MongoDB主从集群、副本集与分片
在实际生产中,为了防止数据丢失,我们需要搭建主从集群来同步数据;有时候当数据库中的数据量很大的时候,一台服务器无法存储,这时我们需要扩展多台机器来存储我们的数据,这时需要用到MongoDB的分片操作。
转发请标明原文地址:【原文链接】
一、主从复制
对于主从复制的原理,非常简单,简单的说就是几台机器之间进行同步操作,我们在主节点上操作数据,需要同步到其他子节点上。下面我们来实战一下。
首先创建一个cluster文件夹,然后在该文件夹中创建两个子文件夹master和slave分别存放主从节点的数据文件。

下面我们启动两台mongod服务器,主节点端口号为10000,从节点端口号为10001,首先启动主节点:
mongod --dbpath F:\mongodb-win32-x86_64-enterprise-windows-64-2.6.12\cluster\master --port 10000 --master
然后启动从节点,需要指定跟随的主节点地址:
mongod --dbpath F:\mongodb-win32-x86_64-enterprise-windows-64-2.6.12\cluster\slave --port 10001 --slave --source localhost:10000
主从节点启动之后,我们连接主节点,插入数据,会发现主节点同步数据到从节点:
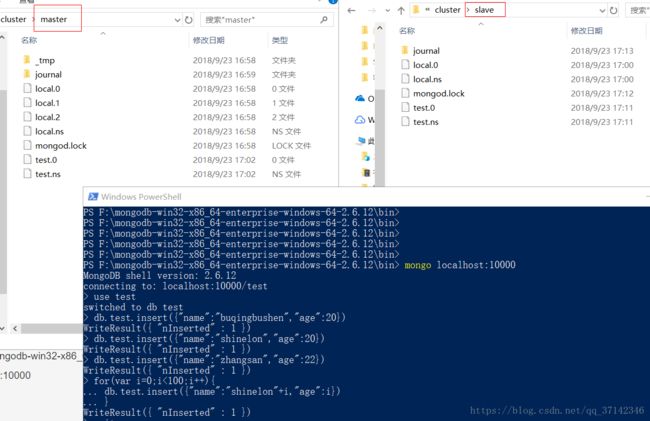
二、副本集
副本集具有自动故障恢复的功能。
主从集群和副本集最大的区别就是副本集没有固定的“主节点”;整个集群会选出一个“主节点”,当其挂掉后,又在剩下的从节点中选中其他节点为“主节点”,副本集总有一个活跃点(primary)和一个或多个备份节点(secondary)。
创建一个cluster文件夹并创建node1,node2,node3三个子文件夹。
三个节点的配置信息如下:
节点1:
HOST:localhost:10001
Data File:D:\mongodb\dbs\node1
节点2:
HOST:localhost:10002
Data File:D:\mongodb\dbs\node2
节点3:
HOST:localhost:10003
Data File:D:\mongodb\dbs\node3
分别使用下面命令启动三个节点:
#replSet参数指定副本集名称,后面初始化需要使用
mongod --dbpath D:\mongodb\dbs\node1 --port 10001 --replSet shinelon
mongod --dbpath D:\mongodb\dbs\node2 --port 10002 --replSet shinelon
mongod --dbpath D:\mongodb\dbs\node3 --port 10003 --replSet shinelon
启动之后会发现打印这样的错误日志:
replSet can't get local.system.replset config from self or any seed (yet)
这时候需要登录到任意一个节点中进行初始化操作:
rs.initiate({"_id":"shinelon","members":[ {"_id":1,"host":"localhost:10001"}, {"_id":2,"host":"localhost:10002"}, {"_id":3,"host":"localhost:10003"} ]})

初始化之后可以使用rs.status命令各个节点的状态,从这里可以看出10001节点为primary,其他两个为secondary。结果如下所示:
> rs.status()
{
"set" : "shinelon",
"date" : ISODate("2018-09-23T10:14:07Z"),
"myState" : 1,
"members" : [
{
"_id" : 1,
"name" : "localhost:10001",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 80,
"optime" : Timestamp(1537697618, 1),
"optimeDate" : ISODate("2018-09-23T10:13:38Z"),
