sql-基础二
sql92标准
表的连接
笛卡尔积:笛卡尔乘积是一个数学运算。假设我有两个集合X和Y,那么X和Y的笛卡尔积就是X和Y的所有可能组合,也 就是第一个对象来自于X,第二个对象来自于Y的所有可能。
SELECT * FROM player, team
笛卡尔积也称为交叉连接,英文是CROSS JOIN,它的作用就是可以把任意表进行连接,即使这两张表不相 关。但我们通常进行连接还是需要筛选的,因此
需要在连接后面加上WHERE子句,也就是作为过滤条件 对连接数据进行筛选。
等值连接:两张表的等值连接就是用两张表中都存在的列进行连接。我们也可以对多张表进行等值连接。
非等值连接:
当我们进行多表查询的时候,如果连接多个表的条件是等号时,就是等值连接,其他的运算符连接就是非等 值查询。
外连接:
外连接还可以查询某一方不满足条件的记录。两张表的外连接,会有一张是 主表,另一张是从表。如果是多张表的外连接,那么第一张表是主表,即显示全部的行,而第剩下的表则显 示对应连接的信息。在SQL92中采用(+)代表从表所在的位置,而且在SQL92中,只有左外连接和右外连 接,没有全外连接。
左外连接:
左外连接,就是指左边的表是主表,需要显示左边表的全部行,而右侧的表是从表,(+)表示哪个是从 表。
SQL:SELECT * FROM player, team where player.team_id = team.team_id(+)
相当于sql99中
SQL:SELECT * FROM player LEFT JOIN team on player.team_id = team.team_id
右外连接:右外连接,指的就是右边的表是主表,需要显示右边表的全部行,而左侧的表是从表。
SQL:SELECT * FROM player, team where player.team_id(+) = team.team_id
相当于sql99中:
SELECT * FROM player RIGHT JOIN team on player.team_id = team.team_id
自连接:
自连接可以对多个表进行操作,也可以对同一个表进行操作。也就是说查询条件使用了当前表的字段。
SELECT b.player_name, b.height FROM player as a , player as b WHERE a.player_name = '布雷克-格里芬' and b.height>a.height
sql99标准
交叉连接:就是笛卡尔积,是CROSS JOIN。
自然连接:也就是等值连接。它会帮你自动查询两张连接表中所有相同的字段,然后进行 等值连接。NATURAL JOIN
On连接:ON连接用来指定我们想要的连接条件
一般来说在SQL99中,我们需要连接的表会采用JOIN进行连接,ON指定了连接条件,后面可以是等值连 接,也可以采用非等值连接。
using连接:
SELECT player_id, team_id, player_name, height, team_name FROM player JOIN team USING(team_id)
外连接:
- 左外连接:LEFT JOIN 或 LEFT OUTER JOIN
- 右外连接:RIGHT JOIN 或 RIGHT OUTER JOIN
- 全外连接:FULL JOIN 或 FULL OUTER JOIN
全外连接实际上就是左外连接和右 外连接的结合。在这三种外连接中,我们一般省略OUTER不写。
需要注意的是MySQL不支持全外连接,否则的话全外连接会返回左表和右表中的所有行。当表之间有匹配 的行,会显示内连接的结果。当某行在另一个表中没有匹配时,那么会把另一个表中选择的列显示为空值。 也就是说,全外连接的结果=左右表匹配的数据+左表没有匹配到的数据+右表没有匹配到的数据。
自连接:和sql92中的自连接本质上一样。
多表连接注意事项:
1、控制连接表的数量。
多表连接就相当于嵌套for循环一样,非常消耗资源,会让SQL查询性能下降得很严重,因此不要连接不必要 的表。在许多DBMS中,也都会有最大连接表的限制。
2、在连接时不要忘记where语句。
多表连接的目的不是为了做笛卡尔积,而是筛选符合条件的数据行,因此在多表连接的时候不要忘记了 WHERE语句,这样可以过滤掉不必要的数据行返回。
