390625M
这时,空闲内存增多-Xmx 和 –Xms 应该保持一个什么关系,可以让系统的性能尽可能的好呢?
如果你要做一个Java的桌面产品,需要绑定JRE,但是JRE又很大,你如何做一下JRE的瘦身呢?
堆分配的其他参数
-Xmn
设置新生代大小
-XX:NewRatio
新生代(eden+2*s)和老年代(不包含永久区)的比值
4 表示 新生代:老年代=1:4,即年轻代占堆的1/5
-XX:SurvivorRatio
设置两个Survivor区和eden的比
8表示 两个Survivor :eden=2:8,即一个Survivor占年轻代的1/10
一个例子:
//运行程序
public static void main(String[] args) {
byte[] b=null;
for(int i=0;i<10;i++)
b=new byte[1*1024*1024];
}
打印模式:
-------1
-Xmx20m -Xms20m -Xmn1m -XX:+PrintGCDetails
结果:
1.没有触发GC
2.全部分配在老年代
-------2
-Xmx20m -Xms20m -Xmn15m -XX:+PrintGCDetails
结果:
1.没有触发GC
2.全部分配在eden
3.老年代没有使用代
--------3
-Xmx20m -Xms20m –Xmn7m -XX:+PrintGCDetails
结果:
1.进行了2次新生代GC
2.s0 s1 太小需要老年代担保
--------4
-Xmx20m -Xms20m -Xmn7m -XX:SurvivorRatio=2 -XX:+PrintGCDetails
结果:
1.进行了3次新生代GC
2.s0 s1 增大
--------5
-Xmx20m -Xms20m -XX:NewRatio=1
-XX:SurvivorRatio=2 -XX:+PrintGCDetails
结果:
1.进行了2次新生代GC
2.全部发生在新生代
--------6
-Xmx20m -Xms20m -XX:NewRatio=1
-XX:SurvivorRatio=3 -XX:+PrintGCDetails
--------7
运行结果:从上往下依次


其他的使用的参数
-XX:+HeapDumpOnOutOfMemoryError
OOM时导出堆到文件
-XX:+HeapDumpPath
导出OOM的路径
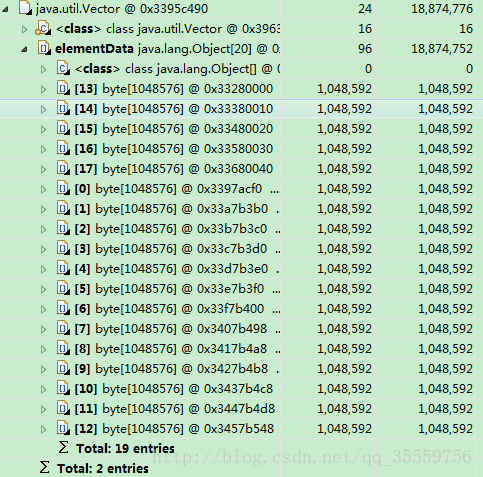
-Xmx20m -Xms5m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:/a.dump
Vector v=new Vector();
for(int i=0;i<25;i++)
v.add(new byte[1*1024*1024]);
-XX:OnOutOfMemoryError
在OOM时,执行一个脚本
"-XX:OnOutOfMemoryError=D:/tools/jdk1.7_40/bin/printstack.bat %p“
当程序OOM时,在D:/a.txt中将会生成线程的dump
可以在OOM时,发送邮件,甚至是重启程序
printstack.bat:D:/tools/jdk1.7_40/bin/jstack -F %1 > D:/a.txt
堆的分配参数-小结:
根据实际事情调整新生代和幸存代的大小
官方推荐新生代占堆的3/8
幸存代占新生代1/10
在OOM时,记得Dump出堆,确保可以排查现场问题
永久区的分配参数
-XX:PermSize -XX:MaxPermSize
设置永久区的初始空间和最大空间
他们表示,一个系统可以容纳多少个类型
(一般系统也就是几十M或者几百M)使用CGLIB等库的时候,可能会产生大量的类,这些类,有可能撑爆永久区导致OOM
for(int i=0;i<100000;i++){
CglibBean bean = new CglibBean("geym.jvm.ch3.perm.bean"+i,new HashMap());
}
不断产生新的类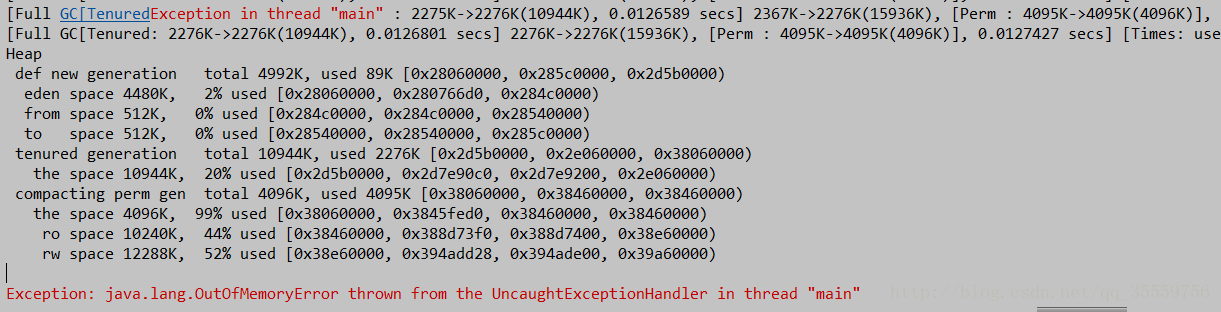
打开堆的Dump
堆空间实际占用非常少
但是永久区溢出 一样抛出OOM
如果堆空间没有用完也抛出了OOM,有可能是永久区导致的
栈的分配参数
栈大小分配
-Xss
通常只有几百K
决定了函数调用的深度
每个线程都有独立的栈空间
局部变量、参数 分配在栈上例子
public class TestStackDeep {
private static int count=0;
public static void recursion(long a,long b,long c){
long e=1,f=2,g=3,h=4,i=5,k=6,q=7,x=8,y=9,z=10;
count++;
recursion(a,b,c);
}
public static void main(String args[]){
try{
recursion(0L,0L,0L);
}catch(Throwable e){
System.out.println("deep of calling = "+count);
e.printStackTrace();
}
}
}
递归调用
-Xss128K
deep of calling = 701
java.lang.StackOverflowError
-Xss256K
deep of calling = 1817
java.lang.StackOverflowError疑问的补充:
1.
from和to其实只是一个逻辑概念,对于物理上来说,新生代其实就是分配对象的内存+待复制对象的内存空间
-XX:+PrintGCDetails
-XX:+PrintGCDetails这个是每次gc都会打印的,只是程序结束后才打印详细的堆信息
-Xmx不包含,持久代空间
堆空间是连续的
2.如果你要做一个Java的桌面产品,需要绑定JRE,但是JRE又很大,你如何做一下JRE的瘦身呢:
Java运行主要引赖于bin和Lib目录,bin目录主要存储了java命令和需要的dll
lib目录是java虚拟机要用到的class和配置文件。
bin目录精简的方式:
1、bin目录最主要的工具是java.exe,它用来执行class文件.
如果只是为了单纯运行Java程序的话,其他可执行文件一般都是用不到的(可剔除).
2、 bin目录里面的动态链接库文件dll是java.exe执行class文件过程中调用的.
执行class文件,java.exe需要哪个库文件就加载哪个dll,不需用的可以剔除.
查看java用到那个dll的,可以通过windows的任务管理器,查看进程号,再用其它工具(如360)
查看引用到的dll
lib精简方式:demo版
主要思想就是:
1、把程序运行所需要的class文件通过-XX:TraceClassLoading打印到文本文件
2、用自己写的程序把需要的class和rt路径,精简rt存放的路径设置好
3、然后将rt1里面的目录和文件打包成rt.zip,改名为rt.jar,然后替换原来的rt.jar
4、可以达到精简的作用,再将Java.exe和对应的dll copy到相应的目录,
5、写一个批处理命令,用于自带的Java去执行jar包。
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.jar.JarEntry;
import java.util.jar.JarFile;
import org.apache.commons.io.IOUtils;
public class CutJre {
private String needClazz = "d:\\needClazz.txt";//需要的class
private String rtPath = "D:\\Program Files\\Java\\jre6\\lib";//rt存放路径
private String dstRtPath = "D:/cutJar/";//精简后的路径
private JarFile rtJar;
public static void main(String[] args) throws Exception {
CutJre cutJre = new CutJre();
cutJre.rtJar = new JarFile(cutJre.rtPath + "\\rt.jar");
cutJre.copyClass("[Loaded sun.reflect.FieldAccessor from sda]");
// cutJre.execute();
}
private void execute() throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(needClazz)));
String string = br.readLine();
while (string != null) {
string = br.readLine();
}
}
private boolean copyClass(String traceStr) throws IOException {
if (traceStr.startsWith("[Loaded")) {
String className = traceStr.split(" ")[1];
//不是rt里面的Jar包,是自己有的
if(className.contains("zh")){
return true;
}
copyFile(className);
}
return false;
}
private void copyFile(String className) throws IOException {
String classFile = className.replace(".", "/") + ".class";
String classDir = classFile.substring(0,classFile.lastIndexOf("/"));
File dir=new File(dstRtPath+classDir);
System.out.println(dir);
if(!dir.exists()){
dir.mkdirs();
}
JarEntry jarEntry = rtJar.getJarEntry(classFile);
InputStream ins = rtJar.getInputStream(jarEntry);
File file = new File(dstRtPath+ classFile);
System.out.println(file);
if(!file.exists()){
file.createNewFile();
}
FileOutputStream fos = new FileOutputStream(file);
IOUtils.copy(ins, fos);
ins.close();
fos.close();
}
}
-Xmx 和 –Xms 应该保持一个什么关系,可以让系统的性能尽可能的好呢?
-Xms25m -Xmx40m -Xmn7m -XX:+PrintGCDetails -XX:PermSize=16m
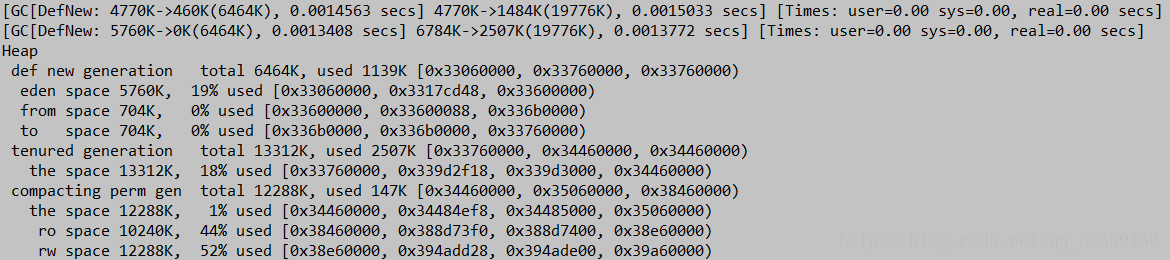
首先 def new generation total 6464K, used 115K [0x34e80000, 0x35580000, 0x35580000)
eden space 5760K, 2% used [0x34e80000, 0x34e9cd38, 0x35420000)
from space 704K, 0% used [0x354d0000, 0x354d0000, 0x35580000)
to space 704K, 0% used [0x35420000, 0x35420000, 0x354d0000)
通过这一行可以知道年轻代大小是7m.
