机器阅读理解模型中attention的使用方式
再BiDAF模型之前,阅读理解模型中使用的attention类型大致分为三类:
1、Attention Reader:通过动态 attention 机制从文本中提取相关信息(context vector),再依据该信息给出预测结果。使用这种attention的相关论文有:
(1)Bahdanau et al. 2015. 这篇论文算是attention机制的开山之作,针对的是机器翻译任务中传统双向RNN模型的不足。传统双向RNN模型再预测下一个词时依据的是上一个预测词![]() ,隐含层状态向量
,隐含层状态向量![]() 和encoder形成的上下文向量
和encoder形成的上下文向量![]() 。这样做的缺点在于上下文信息向量
。这样做的缺点在于上下文信息向量![]() 包含了原句的所有信息,而再翻译当前词是并不需要所有信息,可能只需要原句中的个别词作为参考,这就涉及到了"对齐"的观点。因而文章将
包含了原句的所有信息,而再翻译当前词是并不需要所有信息,可能只需要原句中的个别词作为参考,这就涉及到了"对齐"的观点。因而文章将![]() 改成
改成![]() ,计算方式如下:
,计算方式如下:
 ,
, ![]() .
.
其中![]() ,其中的
,其中的![]() 是一个前馈神经网络。通过这种方式形成的上下文信息是动态的,根据当前要翻译的词决定。
是一个前馈神经网络。通过这种方式形成的上下文信息是动态的,根据当前要翻译的词决定。
(2)Hermann et al. 2015. 这篇论文率先提出了使用机器学习的方法解决机器阅读理解问题,并整理了CNN和Daily Mail websites两个数据集。同时这篇文章提出了三个神经网络模型来解决这个问题。其中第一个模型用的是Deep-LSTM,文中将document和query用||连在一起,并在上面应用两层LSTM,将每层的最后时刻的隐含层向量拼接起来得到encoder的结果。
第二个模型Attentive Reader用到了attention,为了计算document中每个词相对于query的attention值,即query-to-document attention,计算方式是,首先通过两个双向LSTM模型分别encode document和query,将query两个方向的最后时刻隐含层向量拼接在一起作为query的表示,将document每个词两个方向的隐含层向量分别拼接起来作为每个词的表示,然后通过一个tanh层计算attention值:
![]()
其中![]() 就表示文档第t个词的表示,
就表示文档第t个词的表示,![]() 是query的表示,最后得到的
是query的表示,最后得到的![]() 就是文档第t个词的attention值。
就是文档第t个词的attention值。
第三个模型叫impatient reader。和第二个模型的总体思路一致,但是在计算attention的时候不将query视作一个整体,而是每读一个query词就取document中找答案。计算attention的方式改为如下所示:
![]()
![]()
其中的![]() 代表第i个query词对应计算的文档中第t个词的attention值,同时计算第i个query词时还考虑到了前i-1个query词的选词信息,通过
代表第i个query词对应计算的文档中第t个词的attention值,同时计算第i个query词时还考虑到了前i-1个query词的选词信息,通过![]() 表示。
表示。
(3)Chen et al. 2016. 这篇文章建立在Hermann et al. 2015中第二个模型的基础上,将attention的计算方式改为:
![]()
也就是将第二个模型中的tanh层改成了一个线性模型,作者认为这样的修改会提高效果。此外,还做了一些别的修改来提高模型的运行效率。
(4)Wang & Jiang 2016. 这篇提出了一个结合matchlstm和pointer network的网络模型用于SQuad数据集,相关的模型细节参考我上一篇文章论文阅读:Machine Comprehension Using MATCH-LSTM and Answer Pointer。
以上的四个模型全都时利用attention融合文本内各个词的信息,然后通过融合的信息预测结果。
2、Attention-Sum Reader。只计算一次 attention weights,然后直接喂给输出层做最后的预测,也就是利用 attention 机制直接获取文本中各位置作为答案的概率,和 pointer network 类似的思想,效果很依赖对 query 的表示。
(1)Kadlec et al. 2016. 这篇文章中的模型前半部分与Hermann et al. 2015中的Attentive Reader的前半部分类似,得到document中每个词的表示和query的一个整体表示,然后直接使用点积计算每个document词的attention值:
![]()
其中的![]() 分别代表document中第i个词的表示和query的表示。最终预测答案时,直接将document中相同词的attention值加在一起选出值最大的词作为答案。这就体现出了Attention-Sum Reader和之前Attention Reader的不同之处,这里的attention不用于融合文本内各词得到文本信息,而是直接作为答案的概率分布,与pointer network有相似之处。
分别代表document中第i个词的表示和query的表示。最终预测答案时,直接将document中相同词的attention值加在一起选出值最大的词作为答案。这就体现出了Attention-Sum Reader和之前Attention Reader的不同之处,这里的attention不用于融合文本内各词得到文本信息,而是直接作为答案的概率分布,与pointer network有相似之处。
