ETL DataStage实现
转载
第1章 前言
自开始知道数据库,就知道有数据仓库这个东西,数据仓库中一关键环节就是ETL。可是三四年过去了,由于没有接触数据仓库这个东西,对ETL自然是一知半解,更别提实现了。从2007年9月份开始,要做数据仓库项目了,接触了ETL。ETL中要用DS实现,项目中没有人会,组长要我一个月内,边工作边自学DS,然后给大家讲怎么用DS实现ETL。想起初学时的困难和迷惑,和现在一些同学的疑问,本人从开发的角度,简单介绍一下用DS实现ETL。由于本人的知识和经验的局限,自然有很多错误和不足,希望大家指正,共同进步,给初进入者一个参考。
适合人群是对DS实现ETL不了解,想有一个大概印象的人。其他人就帮忙补充或者修正一下这个东东吧!
有很多地方都是从网上或者其他文章上摘抄的,如有不妥,请指出,将会删掉。
本文都用DS代替DataStage。
1.1 什么是ETL
既然是ETL DS实现,那就首先得介绍一下ETL了,呵呵。ETL即数据的抽取(Extract)、转换(Transform)、装载(Load),简单来讲,就是一个倒数的过程。原数据很难满足目标系统(就是数据仓库或者别的系统)的需要,就得对数据进行各种各样的处理了。
1.2 自编程实现与ETL工具
既然是一个导数的过程,应该不难实现了,而且工具还得学习,又那么贵,可为什么还要用工具呢?
试想以下场景:
一、项目中的源就是csv文件,目标库就只有一个oracle库,而且接口数量不大,数据基本没有什么转换,以后也没有多少接口增加;
二、项目中的源有多种文件,好多种数据库,接口的数量很多,数据的转换也比较复杂,以后还有很多接口,很多种源。
当然第一种情况,编程就很容易实现,而且如果程序做的不是太烂,性能,可维护性和可扩展性应该都不错。那项目上非得要用ETL工具呢,你就用吧,艺多不压身,呵呵。
第二种情况,编程也可以实现,问题是得有多少人,花多长时间,能实现个什么程度,它的性能,可维护性和可扩展性如何?如果这些问题都可以确定,OK,那就项目组编程实现好了。相信,大多数项目组,特别是给别人做项目的,会选择用ETL工具。
现代社会之所以发展的这么快,我认为主要的就是专业化分工(扯远了)。虽然ETL工具有这样那样的缺点,但它的技术门槛比较低,开发人员可以很容易的上手,做出的东西性能上也不会差很多,开发,调试,维护都可以很容易的在图形界面上实现。各种各样的源和转换工作,都可以用它的组件实现。相比较之下,这些方面要远好于自编程实现。
1.3 DS可实现功能
做为专业的ETL工具,DS可实现的功能自然是ETL中需要完成的功能,它基本上都可以做到。
DS的基础组件被称为Stage,它所实现的功能,大多是通过在图形界面上拖拉实现的。DS的基础Stage分为两类:Active Stage就是完成数据的转换加载等动作,PassiveStage就是与数据库或者文件进行连接,然后让ActiveStage完成其他操作。
Passive Stage可以与文本文件,XML文件,几乎所有的数据库,Web Services,WebSphere MQ和主要的企业级应用如SAP、Siebel、Oracle 以及PeopleSoft进行联接。
Active Stage几乎可以完成SQL所能完成的所有工作,如关联,过滤,去重。
Job Sequence可以将基础JOB联接起来,实现JOB间的依赖,互斥等操作。
再加上DS自带的Basic语言,可以实现各种定制Function,也可以在DS Job Job Crontrol中,除可以对JOB进行灵活多样的控制外,也可以完成大多数语言实现的功能。
DS也可以调用其他语言,如Shell(或DOS),TCL,可以完成DS本身难以完成的任务。
当然,调度自然不可少,它支持相对不复杂的以时间为主的调度。
以及相关的源数据的管理,备份恢复,调试等功能。
第2章 DS入门
2.1 DS结构
DS是C/S结构,由服务器端和客户端组成。服务器端可以装在Windows,Unix等平台上,客户端只能装在Windows上。客户端包含:DS Administrator; DS Manager; DS Designer; DS Director。服务端包含:DS Engine; MetaData Repository; Package Installer。总体架构见下图:
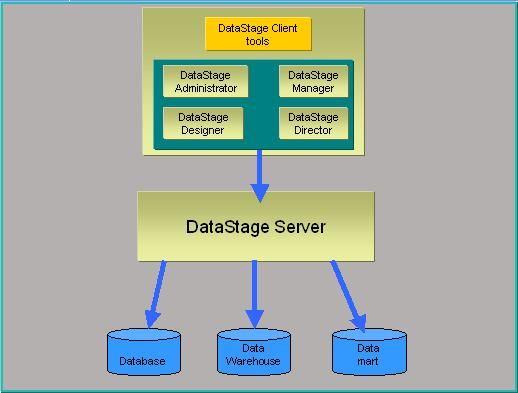
2.2 客户端组件介绍
我们开发,自然用得最多的是客户端,就重点介绍一下客户端。
2.2.1 DS Administrator
主要功能有:
1、添加和删除项目(Project),一个项目就相当于Oracle数据库的一个Schema,各个对象都必须属于特定的项目;
2、License的管理;
3、设置全局参数和修改项目中的参数。项目中用到的通用参数可以在这里设置,调优需要修改的参数也都在这里。
既然功能这么重要,操作时要慎重哟!