通过 tenured generation total 18124K, used 8277K [0x35580000, 0x36733000, 0x37680000)
(0x37680000-0x35580000)/1024/1024得到的结果是33m
通过以上可以得到最大堆是40m。但通过eden大小和 tenured generation total 18124K计算出最小堆应该是25m
通过compacting perm gen total 16384K, 可以计算出持久堆-XX:PermSize=16mGC算法和种类
GC的概念
Garbage Collection垃圾回收
1960年list使用了GC
java中,gc的对象是堆空间和永久区
GC的算法
引用计数法
老牌垃圾回收算法
通过引用计算来回收垃圾
使用者:
COM
ActionScript3
Python
实现原理:
对于一个对象A,只要有任何一个对象引用了A,则A的引用计数器就加1,当引用失效时,引用计数器就减一。只要对象A的引用计数器的值为0,则对象就不可能在被使用。
(注:其他对象引用该对象时,该对象的计数器会自加一,其他对象的引用失效时,该对象的计数器自减一,当该对象的计数器为0时且时间悬空时,GC会自动回收该对象。)
引用计数法的问题:
引用的算法伴随着加法和减法,会影响性能
很难处理循环引用
标记-清除
概念:
标记-清除算法是现代垃圾回收算法的思想基础。标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。一种可行的实现是,在标记阶段,首先通过根节点,标记所有从根节点开始的可达对象。因此,未被标记的对象就是未被引用的垃圾对象。然后,在清除阶段,清除所有未被标记的对象。
(标记-清除将垃圾回收细分为标记阶段和清除阶段两个阶段,标记阶段,在引用节点树中,通过对象的根节点,标记所有可标记的对象,而没有标记的对象称为垃圾对象,清除阶段,在引用对象树中,当未有标记时,清除对象。)
标记-压缩
概念:
适合于存活对象多较多的场景,如老年代。在标记清除算法上做了优化,标记和压缩,标记阶段,从根节点开始标记所有可标记的对象,但是真正回收垃圾阶段不是直接通过根节点检测未被标记的对象就去清除,而是将所有的存活对象压缩(复制)到内存另一端,当内存不够下次使用时,清理边界外所有空间。
标记压缩对标记清除而言,有什么优势?
复制算法
概念:
与标记清除算法相比,复制算法是一种相对高效的回收方法。
不适合于存活对象较多的场合,如老年代
将原有的内存空间分为两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中存活对象复制到未使用的内存块中,之后,清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收
两块空间完全相同,每次只用一块
复制算法最大的问题是:空间浪费,整合了标记算法的思想
老年代:多次回收都未被回收,每次回收年龄加一,长期有效的对象
例子:
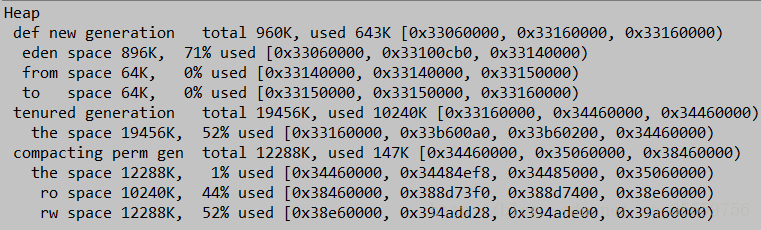
-XX:+PrintGCDetails的输出
Heap
def new generation total 13824K, used 11223K [0x27e80000, 0x28d80000, 0x28d80000)
eden space 12288K, 91% used [0x27e80000, 0x28975f20, 0x28a80000)
from space 1536K, 0% used [0x28a80000, 0x28a80000, 0x28c00000)
to space 1536K, 0% used [0x28c00000, 0x28c00000, 0x28d80000)
tenured generation total 5120K, used 0K [0x28d80000, 0x29280000, 0x34680000)
the space 5120K, 0% used [0x28d80000, 0x28d80000, 0x28d80200, 0x29280000)
compacting perm gen total 12288K, used 142K [0x34680000, 0x35280000, 0x38680000)
the space 12288K, 1% used [0x34680000, 0x346a3a90, 0x346a3c00, 0x35280000)
ro space 10240K, 44% used [0x38680000, 0x38af73f0, 0x38af7400, 0x39080000)
rw space 12288K, 52% used [0x39080000, 0x396cdd28, 0x396cde00, 0x39c80000)
看这三个部分:
total=12288K+ 1536K
(0x28d80000-0x27e80000)/1024/1024=15M
(0x28d80000-0x27e80000)/1024/1024=15M
def 新生代空间
from,to 复制算法中的两块空间,大小保持相等
分代思想:
依据对象的存活周期进行分类,短命对象归为新生代,长命对象归为老年代。
依据不同代的特点,选取合适的收集算法
少量对象存活,适合复制算法 新生代对象存货量低
大量对象存活,适合标记清理和标记压缩(对象经过多次GC都没有被回收,对象是长期存活的)
GC算法小结
引用计数
没有被Java采用,因为单纯的使用不能处理循环引用问题
标记-清除
标记-压缩
复制算法
新生代
所有的算法,需要能够识别一个垃圾对象,因此需要给出一个可触及性的定义。
什么是垃圾对象?引出几个概念:
可触及性
概念:
可触及的:
现在是不能触及的,但是有以后有可能触及的
从根节点可以触及到这个对象
可复活性:
一旦所有引用被释放,就是可复活状态
因为在finalize()中可能复活该对象
不可触及的:
在finalize()后,可能会进入不可触及状态
不可触及的对象不可能复活
可以回收
案例:
public class CanReliveObj {
public static CanReliveObj obj;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("CanReliveObj finalize called");
obj=this;
}
@Override
public String toString(){
return "I am CanReliveObj";
}
public static void main(String[] args) throws
InterruptedException{
obj=new CanReliveObj();
obj=null; //可复活 对象置空就表示可以回收的
System.gc();//通常是null值对象gc后就消失了,gc()会调用finalized(),所以又赋值引用该对象本身了,所以没有被回收掉,复活
Thread.sleep(1000);
if(obj==null){
System.out.println("obj 是 null");
}else{
System.out.println("obj 可用");
}
System.out.println("第二次gc");
obj=null; //不可复活 finallized()只会调用一次, 这里引出一个问题:如果没有设置该对象为null的话,该对象将永远不会被回收
System.gc();
Thread.sleep(1000);
if(obj==null){
System.out.println("obj 是 null");
}else{
System.out.println("obj 可用");
}
}
}
CanReliveObj finalize called
obj 可用
第二次gc
obj 是 null可触及性小结:
经验:避免使用finnalize(),操作不慎可能导致错误
优先级低,何时被调用,不确定
何时发生GC不确定
可以使用try-catch-finally来代替它
根:
栈中引用的对象(当前调用函数中的引用对象)
方法区中静态成员或者常量引用的对象(全局对象(任何时候都能被任何对象使用))
JNI方法栈中引用对象
Stop-The-World
概念:
Java中一种全局暂停的现象
全局停顿,所有Java代码停止,native代码可以执行,但不能和JVM交互,JVM处于挂起状态,不能处理应用层的代码
多半由于GC引起
Dump线程
死锁检查
堆Dump
GC时为什么会有全局停顿:
例子:
在聚会时打扫房间,聚会时很乱,又有新的垃圾产生,房间永远打扫不干净,只有让大家停止活动了,才能将房间打扫干净。
危害:
长时间服务停止,没有响应
遇到HA系统,可能引起主备切换,严重危害生产环境。主机长期没有响应就会启动备机,一段时间后,会导致主备同时处于启动状态
每秒打印10条
public static class PrintThread extends Thread{
public static final long starttime=System.currentTimeMillis();
@Override
public void run(){
try{
while(true){
long t=System.currentTimeMillis()-starttime;
System.out.println("time:"+t);
Thread.sleep(100);
}
}catch(Exception e){
}
}
}public static class MyThread extends Thread{
HashMap map=new HashMap();
@Override
public void run(){
try{
while(true){
if(map.size()*512/1024/1024>=450){
//大于450M时,清理内存
System.out.println(“=====准备清理=====:"+map.size());
map.clear();
}
//工作线程,消耗内存
for(int i=0;i<1024;i++){
map.put(System.nanoTime(), new byte[512]);
}
Thread.sleep(1);
}
}catch(Exception e){
e.printStackTrace();
}
}
}
启动:
-Xmx512M -Xms512M -XX:+UseSerialGC -Xloggc:gc.log -XX:+PrintGCDetails -Xmn1m -XX:PretenureSizeThreshold=50 -XX:MaxTenuringThreshold=1
运行结果:
time:2018
time:2121
time:2221
time:2325
time:2425
time:2527
time:2631
time:2731
time:2834
time:2935
time:3035
time:3153
time:3504
time:4218
======before clean map=======:921765
time:4349
time:4450
time:4551
GC情况:
3.292: [GC3.292: [DefNew: 959K->63K(960K), 0.0024260 secs] 523578K->523298K(524224K), 0.0024879 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
3.296: [GC3.296: [DefNew: 959K->959K(960K), 0.0000123 secs]3.296: [Tenured: 523235K->523263K(523264K), 0.2820915 secs] 524195K->523870K(524224K), [Perm : 147K->147K(12288K)], 0.2821730 secs] [Times: user=0.26 sys=0.00, real=0.28 secs]
3.579: [Full GC3.579: [Tenured: 523263K->523263K(523264K), 0.2846036 secs] 524159K->524042K(524224K), [Perm : 147K->147K(12288K)], 0.2846745 secs] [Times: user=0.28 sys=0.00, real=0.28 secs]
3.863: [Full GC3.863: [Tenured: 523263K->515818K(523264K), 0.4282780 secs] 524042K->515818K(524224K), [Perm : 147K->147K(12288K)], 0.4283353 secs] [Times: user=0.42 sys=0.00, real=0.43 secs]
4.293: [GC4.293: [DefNew: 896K->64K(960K), 0.0017584 secs] 516716K->516554K(524224K), 0.0018346 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
……省略若干…..
