python(二十)——树状目录层级、读写CSV、读取PDF、播放音乐
目录
树状目录层级
treeFile
InfoWindow
读写CSV文件
读CSV的对象
将数据写入csv数据中
读取PDF文件
安装pdfminer模块
建立readPdf方法去读取pdf中的文字
播放音乐
树状目录层级
treeFile
代码:
import tkinter
from tkinter import ttk
import os
class TreeWindow(tkinter.Frame):
def __init__(self,master,path):
frame = tkinter.Frame(master)
frame.pack()
self.tree = ttk.Treeview(frame)
self.tree.pack()
root = self.tree.insert("","end",text=self.getlastPath(path),open=True)
self.loadTree(root,path)
def loadTree(self,parent,path):
for filepath in os.listdir(path):
#文件的绝对路径
abs = os.path.join(path,filepath)
#插入树枝
treey = self.tree.insert(parent,"end",text=self.getlastPath(filepath))
#判断是否是目录,是目录再去添加树枝,使用递归
if os.path.isdir(abs):
self.loadTree(treey,abs)
#求文件的最后一个名字
def getlastPath(self,path):
pathList = os.path.split(path)
return pathList[-1]
#创建主窗口
win = tkinter.Tk()
win.title("主界面")
win.geometry("300x300")
path = "F:\pycharm\pythwork"
treewin = TreeWindow(win,path)
win.mainloop()运行结果:
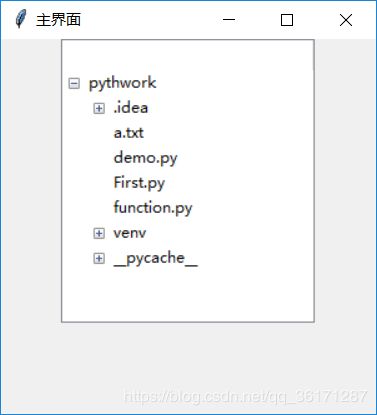
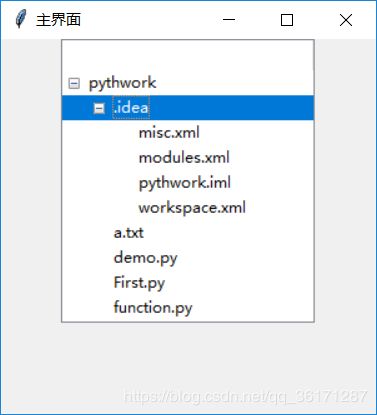
InfoWindow
代码:
class InfoWindows(tkinter.Frame):
# master父节点
def __init__(self,master):
frame = tkinter.Frame(master)
#将frame设为0行0列
frame.grid(row=0,column=0)
#在frame上创建entry
self.entry = tkinter.Entry(frame)
self.entry.pack()
# 在frame上创建txt
self.txt = tkinter.Text(frame)
self.txt.pack()
#创建主窗口
win = tkinter.Tk()
win.title("主界面")
win.geometry("300x300")
path = "F:\pycharm\pythwork"
#treewin = TreeWindow(win,path)
infowin = InfoWindows(win)
win.mainloop()运行结果:
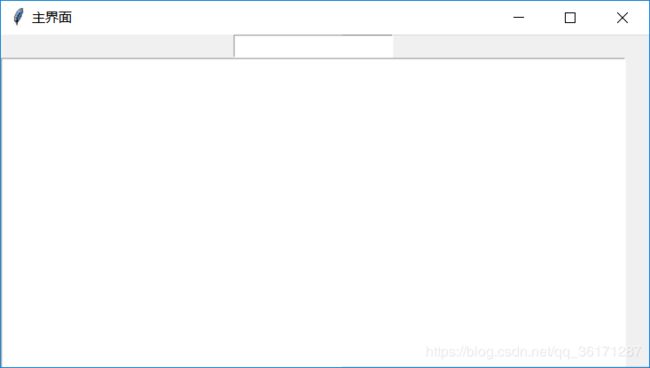
将treeFile和InfoWindow相结合
代码:
import tkinter
from tkinter import ttk
import os
class TreeWindow(tkinter.Frame):
