好程序员Java教程分享Zookeeper基本原理与运用场景
好程序员Java教程分享Zookeeper基本原理与运用场景
好程序员Java教程分享Zookeeper基本原理与运用场景一、什么是Zookeeper?
zookeeper是一个分布式的一致性协调服务。
换句话说,也可以把zookeeper看成一个小型的分布式文件系统。但是和FastDFS不同,zookeeper只适合用来存储一些小型的数据或者配置信息。
二、Zookeeper的文件系统
zookeeper底层是一个树形结构,进行数据的存储。
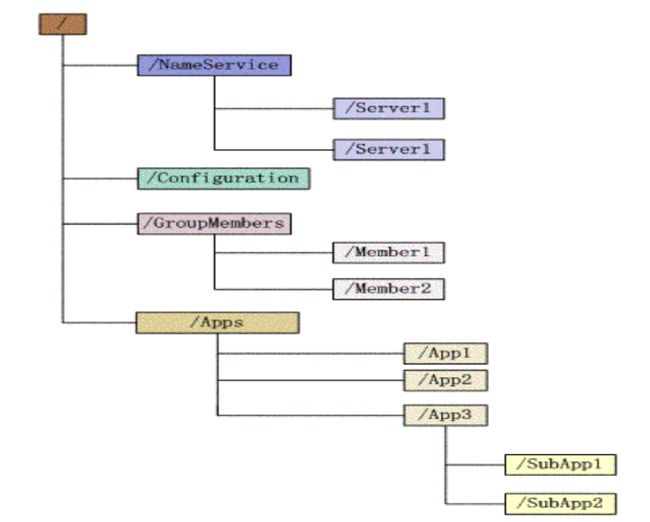
和Linux、Window等系统不同:
Linux和Window中有文件和文件夹的概念。文件夹下面只能有文件,文件下面不能再有数据。文件夹本身不存放数据,文件本身用来进行数据存储。
Zookeeper中的节点,没有文件夹和文件之分,所有节点都可以进行数据存储,同时也可以拥有子节点。每个节点称之为znode
znode的分类:
1)临时节点-ephemeral:临时节点由某个客户端创建,如果该客户端断开了和zookeeper服务器的链接,则该临时节点就会被自动删除。注意:临时节点不能有子节点。
2)持久性节点-persistent:持久化的节点会永久存在于文件系统中,除非客户端显示的删除该节点。该节点是最常见的节点。
3)临时顺序节点-ephemeral_sequential:和临时节点拥有相同的特点,唯一的却别在于该节点名称会自动维护一个编号。
4)持久性顺序节点-persistent_sequential:和持久性节点拥有相同的特点,唯一的却别在于该节点名称会自动维护一个编号。
文件系统的操作命令:
ls 路径:查看某个路径下的子节点情况,zk中只能写绝对路径(所有的路径都必须从/出发)
create [-s] [-e] path data : 创建一个节点,在path路径的位置。数据为data(数据不能为空,至少要为'')。-s表示顺序节点 -e临时节点
get 路径:查看指定路径对应的节点数据。每个节点都分为:数据部分、描述信息
set path data:修改指定节点的数据
delete path:删除指定节点数据,如果下面的有子节点需要先删除子节点
三、Zookeeper的通知机制(watch)
什么是通知机制?
客户端可以选择对某个znode进行监听。当这个znode发生变化时(本身的添加、删除、修改以及子节点的变化),会主动通知监听了这个znode的客户端。zookeeper的通知机制有一次性触发原则,znode发生变化后,一旦通知了客户端,则断开客户端的监听,如果需要继续监听节点的变化,则必须重新发起监听。
exists - 可以监听到节点创建、节点的内容修改、节点的删除
getData - 可以监听节点内容修改,节点的删除