4.345: [GC4.345: [DefNew: 960K->960K(960K), 0.0000156 secs]4.345: [Tenured: 522929K->12436K(523264K), 0.0781624 secs] 523889K->12436K(524224K), [Perm : 147K->147K(12288K)], 0.0782611 secs] [Times: user=0.08 sys=0.00, real=0.08 secs] 补充:
垃圾回收算法:为让stw时间较长,增大年老代空间和选用serial old垃圾算法进行回收老年代
jvm垃圾回收参数:-Xms512m -Xmx512m -Xmn4m -XX:+PrintGCDetails -XX:+UseSerialGC
尽可能减少一次STW停顿时间?由此带来的弊端是什么?
减少一次STW停顿时间,我这里从三个方面回答,一个是垃圾算法选择,一个是程序使用堆设置,无用对象尽早释放
垃圾算法选择:现在都是多核cpu,可以采用并行和并发收集器,如果是响应时间优化的系统应用 ,则jdk6版本一般
选择的垃圾回收算法是:XX:+UseConcMarkSweepGC,即cms收集器,这个收集器垃圾回收时间短,但是垃圾回收总时间变长,使的降低吞
吐量,算法使用的是标记-清除,并发收集器不对内存空间进行压缩,整理,所以运行一段时间以后会产生”碎片”,使得运行效率降低.
CMSFullGCsBeforeCompaction此值设置运行多少次GC以后对内存空间进行压缩,整理
程序使用堆设置:应该根据程序运行情况,通过Jvm垃圾回收分析,设置一个比较合适的堆大小,不能一意味的将堆设置过大,导致
程序回收很大一块空间,所以会导致stw时间较长,
无用对象尽早释放:使用的对象,如果没有用,尽早设置null,尽量在年轻代将对象进行回收掉,可以减少full gc停顿时长
GC参数
串行收集器
概念:
最古老,最稳定
效率高
可能会产生较长的停顿,单线程进行回收,在多核上无法充分利用资源
-XX:+UseSerialGC
新生代、老年代使用串行回收
新生代复制算法
老年代标记-压缩
运行时期:
流程:
应用程序线程(多个)————->GC线程应用程序暂停(单个)——->应用程序线程(多个)
log:
0.844: [GC 0.844: [DefNew: 17472K->2176K(19648K), 0.0188339 secs] 17472K->2375K(63360K), 0.0189186 secs][Times: user=0.01 sys=0.00, real=0.02 secs]
8.259: [Full GC 8.259: [Tenured: 43711K->40302K(43712K), 0.2960477 secs] 63350K->40302K(63360K), [Perm : 17836K->17836K(32768K)], 0.2961554 secs][Times: user=0.28 sys=0.02, real=0.30 secs]
并行收集器
概念:
ParNew
-XX:+UseParNewGC
新生代并行
老年代串行
Serial收集器新生代的并行版本
复制算法
多线程,需要多核支持
-XX:ParallelGCThreads 限制线程数量
应用程序线程(多)——>GC线程 多线程并发 应用程序暂停(多)——>应用程序线程
但是多线程不一定块,多cpu多核才快,
0.834: [GC 0.834: [ParNew: 13184K->1600K(14784K), 0.0092203 secs] 13184K->1921K(63936K), 0.0093401 secs][Times: user=0.00 sys=0.00, real=0.00 secs]
Parallel收集器
类似ParNew
新生代复制算法
老年代 标记-压缩
更加关注吞吐量
-XX:+UseParallelGC
使用Parallel收集器+ 老年代串行
-XX:+UseParallelOldGC
使用Parallel收集器+ 并行老年代
运行时期流程:
应用程序线程(多)—>GC线程多线程并发 应用程序暂停(多)—->应用程序线程
log:
1.500: [Full GC [PSYoungGen: 2682K->0K(19136K)] [ParOldGen: 28035K->30437K(43712K)] 30717K->30437K(62848K) [PSPermGen: 10943K->10928K(32768K)], 0.2902791 secs][Times: user=1.44 sys=0.03, real=0.30 secs]
一些其他的参数:
-XX:MaxGCPauseMills
最大停顿时间,单位毫秒
GC尽力保证回收时间不超过设定值
-XX:GCTimeRatio 吞吐量---》决定系统性能---》cpu资源分配到应用层或者GC层
0-100的取值范围
垃圾收集时间占总时间的比
默认99,即最大允许1%时间做GC
这两个参数是矛盾的。因为停顿时间和吞吐量不可能同时调优
CMS收集器
概念:
Concurrnet Mark Sweep并发标记清除
并发:与用户线程一起执行
标记-清除算法
与标记-压缩相比
并发阶段会降低吞吐量
-XX:+UseConcMarkSweepGC
CMS**运行过程**比较复杂,着重实现了标记的过程:
初始标记(产生全局停顿,速度极快)
根可以直接关联到的对象
速度快
并发标记(和用户线程一起)
主要标记过程,标记全部对象
重新标记(产生停顿)
由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正
并发清除(和用户线程一起)
基于标记结果,直接清理对象
基本情况:
应用程序线程(多)—->初始标记(单)—->并发标记(多)—->重新标记(多)—->并发清理(多)——>并发重置(多)
———–>应用程序线程———>CMS线程
算法:清除,而非清除-压缩
log
1.662: [GC [1 CMS-initial-mark: 28122K(49152K)] 29959K(63936K), 0.0046877 secs][Times: user=0.00 sys=0.00, real=0.00 secs] 1.666: [CMS-concurrent-mark-start]1.699: [CMS-concurrent-mark: 0.033/0.033 secs][Times: user=0.25 sys=0.00, real=0.03 secs] 1.699: [CMS-concurrent-preclean-start]1.700: [CMS-concurrent-preclean: 0.000/0.000 secs][Times: user=0.00 sys=0.00, real=0.00 secs] 1.700: [GC[YG occupancy: 1837 K (14784 K)]1.700: [Rescan (parallel) , 0.0009330 secs]1.701: [weak refs processing, 0.0000180 secs] [1 CMS-remark: 28122K(49152K)] 29959K(63936K), 0.0010248 secs][Times: user=0.00 sys=0.00, real=0.00 secs] 1.702: [CMS-concurrent-sweep-start]1.739: [CMS-concurrent-sweep: 0.035/0.037 secs][Times: user=0.11 sys=0.02, real=0.05 secs] 1.739: [CMS-concurrent-reset-start]1.741: [CMS-concurrent-reset: 0.001/0.001 secs][Times: user=0.00 sys=0.00, real=0.00 secs]
特点:
尽可能降低停顿
会影响系统整体吞吐量和性能
比如,在用户线程运行过程中,分一半CPU去做GC,系统性能在GC阶段,反应速度就下降一半
清理不彻底
因为在清理阶段,用户线程还在运行,会产生新的垃圾,无法清理
因为和用户线程一起运行,不能在空间快满时再清理
-XX:CMSInitiatingOccupancyFraction设置触发GC的阈值(当占用到了百分之多少的时候就会触发硬性gc)
如果不幸内存预留空间不够,就会引起concurrent mode failure
例子:
33.348: [Full GC 33.348: [CMS33.357: [CMS-concurrent-sweep: 0.035/0.036 secs][Times: user=0.11 sys=0.03, real=0.03 secs]
(concurrent mode failure): 47066K->39901K(49152K), 0.3896802 secs] 60771K->39901K(63936K), [CMS Perm : 22529K->22529K(32768K)], 0.3897989 secs][Times: user=0.39 sys=0.00, real=0.39 secs]
使用串行收集器作为后备
有关碎片:
标记-清除和标记-压缩
| 0 | 0 | |||
|---|---|---|---|---|
| 0 | ||||
| 0 | ||||
| 0 |
标记-清除,如上,,很容易产生碎片,无法申请连续单位空间[数组]
| 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|
标记-压缩,如上,没有碎片的产生
cms更关注吞吐量(停顿复制)且与应用程序并行(安全)
cms如何处理碎片问题呢?
-XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次整理
整理过程是独占的,会引起停顿时间变长
-XX:+CMSFullGCsBeforeCompaction
设置进行几次Full GC后,进行一次碎片整理
-XX:ParallelCMSThreads
设定CMS的线程数量(一般为可用CPU的数量)为了减轻GC压力,程序员需要注意什么:
软件如何设计架构
代码如何写
堆空间如何分配
GC参数整理:
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:SurvivorRatio:设置eden区大小和survivior区大小的比例
-XX:NewRatio:新生代和老年代的比
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器
-XX:+UseParallelOldGC:老年代使用并行回收收集器
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器
-XX:ParallelCMSThreads:设定CMS的线程数量
-XX:CMSInitiatingOccupancyFraction:设置CMS收集器在老年代空间被使用多少后触发
-XX:+UseCMSCompactAtFullCollection:设置CMS收集器在完成垃圾收集后是否要进行一次内存碎片的整理
-XX:CMSFullGCsBeforeCompaction:设定进行多少次CMS垃圾回收后,进行一次内存压缩
-XX:+CMSClassUnloadingEnabled:允许对类元数据进行回收
-XX:CMSInitiatingPermOccupancyFraction:当永久区占用率达到这一百分比时,启动CMS回收
-XX:UseCMSInitiatingOccupancyOnly:表示只在到达阀值的时候,才进行CMS回收
Tomcat实例演示
环境:
Tomcat 7
JSP 网站
测试网站吞吐量和延时
工具:
JMeter
目的:
让Tomcat有一个不错的吞吐量
系统结构:
Tomcat——-JMeter(JVM机,不放在同一台机器上,放置JMeter对Tomcat的运行产生影响)
局域网连接
Jmeter
性能测试工具
建立10个线程,每个线程请求Tomcat 1000次共10000次请求
测试:
——————————–1
JDK6:使用32M堆处理请求
参数:
set CATALINA_OPTS=-server -Xloggc:gc.log -XX:+PrintGCDetails -Xmx32M -Xms32M -XX:+HeapDumpOnOutOfMemoryError -XX:+UseSerialGC -XX:PermSize=32M
现象:
Throughput(吞吐量):540/sec
perm:321768k
———————————–2
JDK6:使用最大堆512M堆处理请求
参数:
set CATALINA_OPTS=-Xmx512m -XX:MaxPermSize=32M -Xloggc:gc.log -XX:+PrintGCDetails
现象:throughput:651/sec
perm:15872k—–>60456k (从16M增长到60M)
结果:FULL GC很少,基本上是Minor GC
———————————3
JDK6:使用最大堆512M堆处理请求
参数:
set CATALINA_OPTS=-Xmx512m -Xms64m -XX:MaxPermSize=32M -Xloggc:gc.log -XX:+PrintGCDetails
现象:
DefNew:19119k->1578k(19712k)
throughput:674/sec
结果 GC数量减少 大部分是Minor GC
——————————–4
JDK6:使用最大堆512M堆处理请求
参数:
set CATALINA_OPTS=-Xmx512m -Xms64m -XX:MaxPermSize=32M -Xloggc:gc.log -XX:+PrintGCDetails -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:ParallelGCThreads=4
现象:
Throughput:669/sec
结果:GC压力原本不大,修改GC方式影响很小
———————————5
JDK 6
set CATALINA_OPTS=-Xmx40m -Xms40m -XX:MaxPermSize=32M -Xloggc:gc.log -XX:+PrintGCDetails
减小堆大小,增加GC压力,使用Serial回收器
现象:ThroughPut:646/sec
————————————6
JDK 6
set CATALINA_OPTS=-Xmx40m -Xms40m -XX:MaxPermSize=32M -Xloggc:gc.log -XX:+PrintGCDetails -XX:+UseParallelOldGC -XX:ParallelGCThreads=4
减小堆大小,增加GC压力,使用并行回收器
现象:
Throughput:685/sec
———————————-7
JDK 6
set CATALINA_OPTS=-Xmx40m -Xms40m -XX:MaxPermSize=32M -Xloggc:gc.log -XX:+PrintGCDetails -XX:+UseParNewGC
减小堆大小,增加GC压力,使用ParNew回收器
现象:ThroughPut:660/sec
———————————–8
启动Tomcat 7
使用JDK6
不加任何参数启动测试
现象:Throughput:622/sec
————————————9
启动Tomcat 7
使用JDK7
不加任何参数启动测试
现象:
Throughput:680/sec
结果:升级JDK可能会带来额外的性能提升!不要忽视JDK的版本
小结
性能的根本在应用
GC参数属于微调
设置不合理,会影响性能,产生大的延时
类哉器
class装载验证流程
加载
(将类加载都虚拟机中)
装载类的第一个阶段
取得类的二进制流
转为方法区数据结构在Java堆中生成对应的java.lang.Class对象
链接
验证
目的:保证Class流的格式是正确的
文件格式的验证
是否以0xCAFEBABE开头(咖啡杯)
版本号是否合理(编译器环境版本==运行期环境版本)
元数据验证(检查基本语法和基本语义)
是否有父类
继承了final类?(不可继承)
非抽象类实现了所有的抽象方法
字节码验证 (很复杂)
运行检查
(操作树)栈数据类型和操作码数据参数吻合
跳转指令指定到合理的位置(会跳转到字节码的偏移量上去)
符号引用验证:
常量池中描述类是否存在(继承、实现关联的类)
访问的方法或字段是否存在且有足够的权限(public、protect、private 对应相应的权限)
准备
分配内存,并为类设置初始值 (方法区中)
public static int v=1;
在准备阶段中,v会被设置为0
在初始化的中才会被设置为1
对于static final类型,在准备阶段就会被赋上正确的值
public static final int v=1;
解析
符号引用(字符串)替换为直接引用
符号引用:字符串引用对象不一定被加载
直接引用:指针或者地址偏移量引用对象一定在内存
初始化
执行类构造器(线程安全的)
static变量 赋值语句
static{}语句
子类的调用前保证父类的被调用
是线程安全的
问题:
Java.lang.NoSuchFieldError错误可能在什么阶段抛出
什么是类装载器ClassLoader
ClassLoader是一个抽象类
ClassLoader的实例将读入Java字节码将类装载到JVM中
ClassLoader可以定制,满足不同的字节码流获取方式(网络、文件途径)
ClassLoader负责类装载过程中的加载阶段
JDK中ClassLoader默认设计模式(工作模式)
ClassLoader的重要方法:
public Class
Class c = findLoadedClass(name);
...
if(parent != null){
c = parent.loadClass(name,false);
}else{
c =findBootstrapClassOrNull(name);
} 例子:
public class HelloLoader {
public void print(){
System.out.println("I am in apploader");
}
}
public class FindClassOrder {
public static void main(String args[]){
HelloLoader loader=new HelloLoader();
loader.print();
}
}
同时在d:/tmp/clz放置下面这个类
public class HelloLoader {
public void print(){
System.out.println("I am in bootloader");
}
}
测试:
直接运行以上代码:
打印:I am in apploader
加上参数 -Xbootclasspath/a:D:/tmp/clz
打印:I am in bootloader
此时AppLoader中不会加载HelloLoader
I am in apploader 在classpath中却没有加载
说明类加载是从上往下的(b->e->a->c)如果是你已经写好的系统,如何保证他人不能像上面那样修改你的系统呢?
方法:强制在apploader中加载
public static void main(String args[]) throws Exception {
//拿到 app classload
ClassLoader cl=FindClassOrder2.class.getClassLoader();
//加载类
byte[] bHelloLoader=loadClassBytes("geym.jvm.ch6.findorder.HelloLoader");
//获取方法
Method md_defineClass=ClassLoader.class.getDeclaredMethod("defineClass", byte[].class,int.class,int.class);
//以防权限问题,手动设置为可访问的权限
md_defineClass.setAccessible(true);
//加载类
md_defineClass.invoke(cl, bHelloLoader,0,bHelloLoader.length);
//设置会访问权限为false
md_defineClass.setAccessible(false);
//构造对象实例
HelloLoader loader = new HelloLoader();
//打印该实例的加载器信息 System.out.println(loader.getClass().getClassLoader());
//调用该实例的方法
loader.print();
}
关键代码:md_defineClass.invoke(cl, bHelloLoader,0,bHelloLoader.length);从底层开始查找,在application中就能找到该类
测试:
-Xbootclasspath/a:D:/tmp/clz
打印:
I am in apploader
结论:
在查找类的时候,先在底层的Loader查找,是从下往上的。Apploader能找到,就不会去上层加载器加载
抛出一个问题:
能否只用反射,仿照上面的写法,将类注入启动ClassLoader呢?
默认设计模式的问题
ClassLoader Architecture:
1.Bootstarp ClassLoader 2.Extension ClassLoader 3.App ClassLoader 4.Customer ClassLoader
1->4:自顶向底尝试加载类 4<-1:自底向顶检查类是否被加载
这种双亲模式的问题:
顶层ClassLoader-b 无法加载底层ClassLoader-c的类
Java框架(rt.jar)如何加载应用的类?
javax.xml.parsers包中定义了xml解析的类接口Service Provider Interface SPI 位于rt.jar 即接口在启动ClassLoader中。而SPI的实现类,在AppLoader。
如何解决?
Thread. setContextClassLoader()
上下文加载器
是一个角色
用以解决顶层ClassLoader无法访问底层ClassLoader的类的问题
基本思想是,在顶层ClassLoader中,传入底层ClassLoader的实例
代码实现:
static private Class getProviderClass(String className, ClassLoader cl,
boolean doFallback, boolean useBSClsLoader) throws ClassNotFoundException
{
try {
if (cl == null) {
if (useBSClsLoader) {
return Class.forName(className, true, FactoryFinder.class.getClassLoader());
} else {
cl = ss.getContextClassLoader();
if (cl == null) {
throw new ClassNotFoundException();
}
else {
return cl.loadClass(className); //使用上下文ClassLoader
}
}
}
else {
return cl.loadClass(className);
}
}
catch (ClassNotFoundException e1) {
if (doFallback) {
// Use current class loader - should always be bootstrap CL
return Class.forName(className, true, FactoryFinder.class.getClassLoader());
}
…..
补充:
代码来自javax.xml.parsers.FactoryFinder
展示如何在启动类加载器加载AppLoader的类
上下文ClassLoader可以突破双亲模式的局限性结论:
双亲模式的破坏
双亲模式是默认的模式,但不是必须这么做Tomcat的WebappClassLoader 就会先加载自己的Class,找不到再委托parent
OSGi的ClassLoader形成网状结构,根据需要自由加载Class
破坏双亲模式例子:
破坏双亲模式例子- 先从底层ClassLoader加载
OrderClassLoader的部分实现
loadClass方法:
protected synchronized Class loadClass(String name, boolean resolve) throws ClassNotFoundException {
// First, check if the class has already been loaded
Class re=findClass(name);
if(re==null){
System.out.println(“无法载入类:”+name+“ 需要请求父加载器");
return super.loadClass(name,resolve);
}
return re;
}
findClass方法:
protected Class findClass(String className) throws ClassNotFoundException {
Class clazz = this.findLoadedClass(className);
if (null == clazz) {
try {
String classFile = getClassFile(className);
FileInputStream fis = new FileInputStream(classFile);
FileChannel fileC = fis.getChannel();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
WritableByteChannel outC = Channels.newChannel(baos);
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
省略部分代码
fis.close();
byte[] bytes = baos.toByteArray();
clazz = defineClass(className, bytes, 0, bytes.length);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
return clazz;
}
使用:
OrderClassLoader myLoader=new OrderClassLoader("D:/tmp/clz/");
Class clz=myLoader.loadClass("geym.jvm.ch6.classloader.DemoA");
System.out.println(clz.getClassLoader());
System.out.println("==== Class Loader Tree ====");
ClassLoader cl=myLoader;
while(cl!=null){
System.out.println(cl);
cl=cl.getParent();
}
log:
java.io.FileNotFoundException: D:\tmp\clz\java\lang\Object.class (系统找不到指定的路径。)
at java.io.FileInputStream.open(Native Method)
.....
