ElasticSearch入门讲解+如何在SpringBoot中实现增删(一键删除所有)改查
目录
一、ElasticSearch入门介绍
1、整体架构预览
2、 ES简介
3、ES基本概念
4、ES的安装
5、Elasticsearch的使用场景详解
二、SpringBoot整合ES及ES的增删改查
1、SpringBoot整合ES
2、ES的增删改查
1)增
2)删
3)改
4)查
三、建议阅读文档
一、ElasticSearch入门介绍
1、整体架构预览

2、 ES简介
详情参考官方文档中文版: https://es.xiaoleilu.com/010_Intro/50_Conclusion.html
1、简介
ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2. ES特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2)实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4)支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
存在磁盘上,搜索的时候 通过内存,主要还是通过缓存的原理,所以 你给缓存足够大的内存 ,搜索的时候 基本上都是通过内存 搜索的,所以快
3、ES基本概念
1)索引(index)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。
索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。
一个ES集群中可以按需创建任意数目的索引。
2)类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。
例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
3)文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
相当于mysql表中的一行
4)映射(Mapping)
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。另外,ES还提供了额外功能,例如将域中的内容按需排序。事实上,ES也能自动根据其值确定域的类型。
5)节点(Node)
运行了单个实例的ES主机称为节点,它是集群的一个成员,可以存储数据、参与集群索引及搜索操作。类似于集群,节点靠其名称进行标识,默认为启动时自动生成的随机Marvel字符名称。用户可以按需要自定义任何希望使用的名称,但出于管理的目的,此名称应该尽可能有较好的识别性。节点通过为其配置的ES集群名称确定其所要加入的集群。
6)集群(cluster)
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
7) 分片(Shard)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
Shard有两种类型:primary和replica,即主shard及副本shard。Primary shard用于文档存储,每个新的索引会自动创建5个Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。
ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
8)副本(Replica)
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
9)ELK
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。、
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作
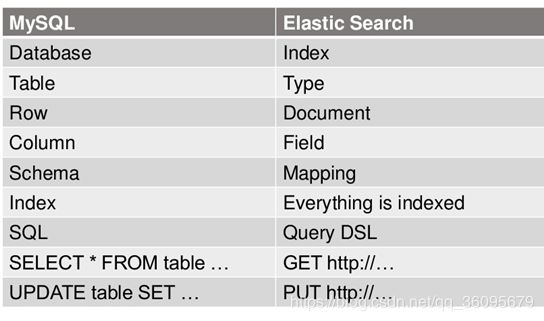
10)数据结构 与mysql对比
4、ES的安装
请下载文档:在Linux系统安装elasticsearch步骤+ElasticSearch基础讲解.docx
5、Elasticsearch的使用场景详解
1、场景—:使用Elasticsearch作为主要的后端
2、场景二:在现有系统中增加elasticsearch
3、场景三:使用elasticsearch和现有的工具
详细情况,请阅读博文:https://blog.csdn.net/laoyang360/article/details/52227541
二、SpringBoot整合ES及ES的增删改查
1、SpringBoot整合ES
1)创建SpringBoot项目,导入jar包
org.elasticsearch.client
transport
5.5.3
*
transport-netty4-client
org.elasticsearch.plugin
transport-netty4-client
5.5.3
org.elasticsearch
elasticsearch
5.5.3
org.elasticsearch.plugin
delete-by-query
2.4.1
org.apache.logging.log4j
log4j-core
2.6.2
2)config配置文件
package xmcc.mll_es_8083.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.net.InetAddress;
import java.net.InetSocketAddress;
import java.net.UnknownHostException;
@Configuration
public class ElasticsearchConfig {
@Bean
public TransportClient client() throws UnknownHostException{
//注意这儿是tcp链接 是9300
TransportAddress transportAddress = new InetSocketTransportAddress(InetAddress.getByName("192.168.1.170"), 9300);
//集群配置 设置集群名称
// Settings settings = Settings.builder().put("cluster.name", "xmcc").build();
// TransportClient preBuiltTransportClient = new PreBuiltTransportClient(settings);
//单机配置
TransportClient preBuiltTransportClient = new PreBuiltTransportClient(Settings.EMPTY);
preBuiltTransportClient.addTransportAddress(transportAddress);
return preBuiltTransportClient;
}
}
2、ES的增删改查
写在前面:存储数据的实体类EsProduct如下;
package xmcc.mll_es_8083.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class EsProduct implements Serializable {
private long productId;
private String title;
private String sell_point;
private double price;
private Date create_time;
private String category;
private String brand;
}复杂查询的实体类如下:
package xmcc.mll_es_8083.dto;
import io.swagger.annotations.ApiModel;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@ApiModel("查询 Dto")
public class QueryProductDto {
//输入框输入
private String keyWord;
//选购热点
private String sell_point;
//价格区间:格式:100-200
private String price;
//是否根据上架时间排序 新上架在前
private boolean create_timeBoolean;
//分类
private String category;
//品牌
private String brand;
//当前页码,从0页开始
private int page;
}
1)增
根据需要存储的数据创建对应的实体类EsProduct
public ResultResponse addProduct(EsProduct esProduct) throws IOException, ParseException {
log.info("添加的数据为:{}", esProduct);
//参数1:输入索引=mysql的dataBase 参数2:type名称=mysql中的表名
IndexResponse indexResponse = transportClient.prepareIndex("mll", "product").