2.2.2 DS Manager
主要功能有:
1、察看和修改DS元数据;
2、导入表定义,不止从数据库哟;
3、export,import DS Components,其实也就是DS的备份恢复功能;
4、创建Routine: Transformer Routine(Parallel Routine,Server Routine),就是在TransformerStage中调用的function; Befor-afterJob subroutine; Job Control Routine。除了Parallel Job中TransformerRoutine需要用C/C++写外,其他Routine都可以用DS Basic写,而且大多也是通用的。
5、批量编译JOB,不用一个个的编译(废话),记住这一点,就不会像我曾经那样上千个JOB一个个点了。
2.2.3 DS Designer
当然这个就是我们开发DS最主要的工作环境了。
1、与JOB相关的开发,编译,执行;
2、Container,包括Localcontainers和Shared containers,Container就是将具有相同功能和输入输出参数的用几个Stage封装成一个模块;
3、新Parallel Stage的创建,就是自定义Stage。
2.2.4 DS Director
1、执行JOB
2、察看JOB执行情况及状态,JOB调度,JOB执行日志
3、添加、删除、修改JOB的调度,对,这里就是大名鼎鼎的调度,可以在这里实现,可以按照不同时间调度。对了,本人偶尔发现的小秘密,一个JOB可以加多个调度,而且都起作用的(是不是大家都知道了?)。可惜它的调度方式只能满足一般的应用,一些复杂的调度,就得我们自己动手了。唉!它咋不能做的再强点呢?
3、删除JOB,在Designer中也是可以的。
其实有些功能,不只是在一个组件中有,在其他组件中也是可以用的。
2.3 JOB注意事项
一些初学时的注意事项:
1、用文件或者数据库做源时,做好后最好先"View Data"一下,然后再编译、运行。这是出错最多的地方
2、运行完之后,一定要在director中看一下日志。大部分错误都是由于数据库配置或者文件名称不对,也可能是定义的列与实际的列不是完全匹配等引起的。其实DS的报错和其他程序的报错差不多,大多数是可以看明白是哪些地方,为什么报错的
3、Server Job对列的定义要求不严,类型长度短点长点都无所谓,而Parallel Job长度必须正确,定义的短了,就会截断数据;如果中间用到Active Stage,在Active Stage中源和目标长度必须一样,否则会报警告。
4、如果不知道哪个Stage该怎么用,DS Basic怎么用,可以查看安装客户端时自带的PDF帮助,这个应该是最详细的,在网上很难找到这类的帮助。
第3章 ETL设计
ETL的设计是个庞大的工程,不同的项目设计差别很大。对于特别简单或者特别复杂的项目,在此不做讨论,只讨论一些常见的项目中利用DS实现ETL的设计。
ETL一般需要考虑的问题有:接口数据的获取,频率,数据校验,接口间及后续处理的关联关系,入库方式;优先级,顺序乱序执行,出错处理,重传处理,调度监控等。除了这些问题,可能还会有个别数据不是格式化数据,文件格式DS无法识别,文件标识的时间与实际数据数据时间不一致等问题。
3.1 设计原则
3.1.1 简单
说起来简单,做起来难,呵呵。一直以来都追求简单,无奈做出来的却是越来越复杂,越来越难以让人明白。不过,始终相信简单就是好的,以此做为设计和开发的第一原则。
3.1.2 全面考滤,重点实现
设计之前,需要全面考滤ETL要实现的各种功能。包括源数据都有哪些,如何得到,数据是如何存储的,如何调度,出错如何处理,过了期的数据如何处理,整个ETL过程如何监控等。所有这些项下面都有各种各样的小项,每个小项又是千变万化,不可能每项都能想到,即使能想到,也不可能都能设计时考滤进去。所以设计要把大项尽可能的考滤进去,可以用比较容易扩展的设计,包括小项80%的功能。
3.1.3 充分利用各种资源
ETL中涉及到好多系统,用到很多技术,ETL的设计就是要充分利用已有资源的优势(包括人员,操作系统,DS,数据库等),综合运用,达到ETL和其他系统最好的结合。这个可能要求对各种资源了解的比较清楚。
3.1.4 层次分明
稍复杂的ETL,涉及到的面就比较多,除需要考滤实现的难易程度,性能,实现成本,还得考滤程序的稳定性和可扩展性。层次分明将是其实现的一个重要保证
3.1.5 规范严明
开始时规范可能定的不够详细,不是很准确,但是一定得有,而且相关人员需要知道为什么要这么定。这些规范可能包括Shell、DS JOB,存储过程如何命名如何注释等。也许按照规范可能开始时比较费事,而且看不到任何的好处,等做的多了,时间长了,只要看看规范或者是程序的注释部分,就能知道程序实现了什么功能,如何实现,而不用一行行的看代码。
3.2 总体架构
这里只是ETL的架构,而不是整个数据仓库的架构。主要的架构包括以下部分。这个图只是表示大概部分,监控可以完成整个ETL的监控,或者是对部分重要任务的监控。
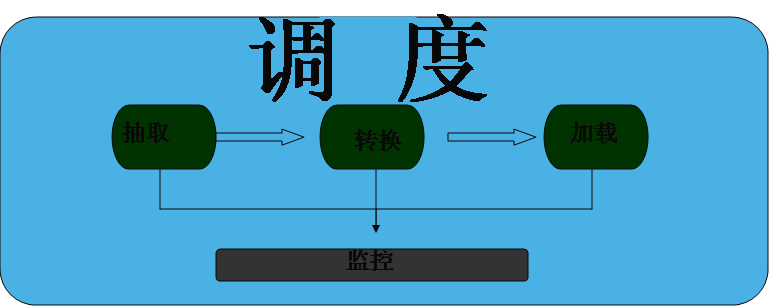
3.3 调度
ETL,堆在一块不运行也没什么用,如何能让它正确的运行起来呢?那就是调度了。
调度是ETL的灵魂。ETL调度的设计,决定了ETL所能实现的功能以及灵活性,也决定了其他ETL部分工作量的大小。
调度涉及到的问题主要有优先级,顺序乱序执行,出错处理,重传处理,调度监控。
优先级就是任务之间执行的先后紧急顺序,将DS Job分为几个优先级,同一优先级或者不同优先级的JOB间有依赖、互斥等关系。
顺序乱序执行,顺序就是按照时间的先后顺序加载,而乱序则可以不按照时间顺序执行,主要是一些高频率JOB,异常情况不适合人工处理。
出错处理、重传处理,就是要求整个ETL支持重做。
调度监控,对ETL的处理结果和重要步骤有一个记录,有问题时发邮件或者短信通知相关负责人。
如果这些都不太复杂,可以用sequenceJob,在调度的JOB中用Job Control自编程的方式实现部分任务执行日志的记录。对于很复杂的,sequence Job难以实现的,可以自己写调度程序实现(如Shell, Python , Java)。
3.4 E T L
这部分是整个ETL的主要部分,无论是工作量,还是复杂程度,都是最大的。这部分的实现很大部分与源数据,源数据与目标数据数据的对应有很大关系。如果需要做的很简单,完全可以一个JOB搞定,没有必要分的很细。如果比较复杂,可能需要分为ET L三个步骤或者更多,DS的设计也会在项目中经建目录的方式将其分开,各步骤生成的文件也将以不同的命名方式放在ETL服务器不同的目录下。
这部分的处理,尽早将没用的数据过滤,不正确的格式转换等,使得后来的处理尽量少,尽量简单。下面有些具体的处理方式,可以在Extract时做,也可以在Transform中做,load时就尽量少做些与入库不相关的操作了。执行的顺序可以是E T L,也可以是E L T,或者是E T L T等。但是做为一个整体,最好有一致的方式处理,而不是不同的任务处理方式千变万化。