at geym.jvm.ch6.classloader.ClassLoaderTest.main(ClassLoaderTest.java:7)
无法载入类:java.lang.Object需要请求父加载器
geym.jvm.ch6.classloader.OrderClassLoader@18f5824
==== Class Loader Tree ====
geym.jvm.ch6.classloader.OrderClassLoader@18f5824
sun.misc.Launcher$AppClassLoader@f4f44a
sun.misc.Launcher$ExtClassLoader@1d256fa
注意:
1.因为先从OrderClassLoader加载,找不到Object,之后使用appLoader加载Object
java.io.FileNotFoundException: D:\tmp\clz\java\lang\Object.class (系统找不到指定的路径。)
2.DemoA在ClassPath中,但由OrderClassLoader加载
无法载入类:java.lang.Object需要请求父加载器geym.jvm.ch6.classloader.OrderClassLoader@18f5824 引出另一个问题:
如果OrderClassLoader不重载loadClass(),只重载findClass,那么程序输出为
sun.misc.Launcher AppClassLoader@b23210====ClassLoaderTree====geym.jvm.ch6.classloader.OrderClassLoader@290fbcsun.misc.Launcher [email protected]$ExtClassLoader@f4f44a
DemoA由AppClassLoader加载
热替换
含义:
当一个class被替换后,系统无需重启,替换的类立即生效
例子:
geym.jvm.ch6.hot.CVersionA
public class CVersionA {
public void sayHello() {
System.out.println("hello world! (version A)");
}
}DoopRun 不停调用CVersionA . sayHello()方法,因此有输出:
hello world! (version A)
在DoopRun 的运行过程中,替换CVersionA 为:
public class CVersionA {
public void sayHello() {
System.out.println("hello world! (version B)");
}
}替换后, DoopRun 的输出变为
hello world! (version B)
(注:唉,本来这里都写好了,结果编辑器软件出问题了,导致再次重复写,所以下面省略掉一部分质量)
性能监控工具
系统性能监控
确定系统运行的整体状态,基本定位问题所在
Java自带的工具
查看Java程序运行细节,进一步定位问题
实战分析
案例问题
系统性能监控- linux:
uptime系统时间
运行时间
例子中为7分钟
连接数
每一个终端算一个连接
1,5,15分钟内的系统平均负载
运行队列中的平均进程数
top
同uptime
CPU内存
每个进程占CPU的情况
可以知道哪个程序占CPU最多
vmstat
可以统计系统的CPU,内存,swap,io等情况
CPU占用率很高,上下文切换频繁,说明系统有线程正在频繁切换
采样频率和采样次数
pidstat
细致观察进程
需要安装
sudo apt-get install sysstat
监控CPU
监控IO
监控内存
-p 指定进程 –u 监控CPU 每秒采样 次数 -t 显示线程
系统性能监控 - windows
任务管理器
PerfmonWindows
自带多功能性能监控工具
Process Explorer
pslist
命令行工具
可用于自动化数据收集
显示java程序的运行情况
jps
列出java进程,类似于ps命令
参数-q可以指定jps只输出进程ID ,不输出类的短名称
参数-m可以用于输出传递给Java进程(主函数)的参数
参数-l可以用于输出主函数的完整路径
参数-v可以显示传递给JVM的参数
jinfo
可以用来查看正在运行的Java应用程序的扩展参数,甚至支持在运行时,修改部分参数
-flag :打印指定JVM的参数值
-flag [+|-]:设置指定JVM参数的布尔值
-flag =:设置指定JVM参数的值
显示了新生代对象晋升到老年代对象的最大年龄
jinfo -flag MaxTenuringThreshold 2972-XX:MaxTenuringThreshold=15
显示是否打印GC详细信息
jinfo -flag PrintGCDetails 2972-XX:-PrintGCDetails
运行时修改参数,控制是否输出GC日志
jinfo -flag PrintGCDetails 2972-XX:-PrintGCDetailsjinfo -flag +PrintGCDetails 2972jinfo -flag PrintGCDetails 2972-XX:+PrintGCDetails
jmap
生成Java应用程序的堆快照和对象的统计信息
jmap -histo 2972 >c:\s.txt
Dump堆
jmap -dump:format=b,file=c:\heap.hprof 2972
jstack
打印线程dump
-l 打印锁信息
-m 打印java和native的帧信息
-F 强制dump,当jstack没有响应时使用
jstack 120 >>C:\a.txt
Java自带的工具 - JConsole:
JConsole
图形化监控工具
可以查看Java应用程序的运行概况,监控堆信息、永久区使用情况、类加载情况等
Visual VM
Visual VM是一个功能强大的多合一故障诊断和性能监控的可视化工具
性能监控:找到占用CPU时间最长的方法
分析堆Dump
Java堆分析:
内存溢出(OOM)的原因
在JVM中,有哪些内存区间:
堆,永久区,线程栈(操作系统分配JVM的一块内存区域),直接内存—-总大小不会超过操作系统分配的总的内存空间,一般32位不会超过2G,不能超过物理内存的大小,如果这些组成部分不能得到满足,就会造成OOM。
堆溢出:
public static void main(String args[]){
ArrayList<byte[]> list=new ArrayList<byte[]>();
for(int i=0;i<1024;i++){
list.add(new byte[1024*1024]);
}
}
程序占用大量堆空间,直接溢出
异常为:Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at geym.jvm.ch8.oom.SimpleHeapOOM.main(SimpleHeapOOM.java:14)
解决方法:增大堆空间,及时释放内存永久区:
生成大量的类
public static void main(String[] args) {
for(int i=0;i<100000;i++){
CglibBean bean = new CglibBean("geym.jvm.ch3.perm.bean"+i,new HashMap());
}
}
异常为:
Caused by: java.lang.OutOfMemoryError: PermGen space
[Full GC[Tenured: 2523K->2523K(10944K), 0.0125610 secs] 2523K->2523K(15936K),
[Perm : 4095K->4095K(4096K)], 0.0125868 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
Heap
def new generation total 4992K, used 89K [0x28280000, 0x287e0000, 0x2d7d0000)
eden space 4480K, 2% used [0x28280000, 0x282966d0, 0x286e0000)
from space 512K, 0% used [0x286e0000, 0x286e0000, 0x28760000)
to space 512K, 0% used [0x28760000, 0x28760000, 0x287e0000)
tenured generation total 10944K, used 2523K [0x2d7d0000, 0x2e280000, 0x38280000)
the space 10944K, 23% used [0x2d7d0000, 0x2da46cf0, 0x2da46e00, 0x2e280000)
compacting perm gen total 4096K, used 4095K [0x38280000, 0x38680000, 0x38680000)
the space 4096K, 99% used [0x38280000, 0x3867fff0, 0x38680000, 0x38680000)
ro space 10240K, 44% used [0x38680000, 0x38af73f0, 0x38af7400, 0x39080000)
rw space 12288K, 52% used [0x39080000, 0x396cdd28, 0x396cde00, 0x39c80000)
注意看:
PermGen space...4095K->4095K(4096K)..... 99% used
解决方法:
增大Perm区
允许Class回收Java栈溢出:
这里的栈溢出指,在创建线程的时候,需要为线程分配栈空间,这个栈空间是向操作系统请求的,如果操作系统无法给出足够的空间,就会抛出OOM
操作系统可分配=堆空间+线程栈空间
例子:
public static class SleepThread implements Runnable{
public void run(){
try {
Thread.sleep(10000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String args[]){
for(int i=0;i<1000;i++){
new Thread(new SleepThread(),"Thread"+i).start();
System.out.println("Thread"+i+" created");
}
}
启动:-Xmx1g -Xss1m
异常:
Exception in thread "main" java.lang.OutOfMemoryError:
unable to create new native thread
解决方法:
减少堆内存
减少线程栈大小
直接内存溢出:
ByteBuffer.allocateDirect()无法从操作系统获得足够的空间
操作系统可分配=堆空间+线程栈空间+直接内存
例子:
for(int i=0;i<1024;i++){
ByteBuffer.allocateDirect(1024*1024);
System.out.println(i);
System.gc(); //主动GC
}
启动:-Xmx1g -XX:+PrintGCDetails
异常:Exception in thread "main" java.lang.OutOfMemoryError
解决方法:
减少堆内存
有意触发GC
解决后的结果:
def....total ..k
eden 24% used
from 0%
to 0%
tenured total ...k
0% used
perm total ...k
13% used
这表示空间富足遇到内存溢出时如何处理?
MAT使用基础
Memory Analyzer(MAT)
基于Eclipse的软件
http://www.eclipse.org/mat/
柱状图显示,
显示每个类的使用情况,比如类的数量,所占空间等
显示支配树
显示入引用(incoming)和出引用(outgoing)
支配树
什么是支配树:
对象引用图:
a/b->c
c->e->g->h
c->d<->f->h
支配树:
空->a/b
空->c
c->d->f
c->e->g
c->h
被支配者最近的唯一指向者就是被支配者的支配者
在对象引用图中,所有指向对象B的路径都经过对象A,则认为对象A支配对象B如果对象A是离对象B最近的一个支配对象,则认为对象A为对象B的直接支配者
支配者被回收,被支配对象也被回收
显示线程信息
显示堆总体信息,比如消耗最大的一些对象等
显示一个对象引用的对象 显示引用这个对象的对象
浅堆(Shallow Heap)与深堆(Retained Heap)
浅堆:
一个对象结构所占用的内存大小
String-{value,offset,count,hash}
JDK7后,String结构发生变化
int-hash32-0,int-hash-1931082254,ref-value-null
3个int类型以及一个引用类型合计占用内存3*4+4=16个字节。再加上对象头的8个字节,因此String对象占用的空间,即浅堆的大小是16+8=24字节
对象大小按照8字节对齐
浅堆大小和对象的内容无关,只和对象的结构有关
深堆:
一个对象被GC回收后,可以真实释放的内存大小
只能通过对象访问到的(直接或者间接)所有对象的浅堆之和 (支配树)
例子:
public class Point{
private int x;
private int y;
pubic Point(int x,int y){
super();
this.x = x;
this.y = y;
}
}
public class Line{
private Point startPoint;
private Point endPoint;
public Line(Point startPoint,Point endPoint){
super();
this.startPoint = startPoint;
this.endPoint = endPoint;
}
}
public static void main(String args[]){
Point a = new Point(0,0);
Point b = new Point(1,1);
Point c = new Point(5,3);
Point d = new Point(9,8);
Point e = new Point(6,7);
Point f = new Point(3,9);
Point g = new Point(4,8);
Line aLine = new Line(a,b);
Line bLine = new Line(a,c);
Line cLine = new Line(d,e);
Line dLine = new Line(f,g);
a = null;
b = null;
c = null;
d = null;
e = null;
Thead.sleep(100000);
}现象:
[bac de]fg
aLine->ba
bLine->ac
cLine->de
dLine->fg
使用Visual VM分析堆
java自带的多功能分析工具,可以用来分析堆Dump
Tomcat OOM分析案例
Tomcat OOM
Tomcat 在接收大量请求时发生OOM,获取堆Dump文件,进行分析。
使用MAT打开堆
分析目的:找出OOM的原因
推测系统OOM时的状态
给出解决这个OOM的方法
…………….