3、使用自连接而不是使用子查询。
因为在许多DBMS的处理过程中,对于自连接的处理速度要比子查询快得多。你可以这样理 解:子查询实际上是通过未知表进行查询后的条件判断,而自连接是通过已知的自身数据表进行条件判断, 因此在大部分DBMS中都对自连接处理进行了优化。
视图
视图作为一张虚拟表,帮我们封装了底层与数据表的接口。它相当于是一张表或多张表的数据结果集。视图 的这一特点,可以帮我们简化复杂的SQL查询,比如在编写视图后,我们就可以直接重用它,而不需要考虑 视图中包含的基础查询的细节。同样,我们也可以根据需要更改数据格式,返回与底层数据表格式不同的数 据。
创建视图
CREATE VIEW view_name AS SELECT column1, column2 FROM table WHERE condition
嵌套视图:当我们创建好一个视图后,可以在这个基础上继续创建视图。
修改视图:alter view
ALTER VIEW view_name AS SELECT column1, column2 FROM table WHERE condition
删除视图 drop view
drop view view_name
视图的作用:
利用视图完成复杂的连接
利用视图对数据进行格式化
使用视图与计算手段
使用视图的好处
- 安全性:虚拟表是基于底层数据表的,我们在使用视图时,一般不会轻易通过视图对底层数据进行修 改,即使是使用单表的视图,也会受到限制,比如计算字段,类型转换等是无法通过视图来对底层数据 进行修改的,这也在一定程度上保证了数据表的数据安全性。同时,我们还可以针对不同用户开放不同 的数据查询权限,比如人员薪酬是个敏感的字段,那么只给某个级别以上的人员开放,其他人的查询视 图中则不提供这个字段。
- 简单清晰:视图是对SQL查询的封装,它可以将原本复杂的SQL查询简化,在编写好查询之后,我们就可 以直接重用它而不必要知道基本的查询细节。同时我们还可以在视图之上再嵌套视图。这样就好比我们 在进行模块化编程一样,不仅结构清晰,还提升了代码的复用率。
和临时表的区别
视图是虚拟表,本身不存储数据,如果想要通过视图对底层数据表的数据进行修改 也会受到很多限制,通常我们是把视图用于查询,也就是对SQL查询的一种封装。那么它和临时表又有什么 区别呢?在实际工作中,我们可能会见到各种临时数据。比如你可能会问,如果我在做一个电商的系统,中 间会有个购物车的功能,需要临时统计购物车中的商品和金额,那该怎么办呢?这里就需要用到临时表了, 临时表是真实存在的数据表,不过它不用于长期存放数据,只为当前连接存在,关闭连接后,临时表就会自 动释放。
存储过程:
它是SQL中另一个重要应用,和视图一样,都是对SQL代码进行封装,可 以反复利用。它和视图有着同样的优点,清晰、安全,还可以减少网络传输量。不过它和视图不同,视图是 虚拟表,通常不对底层数据表直接操作,而存储过程是程序化的SQL,可以直接操作底层数据表,相比于面 向集合的操作方式,能够实现一些更复杂的数据处理。存储过程可以说是由SQL语句和流控制语句构成的语 句集合,它和我们之前学到的函数一样,可以接收输入参数,也可以返回输出参数给调用者,返回计算结 果。它的思想很简单,就是SQL语句的封装。一旦存储过程被创建出来, 使用它就像使用函数一样简单,我们直接通过调用存储过程名即可。
创建存储过程:
CREATE PROCEDURE 存储过程名称([参数列表]) BEGIN需要执⾏的语句 END
删除存储过程:
drop procedure procedure_name
更新存储过程:
alter procedure prodecure_name
比如我想做一 个累加运算,计算1+2+…+n等于多少,我们可以通过参数n来表示想要累加的个数,那么如何用存储过程实 现这一目的呢?这里我做一个add_num的存储过程,具体的代码如下:
CREATE PROCEDURE `add_num`(IN n INT)
BEGIN
DECLARE i INT;
DECLARE sum INT;
SET i = 1;
SET sum = 0;
WHILE i <= n DO
SET sum = sum + i;
SET i = i +1;