这部分正是DS的强项。
3.4.1 Extract
就是从数据源获取数据。在数据抽取时,尽量将没用的数据,不对的数据在抽取时过滤掉,格式等不符合的转换掉。如果源系统对自己的性能要求比较高,则用对源系统打扰尽量少的方式获取,如db2的export,oracle的exp等方式,然后再做处理。
涉及到的功能主要有:
数据范围过滤,抽取表中所有数据或者根据时间抽取相应数据
字段过滤,只抽取需要的字段,不需要的就不用管
条件过滤,根据抽取条件抽取数据
去除回车换行,如果已抽取成文件,字段中的回车换行将很难去掉
除此之外,还有
格式转换,特别是时间格式,最好是做成统一格式
赋缺省值,对于空的部分数据,根据需要赋一个缺省值
类型变换,如将number类型转换为varchar类型
代码转换,就是将在不同源系统中同一含义不同的编码表示转换成统一的编码表示,如将代表性别“男”的'N','0'转换成'M'
数值转换,就是度量单位的转换
3.4.2 Transform
就是将抽取的数据,进行一定的处理,生成目标表所需要的格式,内容。
涉及到的处理主要有:
字段合并、拆分:字段合并就是将多个字段合并成一个字段;拆分就是将一个字段拆成多个字段
数据翻译,就是不同的数据集进行关联,从另一个数据集中得到所需要的部分数据
数据聚合,就是做一些sum,max等操作
数据合并,相当于数据库中的merge
行列转换,需要将某些数据转换成行,或者是将行转换成列
参照完整性检查,对于数据中的参照完整性,入库前需要进行关联等方式检查其参照完整性
唯一性检查,对数据进行去重操作
3.4.3 Load
就是将数据入库,如果前面的处理都做了,就可以直接入库了。入库的时候需要考滤:
更新入库,对数据库中的记录进行更新
插入,就是将数据直接入库
刷新,将表中的数据清空,然后入库
部分刷新,将表中的部分数据清除,然后入库
由于性能等方面的需要,入库前后,可能需要做一些处理,如索引临时失效,主外键约束临时失效等
3.5 过期文件处理
接口文件或者是ETL中间处理生成的文件会越积越多,久而久之,再大的文件系统也会撑爆,所以就得对文件进行处理了。接口文件或者有些中间生成的文件,过期之后,有些需要归档,以供不时之需,有些就可以直接删了(这个我喜欢)。
这部分的处理最好写个统一的程序,对所有过期的文件进行处理,当需要过期的数据时,也方便取回。
3.6 过期数据处理
同理,数据也有一个生命周期,当绝大多数都用不到时,就需要对它进行处理了,否则性能,管理,存储都会是一个大问题。对于数据量很大的表,就是delete掉那些数据耗费的时间也是很惊人的了。还好,各个数据库厂商都提供了分区表这个东西,detach表分区还是相当快的。当然,将表分区,还得考滤管理,维护,性能方面的问题。充分利用数据库提供的大数据量的操作方式,将过期数据进行归档删除。
做此操作时,尽量将此表的其他相关操作都停掉,避免产生死锁或者严重的锁等待。当然,这个也是一个程序实现好了。
第4章 ETL实现
4.1 总体实现
设计完了,那实现就开始了。设计时可以不关心具体用什么产品,什么技术,实现时就很得关心这些东西的优劣了。
现在得根据设计时的方式,创建ETL接口文件、临时文件、中间文件、程序、日志等的存放方式; DS JOB中用到的参数的存放,传递等等这些问题。再对需要的程序和DS的东东进行开发。
Job要联接数据库,一般都是通过数据库客户端的方式,这样,需要在在Engine下的dsenv文件中配置数据库客户端的联接方式,同时在DS用户(默认是dsadm)的.profile文件中进行配置。
另外,Scratch目录存放DS进行运算时自己生成的临时文件,如果文件很大,进行排序等操作时此目录会占用很大的空间。Datasets存放DS Data SetsStage生成的文件。所以这两个目录需要特别注意。
DS JOB中用到的参数一般有三种方式:一种是在DS Administrator中定义,在JOB中调用;另一种方式是在参数文件或者参数表中定义,用程序调用,赋给相应的JOB;第三种是将两者混合使用,基本固定不变的参数(如ETL根路径、数据库用户名、密码)在DS Administrator中设置,经常变化的参数(如接口时间)在参数文件或者参数表中定义。
DS Administrator中定义的参数如下
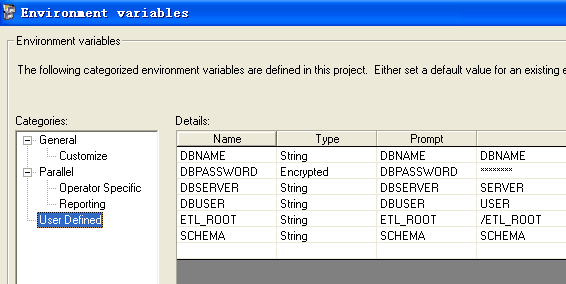
4.2 调度
调度的复杂程度,决定了调度的方式。
对于调度比较简单的,可以用SequenceJob将相关JOB串联起来,不同Sequence Job间的依赖,可以用消息文件或者数据库记录的方式,最后直接在Director中配置调度时间。而对于需要记录执行情况日志的,则可以再做一层通用的Job,在此Job的Job Control中,用basic写通用的方式调度其下的E T L Job,并将其记录日志,参数就是Job的名称和时间等。其实就是此类Job调用E T L Job,然后再用Sequence Job调用他们。
而对于比较复杂的,就得单独开发独立的程序了。可以在配置表中将不同JOB的执行时间,依赖条件,优先级,顺序乱序执行等信息配置进去,写程序(Shell, Python, Java等)根据不同的情况,按照不同的方式执行,调用DS提供的接口dsJob对JOB进行控制,并将重要的步骤记录到日志表中。而对于重传等操作,可以通过更改日志表中的状态来执行。配置的JOB可以是E T L Job,也可以是Sequence Job。
4.3 Parallel Job VS Server Job
E T L用到的Job有Server Job, ParallelJob, Mainframe Job(专供大型机上用的),一般情况下就是ServerJob, Parallel Job了。从一类Job转到另一类Job,跟从一个开发工具转到另一个开发工具一样,让人感到很陌生。项目中是用Server Job合适,还是Parallel Job合适?以下是他们之间的一个比较(直接从网上copy的):
1) The basic difference between server and parallel Jobs is thedegree of parallelism. Server Job Stages do not have in built partitoning andparallelism mechanism for extracting and loading data between different Stages.
• All you can do to enhance the speed and perormance in server Jobs is toenable inter process row buffering through the administrator. This helps Stagesto exchange data as soon as it is available in the link.