解决方法:
OOM由于保存session过多引起,可以考虑增加堆大小
如果应用允许,缩短session的过期时间,使得session可以及时过期,并回收
锁
线程安全
多线程网站统计人数
使用锁,维护计数器的串行访问与安全性
多线程访问ArrayList
public static List numberList =new ArrayList();
public static class AddToList implements Runnable{
int startnum=0;
public AddToList(int startnumber){
startnum=startnumber;
}
@Override
public void run() {
int count=0;
while(count<1000000){
numberList.add(startnum);
startnum+=2;
count++;
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(new AddToList(0));
Thread t2=new Thread(new AddToList(1));
t1.start();
t2.start();
while(t1.isAlive() || t2.isAlive()){
Thread.sleep(1);
}
System.out.println(numberList.size());
} 结果:
Exception in thead “Thread-1” java.lang.ArrayIndexOutOfBoundsException:823 ……
1000000
对象头Mark
Mark Word ,对象头的标记,32位
描述对象的hash、锁信息,垃圾回收标记,年龄
指向锁记录的指针
指向monitor的指针
GC标记
偏向锁线程ID
偏向锁
大部分情况是没有竞争的,所以可以通过偏向来提高性能
所谓的偏向,就是偏心,即锁会偏向于当前已经占有锁的线程
将对象头Mark的标记设置为偏向,并将线程ID写入对象头Mark
只要没有竞争,获得偏向锁的线程,在景来进入同步块,不需要做同步
当其他线程请求相同的锁时,偏向模式结束
-XX:+UseBiasedLocking
默认启用
在竞争激烈的场合,偏向锁会增加系统负担
例子:
public static List numberList =new Vector();
public static void main(String[] args) throws InterruptedException {
long begin=System.currentTimeMillis();
int count=0;
int startnum=0;
while(count<10000000){
numberList.add(startnum);
startnum+=2;
count++;
}
long end=System.currentTimeMillis();
System.out.println(end-begin);
}
启动 :
-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
-XX:-UseBiasedLocking
结果:本例中,使用偏向锁,可以获得5%以上的性能提升 轻量级锁
BasicObjectLock
嵌入在线程栈中的对象
BasicObjectLock->ptr to obj hold the lock/BasicLock-----markOop _displaced_header普通的锁处理性能不够理想,轻量级锁是一种快速的锁定方法
如果对象没有被锁定
将对象头的Mark指针保存到锁对象中
将对象头设置为指向锁的指针(在线程栈空间中)
lock->set_displaced_header(mark);
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
lock处于线程栈中如果轻量级锁失败,表示存在竞争,升级为重量级锁(常规锁)
在没有锁竞争的前提下,减少传统锁使用OS互斥量产生的性能损耗
在竞争激烈时,轻量级锁会多做很多额外操作,导致性能下降
自旋锁
当竞争存在时,如果线程可以很快锁,那么可以不再OS层挂起线程,让线程多做几个空操作(自旋)
JDK1.6中-XX:+UseSpinning开启
JDK1.7中,去掉此参数,改为内置实现
如果同步块很长,自旋失败,会降低系统性能
如果同步块很短,自旋成功,节省线程挂起切换时间,提升系统性能
偏向锁、轻量级锁、自旋锁小结:
不是Java语言层面的锁优化方法
内置于JVM中的获取锁的优化方法和获取锁的步骤
偏向锁可用会先尝试偏向锁
轻量级锁可用会先尝试轻量级锁
以上都失败,尝试自旋锁
再失败,尝试普通锁,使用OS互斥量在操作系统层挂起
减少锁持有时间
//初始写法
public synchronized void syncMethod(){
othercode1();
mutextMethod();
othercode2();
}
//改进为
public void syncMethod2(){
othercode1();
synchronized(this){
mutextMethod();
}
othercode2();
}减少锁粒度
将大对象,拆成小对象,大大增加并行度,降低锁竞争
偏向锁,轻量级锁成功率提高
ConcurrentHashMap
HashMap的同步实现
Collections.synchronizedMap(Map
返回SynchronizedMap对象
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}ConcurrnetHashMap
若干个Segment:Segment
在减少锁粒度后,ConcurrentHashMap允许若干个线程同时进入
锁分离
根据功能进行锁分离
ReadWriteLock
读多写少的情况下,可以提高性能
| 读锁 | 写锁 |
|---|---|
| 读锁 | 可访问 |
| 写锁 | 不可访问 |
读写分离思想可以延伸,只要操作互不影响,锁就可以分离
LinkedBlockingQueue
队列
链表
take<—[a|b|c|d]<——put
锁粗化
通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完公共资源后,应该立即释放锁。只有这样,等待在这个锁上的其他线程才能尽早的获得资源执行任务。但是,凡事都有一个度,如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化
public void demoMethod(){
synchronized(lock){
//do sth.
}
//做其他不需要的同步的工作,但能很快执行完毕
synchronized(lock){
//do sth.
}
}
//改进为
public void demoMethod(){
//整合成一次锁请求
synchronized(lock){
//do sth.
//做其他不需要的同步的工作,但能很快执行完毕
}
}
//-----------------------------------
for(int i=0;ilock){
}
}
//改进为
synchronized(lock){
for(int i=0;i 锁消除
在即时编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作
public static void main(String args[]) throws InterruptedException {
long start = System.currentTimeMillis();
for (int i = 0; i < CIRCLE; i++) {
craeteStringBuffer("JVM", "Diagnosis");
}
long bufferCost = System.currentTimeMillis() - start;
System.out.println("craeteStringBuffer: " + bufferCost + " ms");
}
public static String craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
//同步操作
sb.append(s1);
sb.append(s2);
return sb.toString();
}
//-----------------
CIRCLE= 2000000
-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks
createStringBuffer: 187 ms
//--
-server -XX:+DoEscapeAnalysis -XX:-EliminateLocks
createStringBuffer: 254 ms无锁
锁时悲观的操作
无锁是乐观的操作
无锁是一种实现方式
CAS(Compare And Swap)
非阻塞的同步
CAS(V,E,N)
在应用层判断多线程的干扰,如果有干扰,则通知线程重试
java.util.concurrent.atomic.AtomicInteger
public final int getAndSet(int newValue) { //设置新值,返回旧值
for (;;) {
int current = get();
if (compareAndSet(current, newValue))
return current;
}
}
public final boolean compareAndSet(int expect,int update) 更新成功返回true
java.util.concurrent.atomic包使用无锁实现,性能高于一般的有锁操作Class文件架构
语言无关性
*.java,*.rb,*.groovy,其他JVM语言----->.class--->JVM文件结构
| 类型 | 名称 | 数量 |
|---|---|---|
| u4 | magic | 1 |
| u2 | minor_version | 1 |
| u2 | major_version | 1 |
| u2 | constant_pool_count | 1 |
| cp_info | constant_pool | constant_pool_count - 1 |
| u2 | access_flags | 1 |
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attribute_count | 1 |
| attribute_info | attributes | attributes_count |
magic u4
-0xCAFEBABE
minor_version_u2
major_version_u2
| JDK 编译器版本 | target 参数 | 十六进制 minor.major | 十进制 major.minor |
|---|---|---|---|
| jdk1.1.8 | 不能带 target 参数 | 00 03 00 2D | 45.3 |
| jdk1.2.2 | 不带(默认为 -target 1.1) | 00 03 00 2D | 45.3 |
| jdk1.2.2 | -target 1.2 | 00 00 00 2E | 46.0 |
| jdk1.3.1_19 | 不带(默认为 -target 1.1) | 00 03 00 2D | 45.3 |
| jdk1.3.1_19 | -target 1.3 | 00 00 00 2F | 47.0 |
| j2sdk1.4.2_10 | 不带(默认为 -target 1.2) | 00 00 00 2E | 46.0 |
| j2sdk1.4.2_10 | -target 1.4 | 00 00 00 30 | 48.0 |
| jdk1.5.0_11 | 不带(默认为 -target 1.5) | 00 00 00 31 | 49.0 |
| jdk1.5.0_11 | -target 1.4 -source 1.4 | 00 00 00 30 | 48.0 |
| jdk1.6.0_01 | 不带(默认为 -target 1.6) | 00 00 00 32 | 50.0 |
| jdk1.6.0_01 | -target 1.5 | 00 00 00 31 | 49.0 |
| jdk1.6.0_01 | -target 1.4 -source 1.4 | 00 00 00 30 | 48.0 |
| jdk1.7.0 | 不带(默认为 -target 1.6) | 00 00 00 32 | 50.0 |
| jdk1.7.0 | -target 1.7 | 00 00 00 33 | 51.0 |
| jdk1.7.0 | -target 1.4 -source 1.4 | 00 00 00 30 | 48.0 |
文件结构-常量池
constant_pool_count u2
constant_pool cp_info
| CONSTANT_Utf8 | 1 | UTF-8编码的Unicode字符串 |
|---|---|---|
| CONSTANT_Integer | 3 | int类型的字面值 |
| CONSTANT_Float | 4 | float类型的字面值 |
| CONSTANT_Long | 5 | long类型的字面值 |
| CONSTANT_Double | 6 | double类型的字面值 |
| CONSTANT_Class | 7 | 对一个类或接口的符号引用 |
| CONSTANT_String | 8 | String类型字面值的引用 |
| CONSTANT_Fieldref | 9 | 对一个字段的符号引用 |
| CONSTANT_Methodref | 10 | 对一个类中方法的符号引用 |
| CONSTANT_InterfaceMethodref | 11 | 对一个接口中方法的符号引用 |
| CONSTANT_NameAndType | 12 | 对一个字段或方法的部分符号引用 |
CONSTANT_Utf8
tag 1
length u2
bytes[length]
例:
length of byte array : 3
length of string : 3
String: 0r
CONSTANT_Integer
tag 3
byte u4
例:
public static final int sid = 99;
Bytes: 0x00000063
Integer: 99
CONSTANT_String
tag 8
string_index u2(指向utf8的索引)
例:
public static final String sname = “geym”;
String : cp info #16 —->[16] CONSTANT_Utf8_info Length of byte array :4 Length of string : 4 String :geym
CONSTANT_NameAndType
tag 12
name_index u2(名字,指向utf8)
descriptor_index u2(描述符类型,指向utf8)
