hive增加Update、Delete支持
一、配置hive-site.xml
CDH版本先进入Hive配置页 
选择高级,找到hive-site.xml 的 Hive 客户端高级配置代码段配置项 
点击+号,增加如下配置项
hive.support.concurrency = truehive.enforce.bucketing = truehive.exec.dynamic.partition.mode = nonstricthive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManagerhive.compactor.initiator.on = truehive.compactor.worker.threads = 1
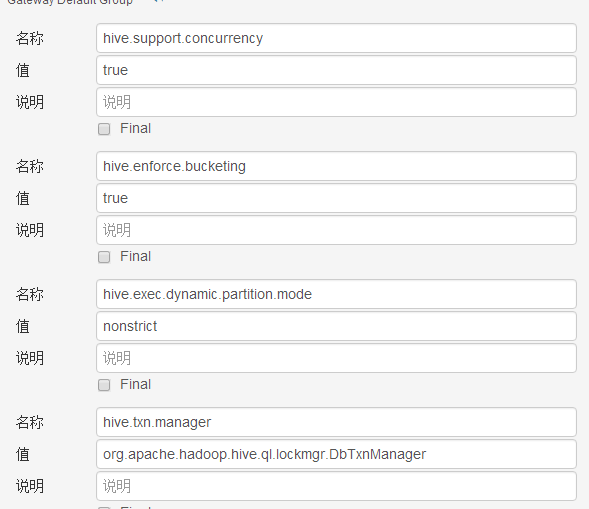
然后点击保存更改,分发配置就可以了。
二、建表
如果要支持delete和update,则必须输出是AcidOutputFormat然后必须分桶。
而且目前只有ORCFileformat支持AcidOutputFormat,不仅如此建表时必须指定参数('transactional' = true)
如
USE test;DROP TABLE IF EXISTS S1_AC_ACTUAL_PAYDETAIL;CREATE TABLE IF NOT EXISTS S1_AC_ACTUAL_PAYDETAIL(INPUTDATE STRING,SERIALNO STRING,PAYDATE STRING,ACTUALPAYDATE STRING,CITY STRING,PRODUCTID STRING,SUBPRODUCTTYPE STRING,ISP2P STRING,ISCANCEL STRING,CDATE STRING,PAYTYPE STRING,ASSETSOWNER STRING,ASSETSOUTDATE STRING,CPD DOUBLE,PAYPRINCIPALAMT BIGINT,PAYINTEAMT BIGINT,A2 BIGINT,A7 BIGINT,A9 BIGINT,A10 BIGINT,A11 BIGINT,A12 BIGINT,A17 BIGINT,A18 BIGINT,PAYAMT BIGINT,LOANNO STRING,CREATEDATE STRING,CUSTOMERID STRING,etl_in_dt string)CLUSTERED BY (SERIALNO) --根据某个字段分桶INTO 7 BUCKETS --分为多少个桶ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','LINES TERMINATED BY '\n'STORED AS ORCLOCATION '/user/hive/test/S1_AC_ACTUAL_PAYDETAIL'TBLPROPERTIES('transactional'='true');--增加额描述信息,比如最后一次修改信息,最后一个修改人。
注:由于cdh自动的在元数据里面创建了COMPACTION_QUEUE表,所以博客中说的那个问题不存在 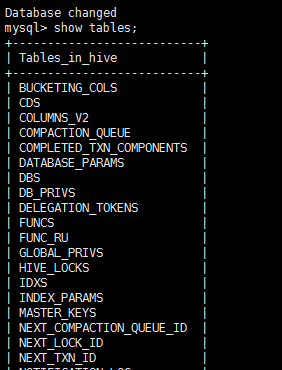
三、操作
执行
update test.S1_AC_ACTUAL_PAYDETAIL set city='023' where SERIALNO = '20688947002';
操作100条数据,平均每条花费2秒多,其中执行花费1秒左右。相对还是能接受的。
delete from test.S1_AC_ACTUAL_PAYDETAIL where SERIALNO = '20688947002';
四、总结
- 1、Hive可以通过修改参数达到修改和删除数据的效果,但是速度远远没有传统关系型数据库快
- 2、通过ORC的每个task只输出单个文件和自带索引的特性,以及数据的分桶操作,可以将要修改的数据锁定在一个很小的文件块,因此可以做到相对便捷的文件修改操作。因此数据的分桶操作非常重要,通常一些表单信息都会根据具体的表单id进行删除与修改,因此推荐使用表单ID作为分桶字段。
- 3、频繁的update和delete操作已经违背了hive的初衷。不到万不得已的情况,还是使用增量添加的方式最好。
hive0.14-insert、update、delete操作测试
首先用最普通的建表语句建一个表:
hive>create table test(id int,name string)row format delimited fields terminated by ',';
测试insert:
insert into table test values (1,'row1'),(2,'row2');结果报错:
-
java.io.FileNotFoundException: File does not exist: hdfs://127.0.0.1:9000/home/hadoop/git/hive/packaging/target/apache-hive-0.14.0-SNAPSHOT-bin/ -
apache-hive-0.14.0-SNAPSHOT-bin/lib/curator-client-2.6.0.jar -
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1128) -
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1120) -
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) -
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1120) -
at org.apache.hadoop.mapreduce.filecache.ClientDistributedCacheManager.getFileStatus(ClientDistributedCacheManager.java:288) -
at org.apache.hadoop.mapreduce.filecache.ClientDistributedCacheManager.getFileStatus(ClientDistributedCacheManager.java:224) -
at org.apache.hadoop.mapreduce.filecache.ClientDistributedCacheManager.determineTimestamps(ClientDistributedCacheManager.java:99) -
at org.apache.hadoop.mapreduce.filecache.ClientDistributedCacheManager.determineTimestampsAndCacheVisibilities(ClientDistributedCacheManager.java:57) -
at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:265) -
at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:301) -
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:389) -
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285) -
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282) -
at java.security.AccessController.doPrivileged(Native Method) -
......