• You could use IPC Stage too which helps one passive Stage read data fromanother as soon as data is available. In other words, Stages do not have towait for the entire set of records to be read first and then transferred to thenext Stage. Link partitioner and link collector Stages can be used to achieve acertain degree of partitioning paralellism.
• All of the above features which have to be explored in server Jobs are builtin dataStage Px.
2) The Px engine runs on amultiprocessor system and takes full advantage of the processing nodes definedin the configuration file. Both SMP and MMP architecture is supported by dataStagePx.
3) Px takes advantage of bothpipeline parallelism and partitoning paralellism. Pipeline parallelism meansthat as soon as data is available between Stages( in pipes or links), it can beexchanged between them without waiting for the entire record set to be read.Partitioning parallelism means that entire record set is partitioned into smallsets and processed on different nodes(logical processors). For example if thereare 100 records, then if there are 4 logical nodes then each node would process25 records each. This enhances the speed at which loading takes place to anamazing degree. Imagine situations where billions of records have to be loadeddaily. This is where dataStage PX comes as a boon for ETL process and surpassesall other ETL tools in the market.
4) In parallel we have Dataset whichacts as the intermediate data storage in the linked list, it is the beststorage option it stores the data in dataStage internal format.
5) In parallel we can choose todisplay OSH ,which gives information about the how Job works.
6) In Parallel Transformer there isno reference link possibility, in server Stage reference could be given totransformer. Parallel Stage can use both basic and parallel oriented functions.
7) DataStage server executed by dataStageserver environment but parallel executed under control of dataStage runtimeenvironment
8) DataStage compiled in toBASIC(interpreted pseudo code) and Parallel compiled to OSH(Orchestrate Scripting Language).
9) Debugging and Testing Stages areavailable only in the Parallel Extender.
10) More Processing Stages are notincluded in Server example, Join, CDC, Lookup etc…..
11) In File Stages, Hash fileavailable only in Server and Complex falat file , dataset , lookup file setavail in parallel only.
12) Server Transformer supports basictransforms only, but in parallel both basic and parallel transforms.
13) Server transformer is basiclanguage compatability, pararllel transformer is c++ language compatabillity
14) Look up of sequntial file ispossible in parallel Jobs
15) . In parallel we can specify morefile paths to fetch data from using file pattern similar to Folder Stage in Server,while in server we can specify one file name in one O/P link.
16). We can simulteneously give inputas well as output link to a seq. file Stage in Server. But an output link inparallel means a reject link, that is a link that collects records that fail toload into the sequential file for some reasons.
