姿态估计与人体动作识别的多任务深度学习模型
最近在做一个人体康复训练的项目,一开始考虑到人体康复训练需要肢体的细微动作,所以先使用人体姿态估计识算法提取骨骼点,再根据人体骨骼点来识别动作(后来发现也不一定这样),并组合成一个端对端的模型,正好找到了最近的一篇论文《2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning》。看完这篇论文来和大家分享一下。
一、背景
方法很少
论文中作者说心在这种端对端的方法很少,“there is no method in the literature that solves both problems”,具体是不是很少也没有去验证,姑且当做很少吧
为什么方法很少
作者现在人体姿态识别的主流方法是使用heat map ,而输出heat map后会使用一个argmax函数进行求骨骼点坐标,这个argmax函数是不可微的,所以不能求导,也就不能联合动作识别来达到端对端。
本文的解决方法
作者使用soft-argmax来代替argmax,而soft-argmax可微,所以解决问题
看到这里,那么heat map方法是什么?为什么它就成了人体姿态估计的主流方法?argmax与soft-argmax又是什么鬼?接下来说一下问题。

图1 姿态识别类型
如上图,人体姿态估计按输出结果的形式可以分成两种,对于前者而言,我们期望得到的是精确的坐标值(x, y);而对于后者而言,我们期望得到对应的热点图谱,用这个热点图谱的响应值来反映人体的不同部位,也就是说,不同部位获得的响应应该是不同的,对于感兴趣的区域(例如头部),需要返回一个较高的响应,而其它部位则响应相对较低。
采用回归的方式来解决人体姿态识别问题,效果并不理想。其主要原因有两方面:一方面是人体运动比较灵活,另一方面,回归模型的可扩展性较差,比较难于扩展到不定量的人体姿态识别问题中。因此,目前大家普遍使用的过渡处理方法是将其看作检测问题,从而获得一张热点图谱。
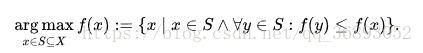
贴上一张找到的argmax函数,这个函数的目的是取出heat map中值最大对应的坐标。这个函数不可微分,不能求导。作者使用的soft-argmax函数改与softmax函数,后面再说到。
网络结构

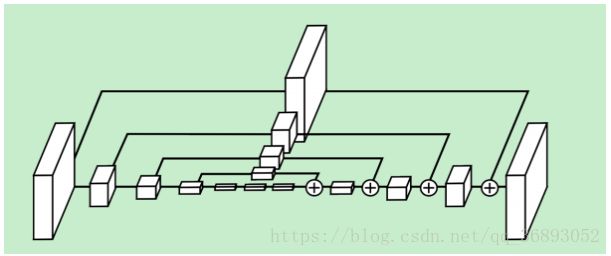
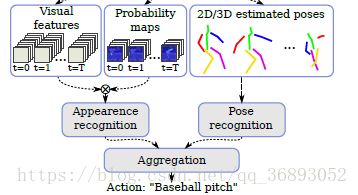
图2 多任务姿态估计与动作识别结构图
从图中可以看到,输入图像(视频)经过一个Multitask CNN后得到Visual feature 、Probability maps、2D/3D estimated poses,将Visual feature 、Probability maps融合,再经过Appearence recongnition 处理,与经过Pose recongition处理的骨骼点进行联合识别动作。
Multitask CNN