END WHILE;
SELECT sum;
END
CALL add_num(50);
存储过程参数类型
IN 不返回,向存储过程传入参数,存储过程修改该参数的值,不能被返回。
out 返回,把存储过程的结果放到该参数中,调用者可以得到返回值。
inout 返回,in和out的结合,即用于存储过程的传入参数,同时又可以把计算结果放到参数中,调用者可以得到返回值。
流程控制语句
-
BEGIN…END:BEGIN…END中间包含了多个语句,每个语句都以(;)号为结束符。
-
DECLARE:DECLARE用来声明变量,使用的位置在于BEGIN…END语句中间,而且需要在其他语句使用 之前进行变量的声明。
-
SET:赋值语句,用于对变量进行赋值。
-
SELECT…INTO:把从数据表中查询的结果存放到变量中,也就是为变量赋值。
-
IF…THEN…ENDIF:条件判断语句,我们还可以在IF…THEN…ENDIF中使用ELSE和ELSEIF来进行条件判 断。
-
CASE:CASE语句用于多条件的分支判断,使用的语法是下面这样的。
CASE WHEN expression1 THEN ... WHEN expression2 THEN ... ... ELSE --ELSE语句可以加,也可以不加。加的话代表的所有条件都不满⾜时采⽤的⽅式。 END -
LOOP、LEAVE和ITERATE:LOOP是循环语句,使用LEAVE可以跳出循环,使用ITERATE则可以进入下一次 循环。如果你有面向过程的编程语言的使用经验,你可以把LEAVE理解为BREAK,把ITERATE理解为 CONTINUE。
-
REPEAT…UNTIL…END REPEAT:这是一个循环语句,首先会执行一次循环,然后在UNTIL中进行表达式 的判断,如果满足条件就退出,即END REPEAT;如果条件不满足,则会就继续执行循环,直到满足退出条 件为止。
-
WHILE…DO…END WHILE:这也是循环语句,和REPEAT循环不同的是,这个语句需要先进行条件判断, 如果满足条件就进行循环,如果不满足条件就退出循环
事务
事务的特性
- A,也就是原子性(Atomicity)。原子的概念就是不可分割,你可以把它理解为组成物质的基本单位,也 是我们进行数据处理操作的基本单位。
- C,就是一致性(Consistency)。一致性指的就是数据库在进行事务操作后,会由原来的一致状态,变 成另一种一致的状态。也就是说当事务提交后,或者当事务发生回滚后,数据库的完整性约束不能被破 坏。
- I,就是隔离性(Isolation)。它指的是每个事务都是彼此独立的,不会受到其他事务的执行影响。也就 是说一个事务在提交之前,对其他事务都是不可见的。
- 最后一个D,指的是持久性(Durability)。事务提交之后对数据的修改是持久性的,即使在系统出故障 的情况下,比如系统崩溃或者存储介质发生故障,数据的修改依然是有效的。因为当事务完成,数据库 的日志就会被更新,这时可以通过日志,让系统恢复到最后一次成功的更新状态。 在这四个特性中,原子性是基础,隔离性是手段,一致性是约束条件,而 持久性是我们的目的。
常用的事务控制语句
START TRANSACTION或者 BEGIN,作用是显式开启一个事务。
COMMIT:提交事务。当提交事务后,对数据库的修改是永久性的。
ROLLBACK或者ROLLBACK TO [SAVEPOINT],意为回滚事务。意思是撤销正在进行的所有没有提交的修 改,或者将事务回滚到某个保存点。
SAVEPOINT:在事务中创建保存点,方便后续针对保存点进行回滚。一个事务中可以存在多个保存点。
RELEASE SAVEPOINT:删除某个保存点。
SET TRANSACTION,设置事务的隔离级别。
mysql completion_type参数的作用
1.completition=0,这是默认情况。也就是说当我们执行COMMIT的时候会提交事务,在执行下一个事务 时,还需要我们使用START TRANSACTION或者BEGIN来开启。 2. completion=1,这种情况下,当我们提交事务后,相当于执行了COMMIT AND CHAIN,也就是开启一个 链式事务,即当我们提交事务之后会开启一个相同隔离级别的事务(隔离级别会在下一节中进行介 绍)。 3. completion=2,这种情况下COMMIT=COMMIT AND RELEASE,也就是当我们提交后,会自动与服务器 断开连接。