17). The difference is file sizeRestriction. Sequential file size in server is : 2GB; Sequential file size inparallel is : No Limitation.
18). Parallel sequential file hasfilter options too. Where you can specify the file pattern.
除此之外,还有很多细节是相差很大的,做时需要注意。使用时很简单的感觉,Server Job可以很容易的上手,开发也很快,性能就差一些(就像MySQL);Parallel Job要求很严格,掌握起来有点难,但性能很强劲(就像DB2)。
4.4 JOB和Stage
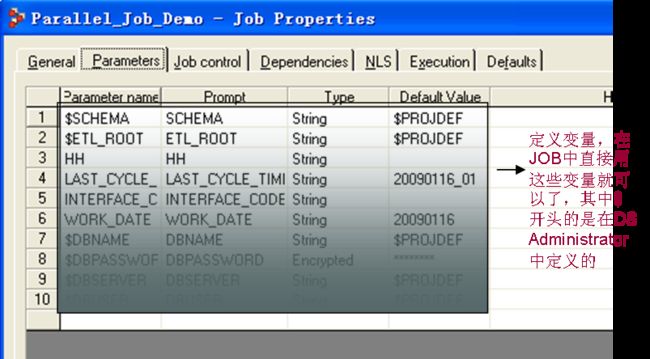
Server Job和Paralel Job都是利用各种不同功能的Stage的组合,实现具体的E T L功能,而Job Sequence则是将Server Job或者Parallel Job或者Job Sequence连接起来,实现Job间的依赖等。JOB中用到的参数,在DS Administrator中定义的,可以直接引用,在参数文件或者参数表中定义的,就得用程序调用赋给相应的JOB了。
数据仓库中用到的事实表,维表,缓慢变化维,增量,全量等等概念,在DS中没有直接对应的Stage,和用SQL一样,需要我们编程实现相应的逻辑。
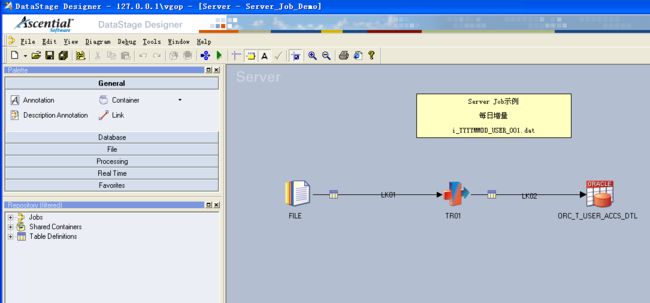
下面两个示例,实现的功能都是一样的,都是从文本文件中读取数据,进行简单的字段类型转换后,入库。只不过是Parallel Job是入DB2,Server Job是入Oracle。
4.4.1 Parallel Job和Stage
一般我们创建一个Job,大概都是如下的样子。和写程序实现一样,我们需要知道源和目标是什么,中间做什么处理,然后实现之。用DS也是一样,只是将不同的Stage组合起来,实现相应的功能。Job和Stage中还有很多其他的东西,只是用了最经常用的功能和Stage进行示例。
这个Job就是先将同一周期的数据删掉,然后从Sequential File Stage中按照定义的接口规范读取数据,在TransformerStage中对字段进行转换,最后在DB2 Stage中将其入库。
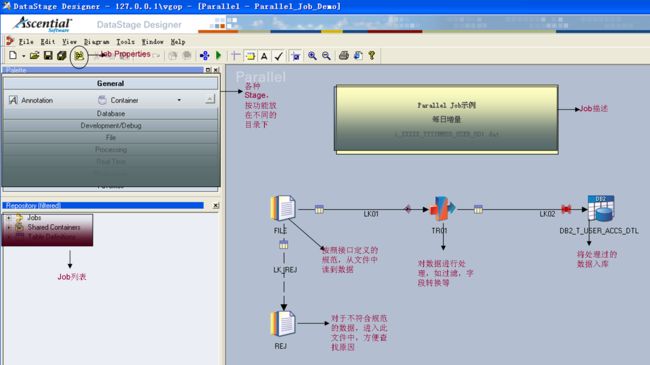
其他复杂的Job也大概是这样,也都是按照实现的功能,将不同的Stage组合起来。
Job中用到的参数都是在Job Properties中定义的,另外一些通用的功能(执行前对一些文件的处理)也是在这里实现的
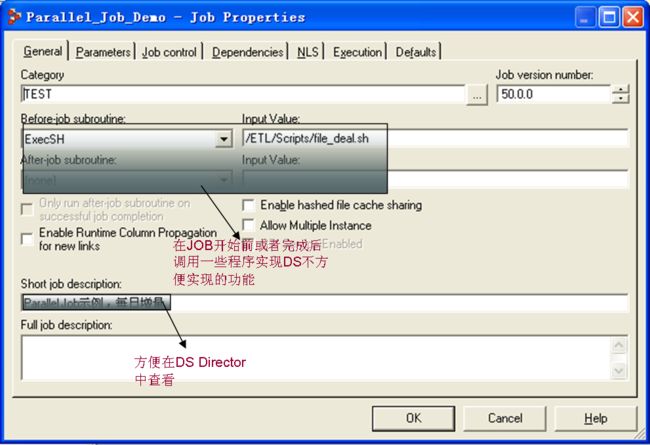