def __init__(self,master,path,otherwin):
frame = tkinter.Frame(master)
frame.grid(row=0,column=0)
self.otherwin = otherwin
self.tree = ttk.Treeview(frame)
self.tree.pack()
root = self.tree.insert("","end",text=self.getlastPath(path),open=True,values=(path))
self.loadTree(root,path)
# 滚动条
# self.sy = tkinter.Scrollbar(frame)
# self.sy.pack(side=tkinter.RIGHT, fill=tkinter.Y)
# self.sy.config(command=self.tree.yview)
# self.tree.config(yscrollcommand=self.sy.set)
#绑定事件
self.tree.bind("<>",self.func)
def func(self,event):
#提取文件或目录的名字
self.v = event.widget.selection()
for sv in self.v:
fill = self.tree.item(sv)["text"]
self.otherwin.ev.set(fill)
print(fill)
apath = self.tree.item(sv)["values"][0]
print(apath)
def loadTree(self,parent,path):
for filepath in os.listdir(path):
#文件的绝对路径
abs = os.path.join(path,filepath)
#插入树枝
treey = self.tree.insert(parent,"end",text=self.getlastPath(filepath),values=(abs))
#判断是否是目录,是目录再去添加树枝,使用递归
if os.path.isdir(abs):
self.loadTree(treey,abs)
#求文件的最后一个名字
def getlastPath(self,path):
pathList = os.path.split(path)
return pathList[-1]
class InfoWindows(tkinter.Frame):
# master父节点
def __init__(self,master):
frame = tkinter.Frame(master)
#将frame设为0行0列
frame.grid(row=0,column=1)
self.ev = tkinter.Variable()
#在frame上创建entry
self.entry = tkinter.Entry(frame,textvariable=self.ev)
self.entry.pack()
# 在frame上创建txt
self.txt = tkinter.Text(frame)
self.txt.pack()
#创建主窗口
win = tkinter.Tk()
win.title("主界面")
win.geometry("300x300")
path = "F:\pycharm\pythwork"
infowin = InfoWindows(win)
treewin = TreeWindow(win,path,infowin)
win.mainloop()
运行结果:
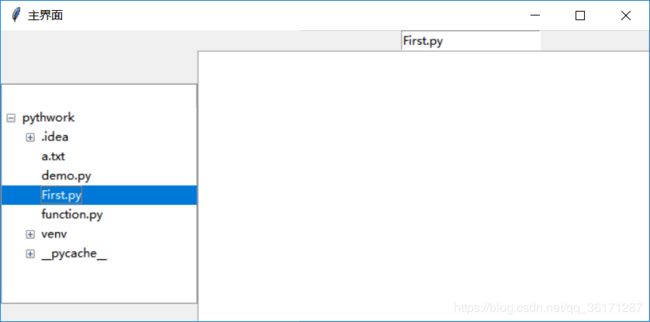