(2)Cui et al. 2016. 这篇文章与之前文章只考虑query-to-document attention不同,还考虑到了document-to-query attention,在计算attention之前,分别使用两个双向GRU模型编码document和query向量,将document和query中的每个词的正反双向隐含层向量连接起来作为词的表示,然后将document和query中的词表示两两计算点积得到![]() 的交互矩阵。在交互矩阵上,在每一列的向量上做softmax,这样第i列就是第i各query词对应的document的attention向量,这个矩阵就是query-to-document attention矩阵
的交互矩阵。在交互矩阵上,在每一列的向量上做softmax,这样第i列就是第i各query词对应的document的attention向量,这个矩阵就是query-to-document attention矩阵![]() 。相反,在每一行上做softmax,这样得到到第j行就时document中第j各词对应的query的attention向量,这个矩阵就是document-to-query attention矩阵。为了总体衡量query内各词的attention值,将document-to-query attention的每行attention向量取均值,得到query的总体attention向量
。相反,在每一行上做softmax,这样得到到第j行就时document中第j各词对应的query的attention向量,这个矩阵就是document-to-query attention矩阵。为了总体衡量query内各词的attention值,将document-to-query attention的每行attention向量取均值,得到query的总体attention向量![]() 。计算
。计算![]() 就得到最终document的attention向量。与Kadlec et al. 2016.中的模型一样,直接将这个attention向量作为答案的概率分布作为选取答案的依据。具体模型结构图如下:
就得到最终document的attention向量。与Kadlec et al. 2016.中的模型一样,直接将这个attention向量作为答案的概率分布作为选取答案的依据。具体模型结构图如下:

3、Multi-hop Attention。计算多次 attention。
(1)Hill et al., 2016. 使用记忆神经网络来解决阅读理解问题。文章认为传统模型中计算attention时只考虑到了局部上下文信息,使用记忆神经网络可以同时考虑局部与全局的上下文信息。同时,采用记忆神经网络可以使用多层模型,也就是Multi-hop Attention,这里我对于多层记忆神经网络用处的理解就是回答一个query需要一个推理过程,通过多层记忆神经网络不断更新query相当于模仿这个推理过程。模型中使用one-hot来对query进行编码,对document的编码方式则分为三种,分别在词、短语、句子层面进行编码。这里主要探讨attention的使用方式,所以不具体展开说。将query的表示和document每个memory slot的表示通过一个embedding矩阵A映射到同一空间内,然后通过点积与softmax得到memory slot的attention值,再将每个memory slot通过矩阵B映射得到候选的support memory集合,使用attention融合support memory信息得到输出,再使用这个输出和原query重新表示一个新的query作为下一层的输入,直到最后一层的attention值用来对答案进行预测。这篇论文中最后效果最好的模型时使用单层记忆神经网络,使用自监督学习的方式使用基于短语表示的记忆单元。这可能时数据集的特征决定的,CBT数据集时有答案候选集的,对于没有答案候选集的数据集这个模型可能不能用。
(2)Sordoni et al., 2016. 这个模型总体思路有点类似于多层的记忆神经网络,也是通过模拟推理过程来获取答案。模型最底层还是使用两个双向GRU模型对query和document进行编码,得到query和document中每个词的隐含层表示。之后,与以往模型不同的在于,本模型并不是一次性计算document各词的attention之后就用于预测答案,而是多轮计算,整体框架类似于一个大型的GRU模型。
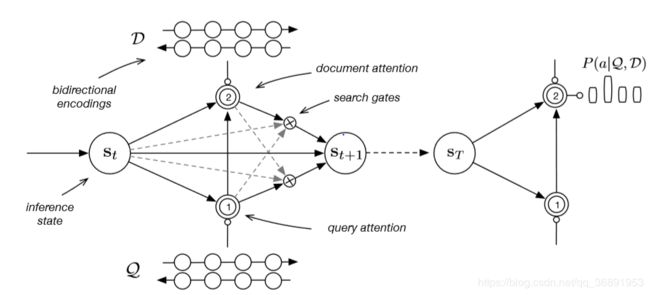
总体相当于一个时序模型,每个时刻都在做一次推理。推理过程是首先计算query各词的attention,计算方式为:
![]()
其中的![]() 是第i个词的隐含层表示,
是第i个词的隐含层表示,![]() 是第t-1此推理得到的状态向量。最终得到的
是第t-1此推理得到的状态向量。最终得到的![]() 就代表第t次推理使用的query表示。然后计算document各词的attention
就代表第t次推理使用的query表示。然后计算document各词的attention
![]()
与query的attention求法类似,只不过再document的attention计算过程中使用了刚才得到的query的表示。最后对推理状态进行更新:![]() 。这里的函数
。这里的函数![]() 就是一个GRU。另外,文章中考虑到了每一次推理时使用的query的表示不同,可能某一时刻产生的query过于宽泛或者document中与query的关联较小,会导致最终document中各词的attention值过于平均,对于这一时刻的推理结果要进行一定程度的弱化。因而设计了两个gate用于衡量:
就是一个GRU。另外,文章中考虑到了每一次推理时使用的query的表示不同,可能某一时刻产生的query过于宽泛或者document中与query的关联较小,会导致最终document中各词的attention值过于平均,对于这一时刻的推理结果要进行一定程度的弱化。因而设计了两个gate用于衡量:
![]()
其中![]() 都是两层的前馈网络,得到的
都是两层的前馈网络,得到的![]() 表示此次推理的
表示此次推理的![]() 的可信度。因而推理状态更新公式修改为
的可信度。因而推理状态更新公式修改为![]() 。用最后一次推理得到的document各词的attention作为得到答案的依据。
。用最后一次推理得到的document各词的attention作为得到答案的依据。