Parallel Job和Server Job这方面基本上是一样的。接下来,就按照顺序一个一个Stage大概说一下。先看一下Sequential FileStage
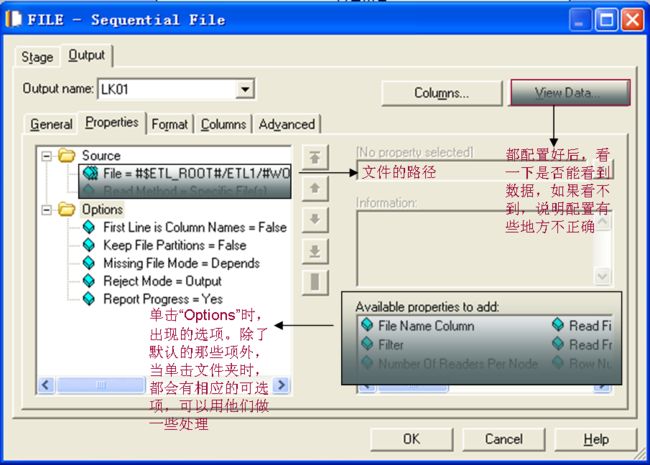
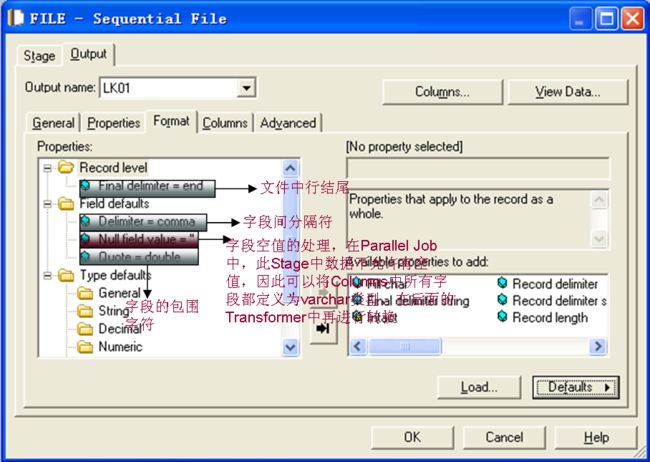
配置好文件路径和其他参数后,就ViewData一下,好多错误都是因为配置不对引起的。文本文件的操作,都是用Sequential FileStage。对于中间用到的文件,可以用Data SetStage,这个是DS内部实现的,性能很好。
读到数据后,就用Transformer执行类型转换、源和目标的字段映射等。ETL中用到的源和目标字段的对应关系,都是通过ActiveStage以“拉线”的方式实现的。没有办法在参数表中定义好,在此引用。倒是可以用文档记录不同的源和目标之间的映射关系。整个E T L,也都是用Passive 读到数据后,用不同的Active Stage组合,实现关联、去重、转换等。
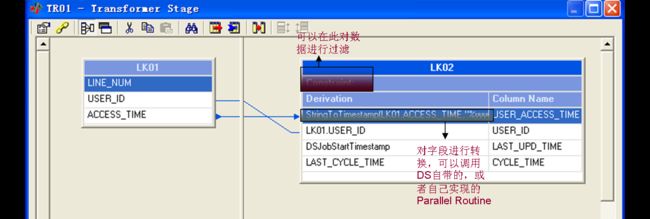
其中字段LAST_UPD_TIME和CYCLE_TIME是我们在ETL中用到的,LAST_UPD_TIME表示这批数据的实际入库时间,CYCLE_TIME表示这一批数据的数据时间,当然根据项目需要,可以添加其他的字段来标示。对于增量的Job,每次执行前都是先将同一CYCLE_TIME的数据删掉,然后入库,这样做就是为了支持重做。对于全量JOB,都是将表中的数据Truncate掉,然后入库。
处理完后,就可以入库了
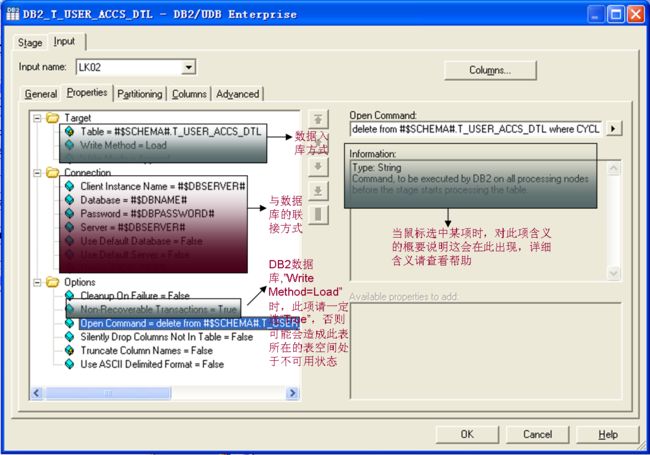
与DB2相关的Stage在Parallel Job中也有三个: DB2/UDB Enterprise, DB2/UDB API, DB2/UDB Load,默认的是DB2/UDB Enterprise,它是用DB2客户端的方式与DB2数据库管理系统进行联接,充分利用DB2实现的特有功能,性能很好,是大数据量操作的首选。这个Job是增量入库,所以在执行前,在OpenCommand中执行了删除操作。
注:用Sequential File做为源时,在Parallel Job中必须有拒绝文件。
4.4.2 Server Job和Stage
这个Server Job实现的功能与上面的Parallel Job实现的功能完全一样。但是具体到Stage,虽然名称一样,里面的配置方式和可选项却是大不一样。接下来我们就领略一下。先看一下整体风貌
基本一样,就是少了一个拒绝文件,这是因为在Server Job中Sequential File做为源时,不用拒绝文件。Job Properties中的功能和配置方式基本一样,就不罗嗦了。首先,我们先打开Sequential File,这有什么呀,还能和ParallelJob中不一样?