"electionTime" : Timestamp(1537697625, 1),
"electionDate" : ISODate("2018-09-23T10:13:45Z"),
"self" : true
},
{
"_id" : 2,
"name" : "localhost:10002",
"health" : 1,
"state" : 5,
"stateStr" : "STARTUP2",
"uptime" : 29,
"optime" : Timestamp(1537697618, 1),
"optimeDate" : ISODate("2018-09-23T10:13:38Z"),
"lastHeartbeat" : ISODate("2018-09-23T10:14:07Z"),
"lastHeartbeatRecv" : ISODate("2018-09-23T10:14:07Z"),
"pingMs" : 1,
"lastHeartbeatMessage" : "syncing to: localhost:10001",
"syncingTo" : "localhost:10001"
},
{
"_id" : 3,
"name" : "localhost:10003",
"health" : 1,
"state" : 5,
"stateStr" : "STARTUP2",
"uptime" : 29,
"optime" : Timestamp(1537697618, 1),
"optimeDate" : ISODate("2018-09-23T10:13:38Z"),
"lastHeartbeat" : ISODate("2018-09-23T10:14:07Z"),
"lastHeartbeatRecv" : ISODate("2018-09-23T10:14:07Z"),
"pingMs" : 1,
"lastHeartbeatMessage" : "syncing to: localhost:10001",
"syncingTo" : "localhost:10001"
}
],
"ok" : 1
}
此时,手动关闭10001 primary节点,它会自动从其他两台secondary中选出一个primary,结果如下所示:
shinelon:PRIMARY> rs.status()
{
"set" : "shinelon",
"date" : ISODate("2018-09-23T10:28:12Z"),
"myState" : 1,
"members" : [
{
"_id" : 1,
"name" : "localhost:10001",
"health" : 0,
"state" : 8,
"stateStr" : "(not reachable/healthy)",
"uptime" : 0,
"optime" : Timestamp(1537697618, 1),
"optimeDate" : ISODate("2018-09-23T10:13:38Z"),
"lastHeartbeat" : ISODate("2018-09-23T10:28:11Z"),
"lastHeartbeatRecv" : ISODate("2018-09-23T10:27:32Z"),
"pingMs" : 0
},
{
"_id" : 2,
"name" : "localhost:10002",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 907,
"optime" : Timestamp(1537697618, 1),
"optimeDate" : ISODate("2018-09-23T10:13:38Z"),
"electionTime" : Timestamp(1537698455, 1),
"electionDate" : ISODate("2018-09-23T10:27:35Z"),
"self" : true
},
{
"_id" : 3,
"name" : "localhost:10003",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 871,
"optime" : Timestamp(1537697618, 1),