例:
Name: cp_info #20 <>
Descriptor: cp info #21 <()V>
———1—->
Length of byte array: 6
Length of string : 6
String :
UTF-8
———2——>
Length of byte array: 3
Length of string: 3
String : ()V
UTF-8
CONSTANT_Class
tag 7
name_index u2(名字,指向utf8)
例:
Class name: cp info #6
CONSTANT_Fieldref,CONSTANT_Methodref,CONSTANT_InterfaceMethodref
tag 9,10,11
class_index u2(指向CONSTANT_Class)
name_and_type_index u2(指向CONSTANT_NameAndType)
例:
[Fieldref]————–
Class name: cp info #1
access flag u2: 类的标识符
| Flag Name | Value | Interpretation |
|---|---|---|
| ACC_PUBLIC | 0x0001 | public |
| ACC_FINAL | 0x0010 | final,不能被继承. |
| ACC_SUPER | 0x0020 | 是否允许使用invokespecial指令,JDK1.2后,该值为true |
| ACC_INTERFACE | 0x0200 | 是否是接口 |
| ACC_ABSTRACT | 0x0400 | 抽象类 |
| ACC_SYNTHETIC | 0x1000 | 该类不是由用户代码生成,运行时生成的,没有源码 |
| ACC_ANNOTATION | 0x2000 | 是否为注解 |
| ACC_ENUM | 0x4000 | 是否是枚举 |
this_class u2
指向常量池的Class
super_class u2
指向常量池的Class
interface_count u2
接口数量
interfacex
interface_count 个interface u2
每个interface是指向CONSTANT_Class的索引
field_count
字段数量
fields
field_count个field_info
field
access_flags u2
name_index u2
descriptor_index u2
attributes_count u2
attribute_info attributes[attributes_count];
文件结构-field
access_flags
| Flag Name | Value | Interpretation |
|---|---|---|
| ACC_PUBLIC | 0x0001 | public |
| ACC_PRIVATE | 0x0002 | private |
| ACC_PROTECTED | 0x0004 | protected |
| ACC_STATIC | 0x0008 | static. |
| ACC_FINAL | 0x0010 | final |
| ACC_VOLATILE | 0x0040 | volatile |
| ACC_TRANSIENT | 0x0080 | transient |
| ACC_SYNTHETIC | 0x1000 | synthetic; 没有源码,编译器生成 |
| ACC_ENUM | 0x4000 | 枚举类型 |
access_flags
| Flag Name | Value | Interpretation |
|---|---|---|
| ACC_PUBLIC | 0x0001 | public |
| ACC_PRIVATE | 0x0002 | private |
| ACC_PROTECTED | 0x0004 | protected |
| ACC_STATIC | 0x0008 | static. |
| ACC_FINAL | 0x0010 | final |
| ACC_VOLATILE | 0x0040 | volatile |
| ACC_TRANSIENT | 0x0080 | transient |
| ACC_SYNTHETIC | 0x1000 | synthetic; 没有源码,编译器生成 |
| ACC_ENUM | 0x4000 | 枚举类型 |
name_index u2
常量池引用,表示字段的名字
descriptor_index
表示字段的类型
B byte
C char
D double
F float
I int
J long
S short
Z boolean
V void
L 对象
Ljava/lang/Object;
[
数组 [[Ljava/lang/String; = String[][]文件结构-method
methods-count**
方法数量
methods
methods_count个method_info
method_info
access_flags u2
name_index u2
descriptor_index u2
attributes_count u2
attribute_info attributes[attributes_count];
access flag
| Flag Name | Value | Interpretation |
|---|---|---|
| ACC_PUBLIC | 0x0001 | public |
| ACC_PRIVATE | 0x0002 | private |
| ACC_PROTECTED | 0x0004 | protected |
| ACC_STATIC | 0x0008 | static |
| ACC_FINAL | 0x0010 | final |
| ACC_SYNCHRONIZED | 0x0020 | synchronized |
| ACC_BRIDGE | 0x0040 | 编译器产生 桥接方法 |
| ACC_VARARGS | 0x0080 | 可变参数 |
| ACC_NATIVE | 0x0100 | native |
| ACC_ABSTRACT | 0x0400 | abstract |
| ACC_STRICT | 0x0800 | strictfp |
| ACC_SYNTHETIC | 0x1000 | 不在源码中,由编译器产生 |
name_index u2
方法名字,常量池UTF-8索引
descriptor_index u2
描述符,用于表达方法的参数和返回值
方法描述符
void inc() ()V
void setId(int) (I)V
int indexOf(char[],int) ([CI)I
文件结构-attribute
在field和method中,可以有若干个attribute,类文件也有attibute,用于描述一些额外的信息
attribute_name_index u2
名字,指向常量池UTF-8
attirbute_length u4
长度
info[attribute_length] u1
内容
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attribute_count | 1 |
| attribute_info | attributes | attributes_count |
attibute本身也可以包含其他attibute
随着JDK的发展不断有新的attribute加入
| 名称 | 使用者 | 描述 |
|---|---|---|
| Deprecated | field method | 字段、方法、类被废弃 |
| ConstantValue | field | final常量 |
| Code | method | 方法的字节码和其他数据 |
| Exceptions | method | 方法的异常 |
| LineNumberTable | Code_Attribute | 方法行号和字节码映射 |
| LocalVaribleTable | Code_Attribute | 方法局部变量表描述 |
| SourceFile | Class file | 源文件名 |
| Synthetic | field method | 编译器产生的方法或字段 |
ConstantValue
attribute_name_index u2
attribute_length u4
constantvalue_index u2
attribute_name_index
包含ConstantValue字面量的UTF-8索引
attribute_length
为2
constantvalue_index
常量池,指向常量池,可以是UTF-8,Float,Double等
Code
Code_attribute {
//Code
u2 attribute_name_index;
u4 attribute_length;
u2 max_stack;
u2 max_locals;
//字节码长度和字节码
u4 code_length;
u1 code[code_length];
//异常表长度
u2 exception_table_length;
{
//异常处理的开始位置
u2 start_pc;
u2 end_pc;
//处理这个异常的字节码位置
u2 handler_pc;
//处理的异常类型,指向Constant_Class的指针
u2 catch_type;
} exception_table[exception_table_length];
//属性数量
u2 attributes_count;
attribute_info attributes[attributes_count];
}
LineNumberTable-Code属性的属性
LineNumberTable_attribute {
u2 attribute_name_index;//UTF-8常量池,字面量LineNumberTable
u4 attribute_length;
u2 line_number_table_length;//表项
{ u2 start_pc; //字节码偏移量和对应的行号
u2 line_number;
} line_number_table[line_number_table_length];
}
LocalVariableTable-Code属性的属性
LocalVariableTable_attribute {
u2 attribute_name_index;//UTF-8常量池,字面量LocalVariableTable
u4 attribute_length;
u2 local_variable_table_length;
{//局部变量作用域
u2 start_pc;
u2 length;
u2 name_index;
u2 descriptor_index;
u2 index; //局部变量名称和类型 局部变量的Slot位置
} local_variable_table[local_variable_table_length];
}
Exceptions属性
和Code属性平级
表示方法抛出的异常(不是try catch部分,而是throws部分)
结构
attribute_name_index u2
attribute_length u4
number_of_exceptions u2
exception_index_table[number_of_exceptions] u2
指向Constant_Class的索引
例:
public void setAge(int age) throws IOException{
try{
this.age = age;
}catch(IllegalStateException e){
this.age = 0;
}
}
SourceFile
描述生成Class文件的源码文件名称
结构
attribute_name_index u2
attribute_length u4
固定为2
soucefile_index u2
UTF-8常量索引
class文件结构例子
public class User {
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
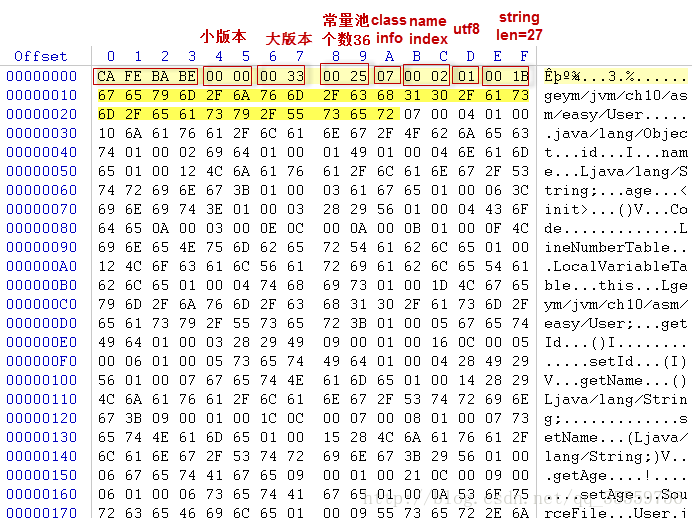


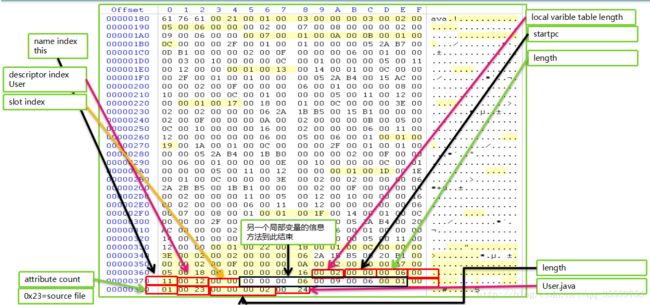
字节码执行
javap
class文件反编译工具
案例:
java代码:
先定义一个寄存器的类
public class Calc {
public int calc() {
int a = 500;
int b = 200;
int c = 50;
return (a + b) / c;
}
}
再反汇编这个类
指令:javap –verbose Calc
反汇编后的输出:
public int calc();
Code:
Stack=2, Locals=4, Args_size=1
0: sipush 500
3: istore_1
4: sipush 200
7: istore_2
8: bipush 50
10: istore_3
11: iload_1
12: iload_2
13: iadd
14: iload_3
15: idiv
16: ireturn
}
0,3,...行号,也叫偏移量,为了阅读方便字节码执行过程分析:
执行由三个部分组成:程序计数器(线程中用来指向当前运行指令的位置)、局部变量表、操作数栈,这些在线程中的帧栈中保存的数据
1、
0: sipush 500 --将操作数压入到操作数栈中
程序计数器 0——局部变量表 0 this 1 2 3——操作数栈 500
3: istore_1 --将一个整数存储到局部变量表中,操作数栈清空而存储到局部变量表
程序计数器 3——局部变量表 0 this 1 500 2 3——操作数栈
2、
4: sipush 200
程序计数器 4——局部变量表 0 this 1 500 2 3——操作数栈 200
7: istore_2 --将操作数栈中值存储到局部变量表中,操作数栈清空而存储到局部变量表中
程序计数器 7——局部变量表 0 this 1 500 2 200 3——操作数栈
3、
8: bipush 50
程序计数器 8——局部变量表 0 this 1 500 2 200 3——操作数栈 50
10: istore_3
程序计数器 10——局部变量表 0 this 1 500 2 200 3 50——操作数栈
4、
11: iload_1 --将局部变量表的数据压入操作数栈中
程序计数器 11——局部变量表 0 this 1 500 2 200 3 50——操作数栈 500
12: iload_2 --将局部变量表中第二个位置的整数压入到操作数栈中
程序计数器 12——局部变量表 0 this 1 500 2 200 3 50——操作数栈 200 500
5、
13: iadd --从操作数栈中取出两个值相加再压入操作数栈
程序计数器 13——局部变量表 0 this 1 500 2 200 3 50——操作数栈 700
14: iload_3 --将局部变量表中第三个位置的整数压入到操作数栈