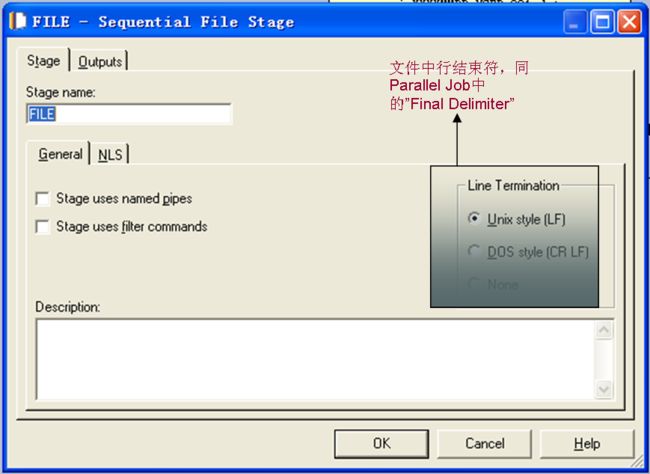
不是吧,是不是搞错了?很不幸,没有搞错。在接下来的几个Stage中你也会发现相差很大。在Parallel Job中,Stage的参数比较多,除了默认的几个外,还有些备选的,而且都是以文字的形式,一列排下来的,而在Server Job中,参数比较少,都以上面的方式在面板上排放。下面是Format的选项,可以选择的很少,比较简单吧
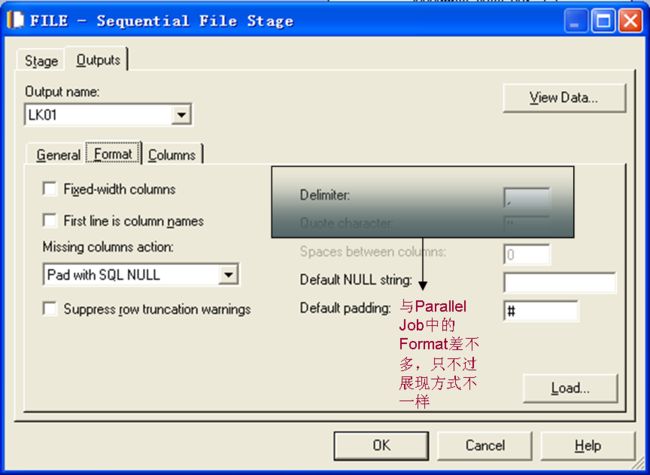
再看一看Transformer,是不是也变得不认识了
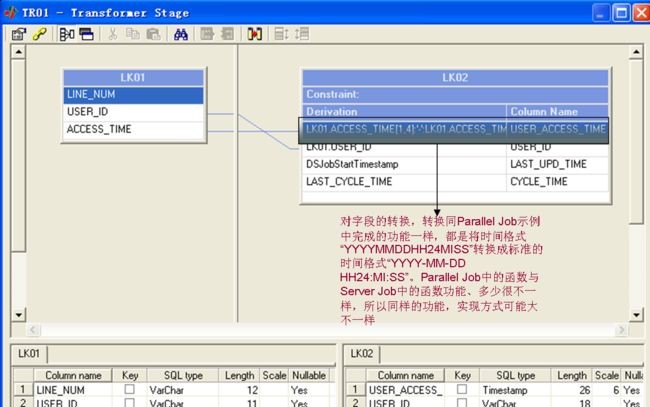
好像没有变,是样子没变,和ParallelJob的功能相差很大。在Server Job中,相对于Parallel Job Stage就少多了,那这些缺少的功能是怎么实现的呢?基本是用Transformer实现的,而Parallel Job中的Transformer的功能倒是相对比较少。
下面就再看看入库的OracleStage,在Server Job中没有Oracle Enterprise,也没有DB2Engterprise,性能上要大大缩水了。
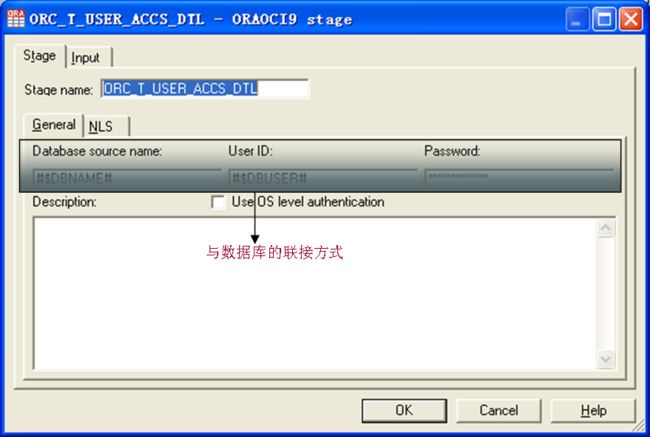
OracleStage与Sequential File Stage风格一样,习惯了一个,另一个也就习惯了。
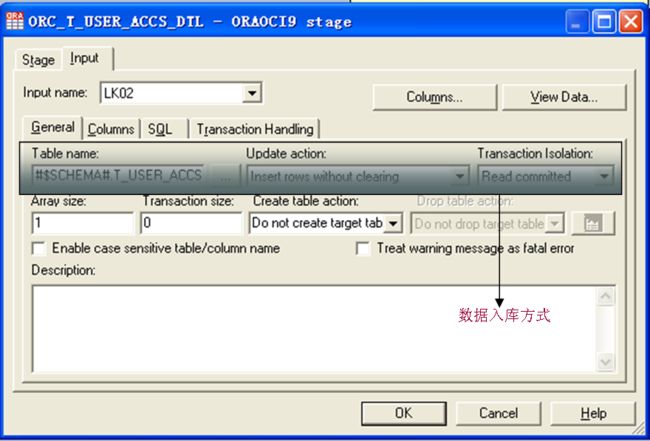
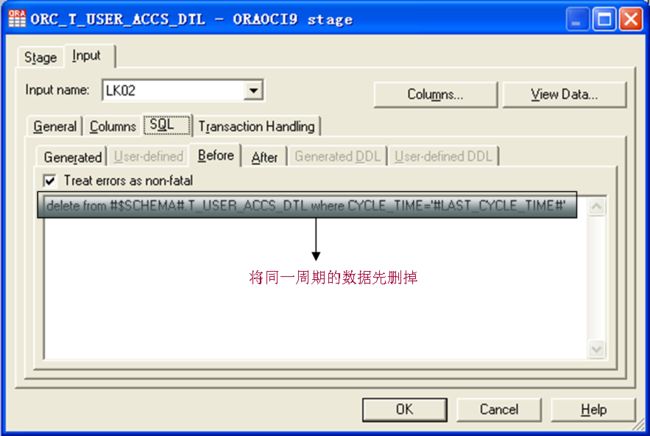
删除的操作,也得放在“SQL”中的“Before”中了,功能同Parallel Job DB2Enterprise中的“Open Command”了。另外,可以在“Generated”中看到生成的入库的SQL,可以据此判断配置的是否正确。
上面用了两个最简单的JOB做了示例,从示例中可以看到,Server Job与Parallel Job的实现方式基本一样,只不过他们用到的Stage的“长相”相差比较大。另外,ParallelJob中有多得多的Stage可以选择,用他们的组合可以实现很复杂,很强大的功能,前提是对这些Stage的能力,优缺点有个清楚的认识。不过,刚开始时,可以只熟悉一些常用的Stage,然后用时再考虑。
这些Stage将功能都进行了封装,除了那些选项外,其他的不能添加、修改,其灵活性就差一些。一旦读到数据,无论是从数据文件还是从数据库中读到的,其操作方式就完全一样了,不用关心数据来自哪里。
上面这两个示例都是实现了很基本的功能,对于稍复杂的ETL,可能需要每一步都分成一个JOB,而不同的JOB间的关系可能会有依赖,互斥等,这些关系如何处理?这就用到了Job Sequence。Job Sequence也是用Stage将Parallel Job、Server Job等联接起来,再加上其他的Stage,就可以实现满足哪些条件开始执行,哪些JOB执行完成功或者失败之后,其他相关JOB才能执行,以及循环操作等功能。而且Job Sequence可以再调用Job Sequence,将其合理的组合,就可以比较好的实现ETL。
4.5 Stage权衡取舍
术业有专攻,DS提供了这么多的Stage,都是专于某类特定功能的,所以我们需要记住常用Stage的适用范围。常用Stage的适用范围和用法,详见联想网盘à文档下的《DataStage学习文档.doc》中的“常用组件使用方法”