貌似往hdfs上找jar包了,小问题,直接把lib下的jar包上传到hdfs
-
hadoop fs -mkdir -p /home/hadoop/git/hive/packaging/target/apache-hive-0.14.0-SNAPSHOT-bin/apache-hive-0.14.0-SNAPSHOT-bin/lib/ -
hadoop fs -put $HIVE_HOME/lib/* /home/hadoop/git/hive/packaging/target/apache-hive-0.14.0-SNAPSHOT-bin/apache-hive-0.14.0-SNAPSHOT-bin/lib/
接着运行insert,没有问题,接下来测试delete
hive>delete from test where id = 1;报错!:
FAILED: SemanticException [Error 10294]: Attempt to do update or delete using transaction manager that does not support these operations.
说是在使用的转换管理器不支持update跟delete操作。
原来要支持update操作跟delete操作,必须额外再配置一些东西,见:
https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions#HiveTransactions-NewConfigurationParametersforTransactions
根据提示配置hive-site.xml:
-
hive.support.concurrency – true -
hive.enforce.bucketing – true -
hive.exec.dynamic.partition.mode – nonstrict -
hive.txn.manager – org.apache.hadoop.hive.ql.lockmgr.DbTxnManager -
hive.compactor.initiator.on – true -
hive.compactor.worker.threads – 1
配置完以为能够顺利运行了,谁知开始报下面这个错误:
FAILED: LockException [Error 10280]: Error communicating with the metastore与元数据库出现了问题,修改log为DEBUG查看具体错误:
-
2014-11-04 14:20:14,367 DEBUG [Thread-8]: txn.CompactionTxnHandler (CompactionTxnHandler.java:findReadyToClean(265)) - Going to execute query -
cq_database, cq_table, cq_partition, cq_type, cq_run_as from COMPACTION_QUEUE where cq_state = 'r'> -
2014-11-04 14:20:14,367 ERROR [Thread-8]: txn.CompactionTxnHandler (CompactionTxnHandler.java:findReadyToClean(285)) - Unable to select next element for cleaning, -
Table 'hive.COMPACTION_QUEUE' doesn't exist -
2014-11-04 14:20:14,367 DEBUG [Thread-8]: txn.CompactionTxnHandler (CompactionTxnHandler.java:findReadyToClean(287)) - Going to rollback -
2014-11-04 14:20:14,368 ERROR [Thread-8]: compactor.Cleaner (Cleaner.java:run(143)) - Caught an exception in the main loop of compactor cleaner, MetaException(message -
:Unable to connect to transaction database com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'hive.COMPACTION_QUEUE' doesn't exist -
at sun.reflect.GeneratedConstructorAccessor19.newInstance(Unknown Source) -
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) -
at java.lang.reflect.Constructor.newInstance(Constructor.java:526) -
at com.mysql.jdbc.Util.handleNewInstance(Util.java:409)
在元数据库中找不到COMPACTION_QUEUE这个表,赶紧去mysql中查看,确实没有这个表。怎么会没有这个表呢?找了很久都没找到什么原因,查源码吧。
在org.apache.hadoop.hive.metastore.txn下的TxnDbUtil类中找到了建表语句,顺藤摸瓜,找到了下面这个方法会调用建表语句:
-
private void checkQFileTestHack() { -
boolean hackOn = HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_IN_TEST) || -
HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_IN_TEZ_TEST); -
if (hackOn) { -
LOG.info("Hacking in canned values for transaction manager"); -
// Set up the transaction/locking db in the derby metastore -
TxnDbUtil.setConfValues(conf); -
try { -
TxnDbUtil.prepDb(); -
} catch (Exception e) { -
// We may have already created the tables and thus don't need to redo it. -
if (!e.getMessage().contains("already exists")) { -
throw new RuntimeException("Unable to set up transaction database for" + -
" testing: " + e.getMessage()); -
} -
} -
} -
}
什么意思呢,就是说要运行建表语句还有一个条件:HIVE_IN_TEST或者HIVE_IN_TEZ_TEST.只有在测试环境中才能用delete,update操作,也可以理解,毕竟还没有开发完全。
终于找到原因,解决方法也很简单:在hive-site.xml中添加下面的配置:
-
-
hive.in.test -
true -
OK,再重新启动服务,再运行delete:
hive>delete from test where id = 1;又报错:
FAILED: SemanticException [Error 10297]: Attempt to do update or delete on table default.test that does not use an AcidOutputFormat or is not bucketed说是要进行delete操作的表test不是AcidOutputFormat或没有分桶。估计是要求输出是AcidOutputFormat然后必须分桶
网上查到确实如此,而且目前只有ORCFileformat支持AcidOutputFormat,不仅如此建表时必须指定参数('transactional' = true)。感觉太麻烦了。。。。
于是按照网上示例建表:
hive>create table test(id int ,name string )clustered by (id) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true');insert
hive>insert into table test values (1,'row1'),(2,'row2'),(3,'row3');delete
hive>delete from test where id = 1;
update
hive>update test set name = 'Raj' where id = 2;
OK!全部顺利运行,不过貌似效率太低了,基本都要30s左右,估计应该可以优化,再研究研究
最后还有个问题:show tables时报错:
-
hive> show tables; -
OK -
tab_name -
Failed with exception java.io.IOException:java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: fcitx-socket-:0 -
Time taken: 0.064 seconds
好像跟/tmp/下fcitx-socket-:0文件名有关,待解决。。。