从零开始java数据库SQL优化(番外):SQL执行性能分析
目录
一:为什么要进行性能分析
1.先来看一下一个100多万条数据表的查询:
2.添加limit查询
6.排查问题
7.解决问题
三:语句分析初步得出优化建议
一:为什么要进行性能分析
在MSYQL中当数据量大的时候,查询会变得特别慢,特别卡。这时候我们在写SQL时就需要特别小心,避免由于SQL导致查询性能瓶颈(说实话,这点真的认为ORACLE做的比MYSQL好得多)。
二:navcat快速进行性能分析
navcat真是个比较优秀的工具,因为一开始navcat用习惯了。
1.先来看一下一个100多万条数据表的查询:
![]()
![]()
2.添加limit查询
本来认为没什么问题的,毕竟100多万条查询几秒很正常。但是突发奇想加上了limit10
![]()

3.navcat打开语句分析第一步:执行计划
有问题了,百度一下,查出来什么加上limit查询有了范围就不进行全表查询什么的,总感觉不对劲,然后看到语句分析。
查询结束后按照如图所示查看执行计划:
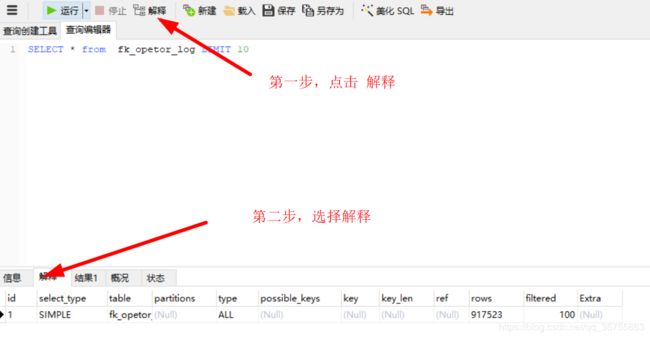
解释下各个字段的含义:
id:不用问。
select_type: select查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询。
a.SIMPLE:查询中不包含子查询或者UNION
b.查询中若包含任何复杂的子部分,最外层查询则被标记为:PRIMARY
c.在SELECT或WHERE列表中包含了子查询,该子查询被标记为:SUBQUERY
d.在FROM列表中包含的子查询被标记为:DERIVED(衍生)
e.若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在 FROM子句的子查询中,外层 SELECT将被标记为:DERIVED
f.从UNION表获取结果的SELECT被标记为:UNION RESULT
table:查询所对应的表
partitions: 分区,一般用不到
type:表示MySQL在表中找到所需行的方式,又称“访问类型”,常见类型如下:结果值从好到坏依次是:system > const > eq_ref
> ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys:指出MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被
查询使用。
key: 显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL。TIPS:查询中若使用了覆盖索引,则该索引仅出
现在key列表中。
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度,key_len显示的值为索引字段的最大可能长度,
并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
Extra:包含不适合在其他列中显示但十分重要的额外信息
由上面可以得到:一些sql优化建议: 尽量避免全表查询,建立合适的索引,索引字段不要太长(比如varchar(66000))
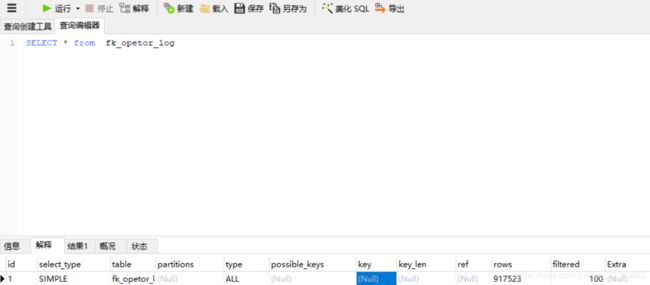
通过对比发现,执行计划是一样没有什么不同。
4、navcat打开语句分析第二步:执行状态。
在上面下面选择概况:

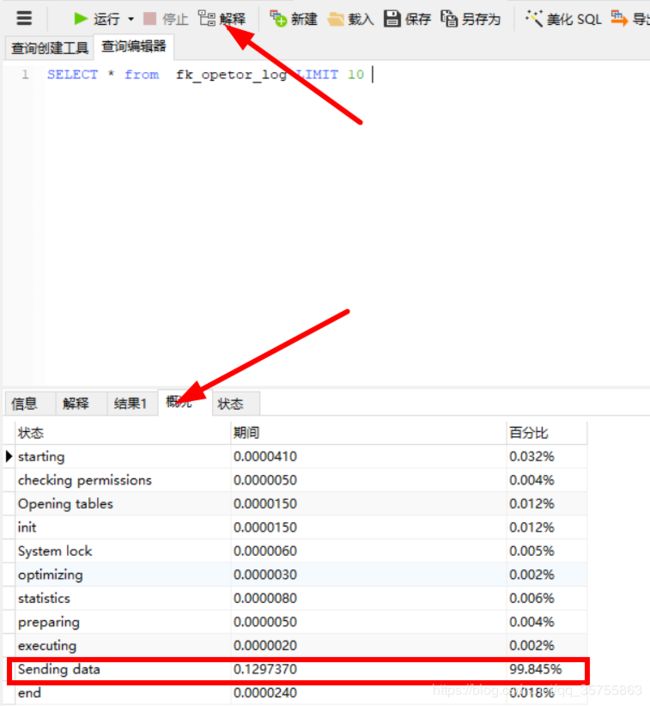
发现主要区别在Send_data时间消耗有区别。那么我们来看一下这个名词是什么东西?
原来这个状态的名称很具有误导性,所谓的“Sending data”并不是单纯的发送数据,而是包括“收集 + 发送 数据”。这里的关键是为什么要收集数据,原因在于:mysql使用“索引”完成查询结束后,mysql得到了一堆的行id,如果有的列并不在索引中,mysql需要重新到“数据行”上将需要返回的数据读取出来返回个客户端。
5、navcat打开语句分析第三步:时间分布。
首先打开配置:set profiling=on;
执行完查询后,使用show profiles查看query id;
使用show profile for query query_id查看详细信息;

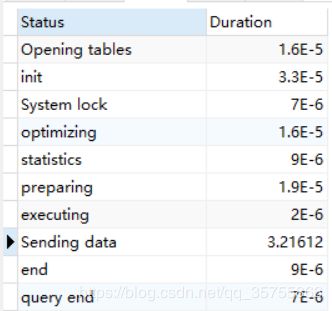
好吧问题果然出在这个上面。
6.排查问题
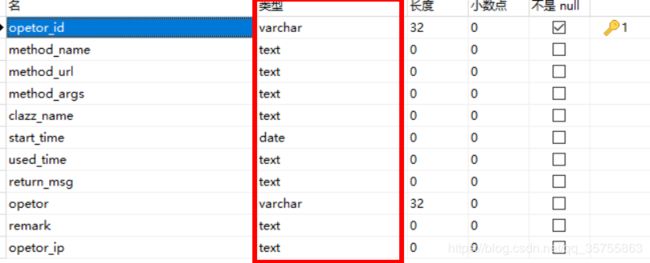
发现我去 全是text大文本字段,有些脑壳疼。
show table status,查看溢出信息,溢出数据会被随机读取,造成读取耗时多。

7.解决问题
(1)百度优化text,blob等等大字段的优化
(2)业务拆分,很显然 text的字段可以单独拆分出一个表字段。
三:语句分析初步得出优化建议
1.尽量合理使用索引
2.尽量避免表设计字段过长
3.尽量添加limit条件