读写CSV文件
csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据。csv文件格式是一种通用的电子表格和数据库导入导出格式。
读CSV的对象


代码:
import csv
def readCsv(path):
with open(path,"r") as f:
allfileinfo = csv.reader(f)
print(allfileinfo)
path = r"F:\pycharm\pythwork\a.csv"
readCsv(path)运行结果 :csv对象和存储地址

在readCsv方法中加上代码:就可以读取csv中的数据
for i in allfileinfo:
print(i)程序运行结果:

最终读CSV文件的方法:readCsv()
import csv
def readCsv(path):
infolist = []
with open(path,"r") as f:
allfileinfo = csv.reader(f)
print(allfileinfo)
for i in allfileinfo:
infolist.append(i)
return infolist
path = r"F:\pycharm\pythwork\a.csv"
i = readCsv(path)
for a in i:
print(a)
将数据写入csv数据中
import csv
def writeCsv(path,data):
with open(path,'w') as f:
writer = csv.writer(f)
for row in data:
writer.writerow(row)
path = r"F:\pycharm\pythwork\a.csv"
writeCsv(path,[[0,1,2],[3,4,5],[7,8,9]])运行结果:

读取PDF文件
读取PDF文件需要安装pdfminer模块,安装方法可以直接通过pycharm安装,也可以通过cmd输入pip安装
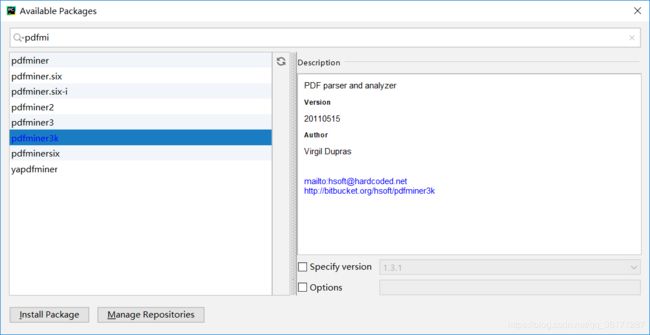
安装pdfminer模块
直接可以通过pip安装
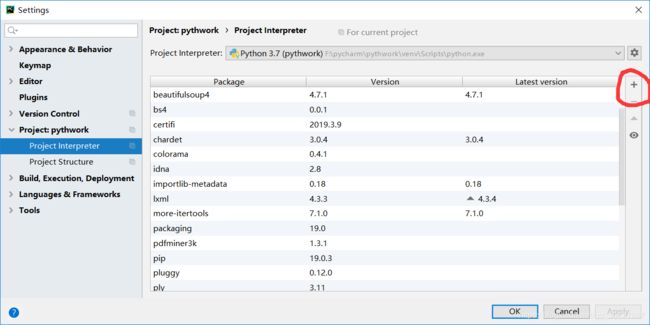
pip install pdfminer3k通过pycharm安装
建立readPdf方法去读取pdf中的文字
代码如下:
import sys
import importlib
importlib.reload(sys)
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager,PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
def readPdf(path,topath):
#以二进制形式打开pdf文件
f = open(path,'rb')
#创建一个pdf文档分析器
parser = PDFParser(f)
#创建pdf文档
pdffile = PDFDocument()
#链接刚刚创建的分析器和文档,文档和分析器就存在关联了
parser.set_document(pdffile)
pdffile.set_parser(parser)
#提供初始化密码
pdffile.initialize()
#检测文档是否提供txt转换
if not pdffile.is_extractable:
raise PDFTextExtractionNotAllowed
else:
#解析数据
#需要一个数据管理器
manager = PDFResourceManager()
#创建一个pdf设备对象
laparam = LAParams()
device = PDFPageAggregator(manager,laparams=laparam)
#创建解释器对象
interpreter = PDFPageInterpreter(manager,device)
#开始循环处理,每次处理一页get_pages()
print(pdffile.get_pages())
for page in pdffile.get_pages():
interpreter.process_page(page)
#处理图层
layout = device.get_result()
for x in layout:
#isinstance()判断类型,判断x的类型是否是LTTextBoxHorizontal
if(isinstance(x,LTTextBoxHorizontal)):
with open(topath,'a') as f:
str = x.get_text()
print(str)
f.write(str+'\n')
path = r"C:\Users\asus\Desktop\数据挖掘\数据仓库上机操作手册.pdf"
topath = r"C:\Users\asus\Desktop\数据挖掘\wd.txt"
readPdf(path,topath)运行结果:


播放音乐
需要下载安装pygame模块,使用pip install pygame语句或者在pycharm中直接安装
主要是使用pygame中的方法,
- play()是播放音乐
- pause()是暂停音乐
- stop()停止音乐播放
用time去控制播放音乐的时长
简单的音乐播放代码:

import pygame
import time
#音乐路径
filepath = r'周杰伦 - 稻香.mp3'
#初始化
pygame.mixer.init()
#加载音乐
track = pygame.mixer.music.load(filepath)
#播放音乐
pygame.mixer.music.play()
#播放时长
time.sleep(200)
#暂停播放
#pygame.mixer.music.pause()
#停止播放
pygame.mixer.music.stop()
使用python代码打开注册表
import win32con
import win32api
import win32gui
#打开注册表的HKEY_CURRENT_USER,在Control的Panel的Desktop中设置数据
reg_key = win32api.RegOpenKeyEx(win32con.HKEY_CURRENT_USER,"Control Panel\\Desktop",0,win32con.KEY_SET_VALUE)
一起学习,一起进步 -.- ,如有错误,可以发评论