entry flow : 原始图像作为输入,经过Inception-V4,输出提取的初步特征Visual feature
Prediction block : 作者根据Hourglass Design设计,最后一层的pk作为骨骼点p,每一个block由8个residual depth-wise卷积,分成三部分组成。每一层还会输出一个probability maps。在动作识别中还会用到上述的两个map,得到appearance features。
贴出Horglass Design的链接,有需要的小伙伴可以去看一下:
[论文阅读理解 - Stacked Hourglass Networks for Human Pose Estimation]https://arxiv.org/pdf/1710.02322.pdf
[Human Pose Regression by Combining Indirect Part Detection and Contextual
Information
]
https://arxiv.org/pdf/1710.02322.pdf
值得注意的是,作者会将Inception-V4提取出来的Visual features 与pk输出的Probability maps提取出来,用到后面的动作识别
动机:捕捉不同尺度下图片所包含的信息. 局部信息,对于比如脸部、手部等等特征很有必要,而最终的姿态估计需要对整体人体一致理解. 不同尺度下,可能包含了很多有用信息,比如人体的方位、肢体的动作、相邻关节点的关系等等.
Soft-argmax layer
在输出heat map后需要接一层Soft-argmax layer目的是将heat map转换为(x,y)坐标值,
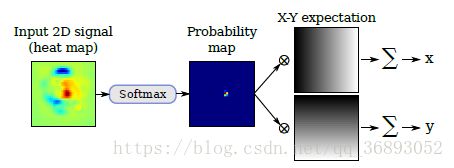

其中 Φ(x)l,c Φ ( x ) l , c 是softmax的输出, cWc c W c 与 lHx l H x 是正则化参数。
3D posestimation
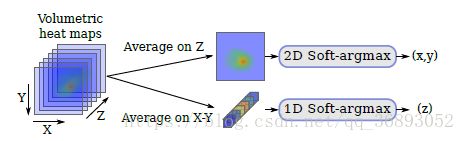
如果是3D的数据,作者使用一个单一的一维Soft-argmax来处理Z轴的数据,最后得出的z轴坐标与x,y一起组合合成三维。
动作识别
作者将提取的骨骼点与底层视觉特征(visual features
)融合,
骨骼点的处理
作者将骨骼点进行一个重新“排布”的规划,时间维度为vertical axis, 骨骼点位horizontal axis,骨骼点的表示为channels
Appearance-based recongnition
作者将Visual feature 与Probability maps 进行了融合

其中输入 Ft∈RWf×Hf×Nf F t ∈ R W f × H f × N f
Mt∈RWf×Hf×NJ M t ∈ R W f × H f × N J ,输出 V∈RT×Nf×Nf V ∈ R T × N f × N f ,Nf为输出特征图的通道数,Nj为骨骼点的个数
作者在这里将两个不同维度的矩阵相乘,使用到了克罗内克积,详细的如下:
[克罗内克积][https://zh.wikipedia.org/wiki/%E5%85%8B%E7%BD%97%E5%86%85%E5%85%8B%E7%A7%AF]
动作识别
得到骨骼点数据与视觉图像后,作者通过一个网络来进行回归运算,具体模型如下:
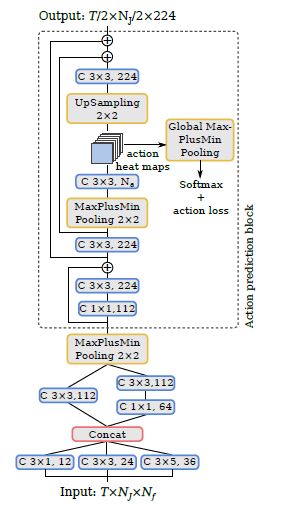
实验
作者做了许多实验,现在就主要的实验进行一下:
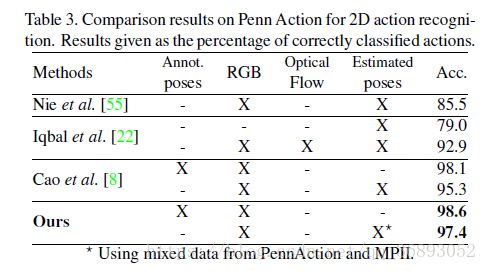
在2D数据上进行的动作识别,使用Penn Action 与MPII数据集,可以看出效果还是很好的,而且作者使用混合数据集也没有损失多少准确度,还增加了鲁棒性

在3D数据集上进行,看出来融合了两个信息效果还是蛮好的。

最后作者还有一个对比,分别使用Pose(骨骼点)、Appearance(视觉信息),Aggregation(混合使用)来对四个动作进行识别,可以看出单独使用骨骼点数据在喝水与打电话两个动作识别上精度不高,因为这两个动作从骨骼点数据上来看是差不多的,但是加上视觉信息,就和方便的得出一个是拿上水杯,一个是手机。