程序计数器 14——局部变量表 0 this 1 500 2 200 3 50——操作数栈 50 700
6、
15: idiv --从操作数栈中弹出两个值相除后得到结果再压入操作数栈
程序计
16: ireturn --方法体的返回,为整数值,返回操作数栈顶的数
程序计数器 16——局部变量表 0 this 1 500 2 200 3 50——操作数栈 14
引入字节码指令:
字节码指令内部表示为一个byte整数
_nop = 0, // 0x00 --空指令
_aconst_null = 1, // 0x01
_iconst_0 = 3, // 0x03
_iconst_1 = 4, // 0x04
_dconst_1 = 15, // 0x0f
_bipush = 16, // 0x10
_iload_0 = 26, // 0x1a
_iload_1 = 27, // 0x1b
_aload_0 = 42, // 0x2a
_istore = 54, // 0x36
_pop = 87, // 0x57
_imul = 104, // 0x68
_idiv = 108, // 0x6c
等号左边理解为句指符,方便阅读和理解的,右边为在计算机内部的表示方式
void setAge(int) 方法的字节码
2A 1B B5 00 20 B1
2A _aload_0
无参的指令
将局部变量slot0 作为引用 压入操作数栈
1B _iload_1
无参的操作
将局部变量slot1(第一个位置) 作为整数 压入操作数栈
B5 _putfield
设置对象中字段的值
参数为2bytes (00 20)
参数含义:指向常量池的引用,指明了字段
Constant_Fieldref
此处为User.age,操作对象
弹出栈中2个对象:objectref, value
将栈中的value赋给objectref的给定字段
B1 _return
没有返回值的返回java中常用的字节码
常量入栈类
– JVM没有寄存器,数据全部放入栈中
aconst_null null对象入栈
iconst_m1 int常量-1入栈
iconst_0 int常量0入栈_
_iconst_5
lconst_1 long常量1入栈_
_fconst_1 float 1.0入栈
dconst_1 double 1.0 入栈
bipush 8位带符号整数入栈
sipush 16位带符号整数入栈
ldc 常量池中的项入栈
局部变量压栈
广义:定义在方法体中的变量
xload(x为i l f d a)
分别表示int,long,float,double,object ref
xload_n(n为0 1 2 3)第几个局部变量去读载
xaload(x为i l f d a b c s)
分别表示int, long, float, double, obj ref ,byte,char,short
从数组中取得给定索引的值,将该值压栈
iaload
执行前,栈:…, arrayref, index
它取得arrayref所在数组的index的值,并将值压栈
执行后,栈:…, value
出栈装载入局部变量
xstore(x为i l f d a)
出栈,存入局部变量
xstore_n(n 0 1 2 3)
出栈,将值存入第n个局部变量
xastore(x为i l f d a b c s)
将值存入数组中
iastore
执行前,栈:…,arrayref, index, value
执行后,栈:…
将value存入arrayref[index]
通用栈操作(无类型)
nop:什么都不做
pop
弹出栈顶1个字长,与数据类型无关
dup
复制栈顶1个字长,复制内容压入栈
类型转化
i2l
i2f
l2i
l2f
l2d
f2i
f2d
d2i
d2l
d2f
i2b
i2c
i2s
i2l
将int转为long
执行前,栈:…, value
执行后,栈:…,result.word1,result.word2
弹出int,扩展为long,并入栈
整数运算
iadd
ladd
isub
lsub
idiv
ldiv
imul
lmul
iinc
浮点运算
fadd
dadd
fsub
dsub
fdiv
ddiv
fmul
dmul
对象操作指令
jvm也是面向对象的
new
getfield
putfield
getstatic
putstatic
条件控制
ifeq 如果为0,则跳转
ifne 如果不为0,则跳转
iflt 如果小于0 ,则跳转
ifge 如果大于0,则跳转
if_icmpeq 如果两个int相同,则跳转
ifeq
参数 byte1,byte2
value出栈 ,如果栈顶value为0则跳转到(byte1<<8)|byte2
执行前,栈:…,value
执行后,栈:…
方法调用
invokevirtual – 对普通实例的类方法的调用,动态绑定,运行时查找对象类型,根据当前类型进行绑定,考虑多台
invokespecial – 对子类调用父类的方法的调用,静态绑定,编译时的声明的类型进行绑定
invokestatic – 调用静态方法
invokeinterface –调用接口的方法,普通方法
xreturn(x为 i l f d a 或为空)– 方法返回
使用ASM生成java字节码
ASM框架
Java字节码操作框架
可以用于修改现有类或者动态产生新类
用户
AspectJ
Clojure
Ecplise
spring
cglib
hibernate
asm使用的例子:
访问者模式访问class文件,然后生成class文件
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_MAXS|ClassWriter.COMPUTE_FRAMES);
//ClassWriter:访问者 visitor 访问然后生成文件
cw.visit(V1_7, ACC_PUBLIC, "Example", null, "java/lang/Object", null);
//Example:生成类的名称
//ACC_PUBLIC:类的访问权限
//java/lang/Object:父类
MethodVisitor mw = cw.visitMethod(ACC_PUBLIC, "" , "()V", null, null);
//ACC_PUBLIC:方法的访问权限
//:构造函数
//()V:空参
mw.visitVarInsn(ALOAD, 0); //this 入栈 -- 执行指令 局部变量表中的第一个参数
mw.visitMethodInsn(INVOKESPECIAL, "java/lang/Object", "" , "()V"); -- 调用方法的指令,调用给定对象的方法,给定父类的构造函数
mw.visitInsn(RETURN); --return 返回
mw.visitMaxs(0, 0); --对方法的局部变量真正大小自动调整计算
mw.visitEnd(); -- 访问结束
mw = cw.visitMethod(ACC_PUBLIC + ACC_STATIC, "main", "([Ljava/lang/String;)V", null, null);
//再去访问生成一个方法
//main:方法名称
//ACC_PUBLIC + ACC_STATIC:访问权限
//([Ljava/lang/String;)V:String数组的参数
mw.visitFieldInsn(GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
//GETSTATIC:访问静态方法
//Ljava/io/PrintStream;:访问的对象
//out:方法名
mw.visitLdcInsn("Hello world!"); -- 常量压栈
mw.visitMethodInsn(INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V");
//调用实例方法
mw.visitInsn(RETURN);
mw.visitMaxs(0,0);
mw.visitEnd();
//设置局部变量,帧栈
byte[] code = cw.toByteArray();
AsmHelloWorld loader = new AsmHelloWorld();
Class exampleClass = loader
.defineClass("Example", code, 0, code.length);
exampleClass.getMethods()[0].invoke(null, new Object[] { null });
//使用classLoader定义类,再用反射调用方法模拟实现AOP字节码织入—面向切面
在函数开始部分或者结束部分嵌入字节码
可用于进行鉴权(用户是否有权限调用)、日志等
在操作前加上鉴权或者日志案例:
//原始代码
public class Account { //账户类
public void operation() {//操作的方法
System.out.println("operation....");
}
}
//我们要嵌入的内容
public class SecurityChecker {//安全检查器
public static boolean checkSecurity() { //检查安全
System.out.println("SecurityChecker.checkSecurity ...");
return true;
}
}
//实现:
class AddSecurityCheckClassAdapter extends ClassVisitor { -- extends ClassVisitor
public AddSecurityCheckClassAdapter( ClassVisitor cv) {
super(Opcodes.ASM5, cv);
}
// 重写 visitMethod,访问到 "operation" 方法时,
// 给出自定义 MethodVisitor实现,实际改写方法内容
public MethodVisitor visitMethod(final int access, final String name,
final String desc, final String signature, final String[] exceptions) {
MethodVisitor mv = cv.visitMethod(access, name, desc, signature,exceptions);
MethodVisitor wrappedMv = mv;
if (mv != null) {
// 对于 "operation" 方法
if (name.equals("operation")) {
// 使用自定义 MethodVisitor,实际改写方法内容
wrappedMv = new AddSecurityCheckMethodAdapter(mv);
}
}
return wrappedMv;
}
}
//包装了的
class AddSecurityCheckMethodAdapter extends MethodVisitor {
public AddSecurityCheckMethodAdapter(MethodVisitor mv) {
super(Opcodes.ASM5,mv);
}
public void visitCode() {
visitMethodInsn(Opcodes.INVOKESTATIC, "geym/jvm/ch10/asm/SecurityChecker",
"checkSecurity", "()Z");
super.visitCode();
}
}
//运行
public class Generator{
public static void main(String args[]) throws Exception {
ClassReader cr = new ClassReader("geym.jvm.ch10.asm.Account"); -- 读入
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_MAXS|ClassWriter.COMPUTE_FRAMES); -- 访问者
AddSecurityCheckClassAdapter classAdapter = new AddSecurityCheckClassAdapter(cw);
cr.accept(classAdapter, ClassReader.SKIP_DEBUG);
byte[] data = cw.toByteArray(); -- 做出输出,覆盖原来文件
File file = new File("bin/geym/jvm/ch10/asm/Account.class");
FileOutputStream fout = new FileOutputStream(file);
fout.write(data);
fout.close();
}
}
//输出
SecurityChecker.checkSecurity ...
operation....JIT及其相关参数
java中单纯的字节码执行性能较差,所以可以对于热点代码编译成机器码再执行,在运行时的编译,叫做JIT Just-In-Time
JIT的基本思路是,将热点代码,就是执行比较频繁的代码,编译成机器码。当再次执行时不做编译而直接执行。
JIT
当虚拟机发现某个方法或代码块运行特别频繁时,就会把这些代码认定为“Hot Spot Code”(热点代码),为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码)
热点代码:调用的方法。被多次调用的循环体。
方法调用计数器:方法调用次数
回边计数器:方法内循环次数
栈上替换:字节码转向机器码
-XX:CompileThreshold=1000
-XX:+PrintCompilation
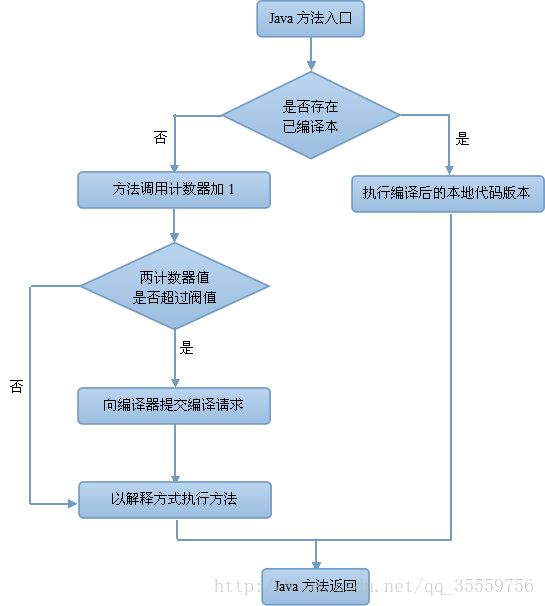
JIT
例子:
public class JITTest {
public static void met(){
int a=0,b=0;
b=a+b;
}
public static void main(String[] args) {
for(int i=0;i<1000;i++){
met();
}
}
}
启动:
-XX:CompileThreshold=1000
-XX:+PrintCompilation
输出:
56 1 java.lang.String::hashCode (55 bytes)
56 2 java.lang.String::equals (81 bytes)
57 3 java.lang.String::indexOf (70 bytes)
60 4 java.lang.String::charAt (29 bytes)
61 5 java.lang.String::length (6 bytes)
61 6 java.lang.String::lastIndexOf (52 bytes)
61 7 java.lang.String::toLowerCase (472 bytes)
67 8 geym.jvm.ch2.jit.JITTest::met (9 bytes)
编译参数:
-Xint
解释执行
-Xcomp
全部编译执行
-Xmixed
默认,混合