getChildren - 可以监听子节点的添加、删除(子节点内容变化和子节点的子节点的变化不能监听)
四、Zookeeper的运用场景
1)配置文件统一管理
在分布式集群的工程中,通常由很多服务部署在不同的服务上,每个服务都有自己的配置信息,如果需要修改某个配置,则可能需要对多态服务器进行配置的修改,是非常不方便的。那么就可以使用zookeeper帮助我们进行统一的配置文件管理。
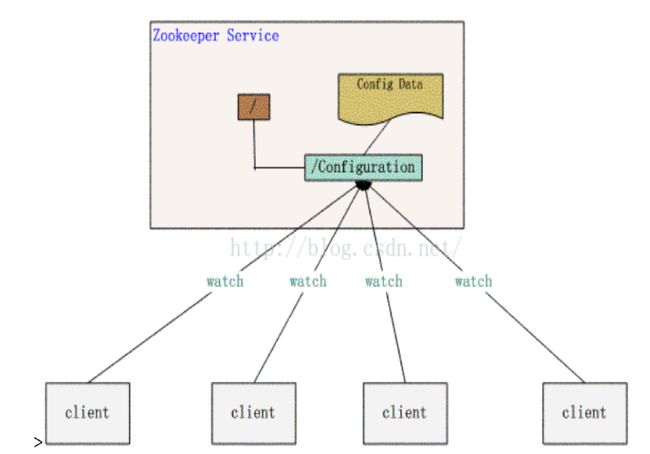
在zookeeper上创建一个持久化节点,将所有的配置信息放入到这个节点中,然后每台服务器都去监听这个节点的变化(Watch机制)。如果有新的配置信息,开发者只需要上传到zookeeper的这个节点上(更新节点的配置数据)。每个服务就能收到zookeeper节点的更新通知,然后从节点中读取新的配置,应用到系统中,完成配置的更新。
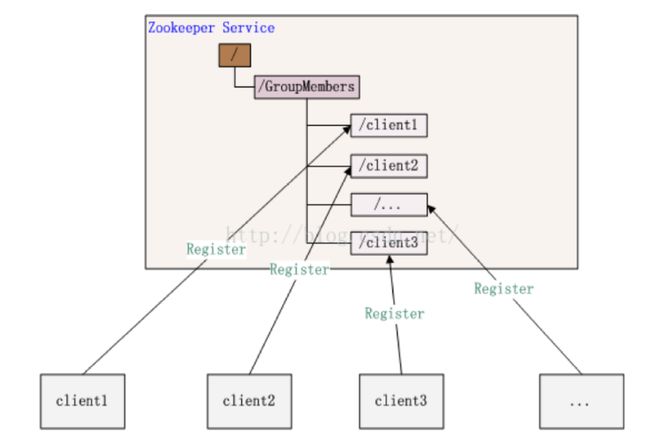
2)集群管理
在某些集群中,可能需要知道其他集群服务器的状态,比如有新的机器加入集群,或者有老的机器退出集群等。这个时候就可以通过zookeeper进行集群的统一管理。
3)分布式锁
· 保持独占
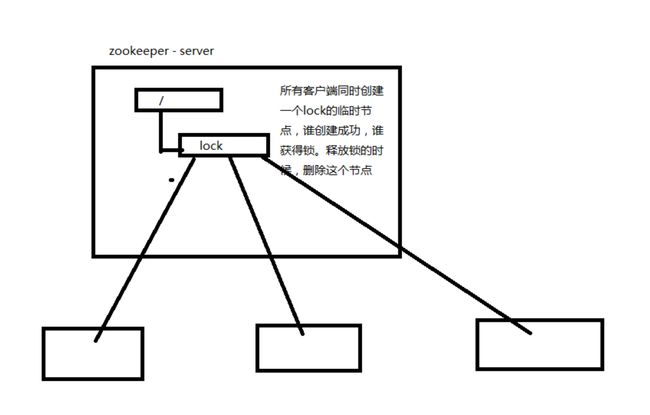
· 控制顺序
所有客户端同时在一个节点的下面创建临时顺序节点。然后只需要让编号最小的节点的机器获得锁就可以了。
五、Zookeeper的集群
集群的工作原理:
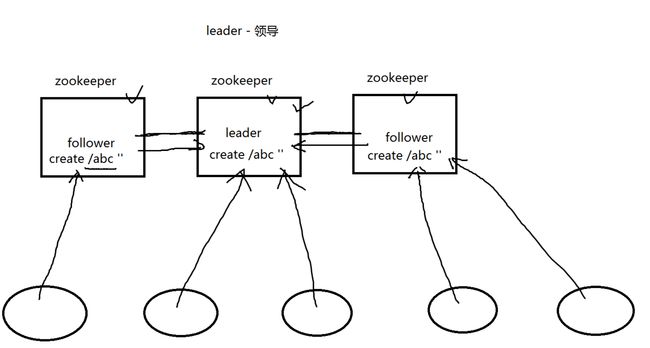
zookeeper集群可能有N台机器,这些机器中一定会存在一个leader,其他的机器就是follower。对于客户端来说,可以随意连接任何一个集群中服务器。如果某个客户端需要对zk进行更改的操作,这些操作命令最终需要提交给leader。leader将命令分发给所有的集群服务器。当一半以上的集群服务器执行该命令成功,则leader就会通知所有节点进行事务提交,达到数据同步更新的目的。
zookeeper集群的“过半数存活原则”:
在zookeeper集群中,当存活的机器数量超过总集群一半的时候,整个集群才能正常工作。
基于过半数存活原则,zookeeper的集群数量一定是奇数台。
为什么zookeeper需要设计一个过半数存活机制?
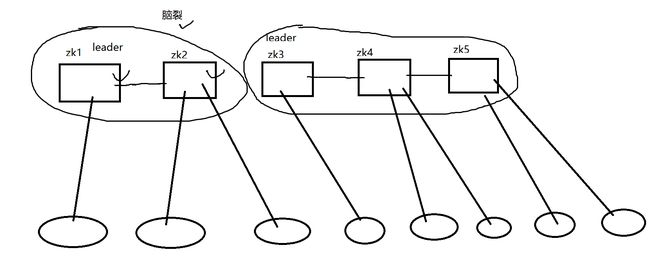
因为整个集群中,有可能因为“脑裂“,导致整个集群分为2个甚至多个集群,如果没有“过半数存活的机制“,那么整个zookeeper集群提供的数据将无法再保证数据一致性。所以为了保证整体数据的强一致性,zookeeper规定了过半数存活这个原则。
zookeeper集群的角色:
leader:领导者
follower:追随者
observer:观察者,观察者和追随者功能一样,但是区别在于观察者不会参与投票环节。