如何理解autocommit=1和start transaction的区别
1.当autocommit=0时,不管有没有START TRANSACTION或BEGIN,只有COMMIT才会生效,ROLLBACK会 回滚。 2. 当autocommit=1,并且没有START TRANSACTION或BEGIN时,执行COMMIT和ROLLBACK是没有用的。 因为MySQL进行了自动提交,想要开启事务处理来管理一组SQL操作,就需要用START TRANSACTION或 BEGIN。 3. 不论autocommit是1还是0 ,START TRANSACTION或BEGIN,相当于开启了一个显式事务,只有 COMMIT才会生效,ROLLBACK就会回滚。
事务并发处理存在的异常:
1.脏读:读到了其他事务还没有提交的数据。 2. 不可重复读:对某数据进行读取,发现两次读取的结果不同,也就是说没有读到相同的内容。这是因为 有其他事务对这个数据同时进行了修改或删除。 3. 幻读:事务A根据条件查询得到了N条数据,但此时事务B更改或者增加了M条符合事务A查询条件的数 据,这样当事务A再次进行查询的时候发现会有N+M条数据,产生了幻读。
隔离级别
读未提交(READ UNCOMMITTED )、读已提交(READ COMMITTED)、可重复读(REPEATABLE READ)和可串行化(SERIALIZABLE)。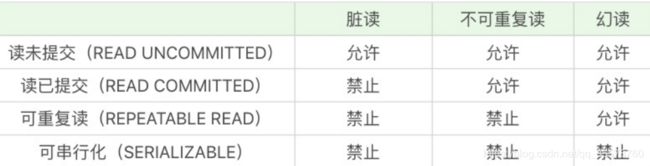
读未提交,也就是允许读到未提交的数据,这种情况下查询是不会使用锁的,可能会产生脏读、不可重复 读、幻读等情况。 读已提交就是只能读到已经提交的内容,可以避免脏读的产生,属于RDBMS中常见的默认隔离级别(比如 说Oracle和SQL Server),但如果想要避免不可重复读或者幻读,就需要我们在SQL查询的时候编写带加锁 的SQL语句。可重复读,保证一个事务在相同查询条件下两次查询得到的数据结果是一致的,可以避免不可重复读和脏 读,但无法避免幻读。MySQL默认的隔离级别就是可重复读。 可串行化,将事务进行串行化,也就是在一个队列中按照顺序执行,可串行化是最高级别的隔离等级,可以 解决事务读取中所有可能出现的异常情况,但是它牺牲了系统的并发性。
游标:
在数据库中,游标是个重要的概念,它提供了一种灵活的操作方式,可以让我们从数据结果集中每次提取一 条数据记录进行操作。游标让SQL这种面向集合的语言有了面向过程开发的能力。可以说,游标是面向过程的编程方式,这与面向集合的编程方式有所不同。在SQL中,游标是一种临时的数据库对象,可以指向存储在数据库表中的数据行指针。这里游标充当了指针 的作用,我们可以通过操作游标来对数据行进行操作。在SQL中,游标是一种临时的数据库对象,可以指向存储在数据库表中的数据行指针。这里游标充当了指针 的作用,我们可以通过操作游标来对数据行进行操作。
定义游标
DECLARE cursor_name CURSOR FOR select_statement
要使用SELECT语句来获取数据结果集,而此时还没有开始遍历数据,
这里select_statement代表的是SELECT 语句。
如果是oracle,
DECLARE cursor_name CURSOR IS select_statement
打开游标
open cursor_name;当我们定义好游标之后,如果想要使用游标,必须先打开游标。
打开游标的时候SELECT语句的查询结果集 就会送到游标工作区。
从游标中获取数据
fetch cursor_name into var_name...
这句的作用是使用cursor_name这个游标来读取当前行,
并且将数据保存到var_name这个变量中,游标指 针指到下一行。
如果游标读取的数据行有多个列名,则在INTO关键字后面赋值给多个变量名即可。
关闭游标
close cursor_name
关闭游标之后, 我们就不能再检索查询结果中的数据行,如果需要检索只能再次打开游标。
释放游标
DEALLOCATE PREPARE