//指定json字符串
setSource(JsonUtil.object2string(esProduct), XContentType.JSON).get();
//返回查看数据是否成功
return ResultResponse.success(indexResponse);
}2)删
根据条件删除部分数据
//根据某个条件删除文档数据
public ResultResponse deleteProduct(long productId ){
//根据productId删除对应数据
DeleteByQueryRequestBuilder builder = DeleteByQueryAction.INSTANCE
.newRequestBuilder(transportClient)
.filter(QueryBuilders.termQuery("productId", productId)).source("mll");
BulkByScrollResponse response = builder.get();
long deleted = response.getDeleted();
log.info("删除的条数为:{}",deleted);
return ResultResponse.success();
}
一键删除所有数据
//一键删除所有 删除条件不设置即可
DeleteByQueryRequestBuilder builder = DeleteByQueryAction.INSTANCE
.newRequestBuilder(transportClient)
.filter(QueryBuilders.boolQuery()).
source("mll");
BulkByScrollResponse response = builder.get();
long deleted = response.getDeleted();
log.info("删除的条数为:{}", deleted);3)改
public ResultResponse updateProduct(EsProduct esProduct) throws IOException, ParseException {
log.info("修改的数据为:{}", esProduct);
//输入索引 与type名称 这儿的es id就直接写死了
// TODO:业务逻辑肯定是先查询到ES自动生成的id然后再修改
UpdateResponse updateResponse = transportClient.prepareUpdate("mll", "product", "AWsdQhh8klBAmP0UjTSR").
//指定json字符串
setDoc(JsonUtil.object2string(esProduct), XContentType.JSON).get();
if (updateResponse.status() == RestStatus.OK) {
return ResultResponse.success();
}
return ResultResponse.fail();
}4)查
该处直接展示复杂查询,即根据可输入查询条件创建对应的实体类QueryProductDto,判断实体类属性是否为null,设置对应的过滤条件
public ResultResponse query(QueryProductDto productDto) {
log.info("查询的数据为:{}", productDto);
//通过基本的bool查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//创建查询对象 setTypes可以加入多个类型
SearchRequestBuilder searchRequestBuilder = transportClient.
prepareSearch("mll").setTypes("product");
//先对查询数据进行判断 如果不为空 就添加查询数据 前面是字段名
//输入框输入
if (productDto.getKeyWord()!= null) {
log.warn("KeyWord查询:{}",productDto.getKeyWord());
boolQueryBuilder.must(
//根据关键字查询 只要下面的字段中包含该数据,有的词语分词里面没有就查询不到,就需要前面学习的去自定义
// 就会被查询到 这儿使用title与sell_point
QueryBuilders.multiMatchQuery(
productDto.getKeyWord(),
"title", "sell_point"
)
);
}
//选购热点
if (productDto.getSell_point()!=null){
log.warn("Sell_point查询:{}",productDto.getSell_point());
boolQueryBuilder.filter(QueryBuilders.termQuery(
"sell_point", productDto.getSell_point()));
}
//分类
if (productDto.getCategory()!=null){
log.warn("Category查询:{}",productDto.getCategory());
boolQueryBuilder.filter(QueryBuilders.termQuery
("category", productDto.getCategory()));
}
//品牌
if (productDto.getBrand()!=null){
log.warn("Brand查询:{}",productDto.getBrand());
boolQueryBuilder.filter(QueryBuilders.termQuery
("brand", productDto.getBrand()));
}
//根据上架时间排序 新上架在前
if (productDto.isCreate_timeBoolean()){
log.warn("Create_timeBoolean查询:{}",productDto.isCreate_timeBoolean());
searchRequestBuilder.addSort("create_time",SortOrder.DESC );
}
//价格区间:格式:100-200
if (productDto.getPrice()!=null){
String price = productDto.getPrice();
log.warn("price查询:{}",price);
String[] strings = price.split("-");
searchRequestBuilder.setPostFilter(QueryBuilders.rangeQuery
("price").from(strings[0]).to(strings[1]));
}
//查询条件
searchRequestBuilder.setQuery(boolQueryBuilder)
//翻页 从第几条开始 查询多少条
.setFrom(productDto.getPage())
.setSize(3);
log.info("查询到的数据为:{}", searchRequestBuilder.toString());
//获得查询需要的数据结果
SearchResponse searchResponse = searchRequestBuilder.get();
//判断是否正常
if (searchResponse.status() != RestStatus.OK) {
log.warn("es查询数据异常,返回状态为:{}", searchResponse.status());
return ResultResponse.fail();
}
//获得结果集
SearchHits hits = searchResponse.getHits();
List products = new ArrayList<>();
//遍历组装数据
for (SearchHit hit : hits) {
//字段名 这里先获得两个字段测试 如果以后字段多
// 直接先把 es查询到的数据 转换为json字符串 然后再转成对象即可 ,这儿先详细的写一下
//通过这个方法获得每条对象的json字符串 hit.getSourceAsString()
// EsProduct esProduct1 = new EsProduct();
// esProduct1.setBrand(String.valueOf(hit.getSource().get("brand")));
// esProduct1.setPrice((double) hit.getSource().get("price"));
EsProduct esProduct1 = JsonUtil.string2object(hit.getSourceAsString(), new TypeReference() {
});
products.add(esProduct1);
}
return ResultResponse.success(products);
} 三、建议阅读文档
1、官方文档中文版: https://es.xiaoleilu.com/010_Intro/50_Conclusion.html
2、ES入门及其扩展:https://blog.csdn.net/makang110/article/details/80596017
3、Elasticsearch的使用场景深入详解:https://blog.csdn.net/laoyang360/article/details/52227541