4.6 性能优化
这个范围很广,就说点最常用的也是最废话也是很容易忽视的东西,:
1、尽早将没用的数据过滤掉,包括数据范围和字段等,无论是用DS还是数据库的存储过程。
2、用最合适的Stage,如Join Stage和Lookup Stage,Database Plug-in和ODBC,Sequentional file和DataSet功能很相近,某些情况下一种很合适,另一种用不了,或者是性能相差几十甚至上百倍。
3、充分应用操作系统,DS,数据库和自编程序的优势,如果硬件资源丰富,可以大量的应用并行化(DS的,数据库的,自编程序的多进程,多线程等),如果资源本来就很稀缺,就千万别用什么并行化的方式,会导致性能严重下降。
4、不要过早优化。说的人很多,我也不清楚啥意思,知道的帮我补充一下。
具体且有用的优化方式详见联想网盘à文档下的《DataStage学习文档.doc》中的“性能调优”。
第5章 ETL维护
5.1 自编程序的维护
把最新且正确的shell,存储过程,DS Basic等程序放在CVS,或者SVN上,这个都知道,只是做起来很难,自勉。
5.2 DS维护
有大的JOB变动,就导出一份,最好别放在DS服务器上。虽然服务器很健壮,但99.9%的努力也许就是为了可能的0.1%。
附录I. 帮助
首先也是最重要的,就是打开的DS窗口中,按F1就出来的帮助,还有自带的PDF的文档,最全的,也是最权威的。
适合新手的, http://dazheng.360doc.com 目录“DW-->tools”下本人收集的几篇入门级的文章。系统学习DS就是IBM出的红皮书《IBM InfoSphere DataStage Data Flow and Job Design》,也在联想网盘中。
遇到问题,不知道如何解决的,可以上DSMSN 群:[email protected]或者是到论坛:http://www.itpub.net/list.html讨论。
联想网盘:http://www.lenovodata.com在首页,点左下角的"原测试版登录",进去后输入“登录邮箱/密码”:[email protected]/group214752。软件和文档都是从网上找到的,仅供学习用。
附录II. DS Job状态
无论是在Job Control中用Basic调用JOB,或者是自己写的调度程序,都需要知道DS JOB的状态。以下是DS JOB常用的一些状态
Status Code |
Description |
0 |
Job is Actually Running |
1 |
Job Finished with no Warnings |
2 |
Job Finished with Warnings |
3 |
Job Finished with wit Fatal error |
11 |
Job Validated with No Warnings |
12 |
Job Validated with Warnings |
13 |
Job alidation Failed |
21 |
Job Reset Finished |
96 |
Job has Crashed |
97 |
Job was Stopped by Operator |
98 |
Job has not been Compiled |
99 |
Any Other Status |
在用的过程中,发现我们正在运行的JOB的状态返回值有时为空,不知道是不是那个版本软件的BUG。