"optimeDate" : ISODate("2018-09-23T10:13:38Z"),
"lastHeartbeat" : ISODate("2018-09-23T10:28:12Z"),
"lastHeartbeatRecv" : ISODate("2018-09-23T10:28:11Z"),
"pingMs" : 1,
"lastHeartbeatMessage" : "syncing to: localhost:10002",
"syncingTo" : "localhost:10002"
}
],
"ok" : 1
}
可以看出,副本集在主节点挂掉之后会自动切换。主节点中可以读写,从节点只能读数据,这点读者可以自行测试。
三、分片
分片(sharding)是指将数据拆分,将其分散存在不同的机器上的过程。有时也用分区(partitioning)来表示这个概念。将数据分散到不同的机器上,不需要功能强大的大型计算机就可以储存更多的数据,处理更多的负载。
MongoDB分片的基本思想就是将集合切分成小块。这些块分散到若干片里面,每个片只负责总数据的一部分。应用程序不必知道哪片对应哪些数据,甚至不需要知道数据已经被拆分了,所以在分片之前要运行一个路由进程,该进程名为mongos。这个路由器知道所有数据的存放位置,所以应用可以连接它来正常发送请求。对应用来说,它仅知道连接了一个普通的mongod。路由器知道数据和片的对应关系,能够转发请求道正确的片上。如果请求有了回应,路由器将其收集起来回送给应用。
设置分片时,需要从集合里面选一个键,用该键的值作为数据拆分的依据。这个键称为片键(shard key)。
用个例子来说明这个过程:假设有个文档集合表示的是people。如果选择名字(“name”)作为片键,第一片可能会存放名字以A-F开头的文档,第二片存的G-P的名字,第三片存的Q~Z的名字。随着添加或者删除片,MongoDB会重新平衡数据,使每片的流量都比较均衡,数据量也在合理范围内。
分片的架构图如下,这里用两台服务器来进行分片操作:
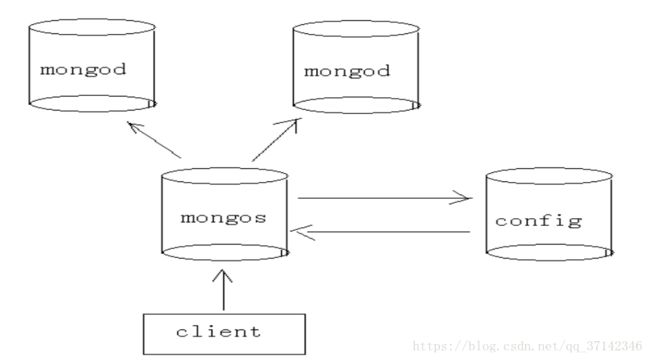
分片配置如下:
configNode localhost:2222
mongosNode localhost:3333
mongodNode localhost:4444
mongodNode localhost:5555
使用如下命令启动服务器,注意启动顺序:
#1.启动config服务器
mongod --dbpath F:\sharding\config_node --port 2222
#2.启动mongos路由
mongos --port 3333 --configdb=localhost:2222
#3.启动其他两个节点
mongod --dbpath F:\sharding\mongod_node1 --port 4444
mongod --dbpath F:\sharding\mongod_node2 --port 5555
启动之后需要连接mongos路由将其他两个节点与路由器连接起来。
mongo localhost:3333
![]()
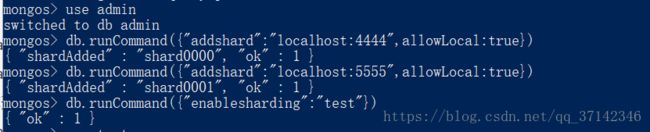
向mongos路由中添加分片:
db.runCommand({"addshard":"loclahost:4444",allowLocal:true})
db.runCommand({"addshard":"loclahost:5555",allowLocal:true})
#为test数据库开启分片服务
db.runCommand({"enablesharding":"test"})
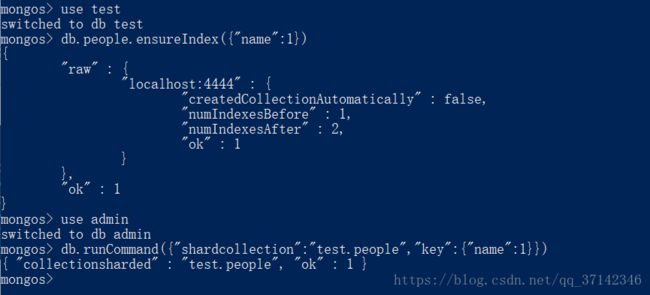
指定片键,这里指定为people.name键:
db.runCommand({"shardcollection":"test.people","key":{"name":1}})
不过需要为片键指定的键创建索引,否则不能指定片键:
此时我们向test数据库的people集合中插入10万条数据。
可以使用db.printShardingStatus()命令查看每一个分片分到的数据情况,而且数据量越大,每个分片的数据越平衡。
至此,本篇文章介绍完了MongoDB的主从复制,副本集和分片操作,感兴趣的读者可以自己操作实验。