浅谈分布式唯一ID生成策略
背景
场景:
一个电商系统的订单业务,在高并发场景下,大量的用户同时访问,那么如何保证ID订单号的唯一性呢?
首先我们明确需求,分析一下什么是分布式ID?
- 全局唯一,区别于单点系统的唯一,全局是要求分布式系统内唯一。
- 有序性,通常都需要保证生成的 ID 是有序递增的。例如,在数据库存储等场景中,有序 ID
便于确定数据位置,往往更加高效。
从上面的场景中我们不由想到线程安全的问题,很多人想到使用锁。
这是一种最常见的解决方式,在单点的环境下,我们可以使用java自带的锁来保证唯一性;在分布式环境下我们需要使用分布式锁,借助第三方工具来实现,比如Redis和Zookeeper。
实现分布式锁比较复杂,也有简单的解决方案,比如数据库的ID字段,利用它天然自增的特性保证,不过这种情况也有局限性,比如分库分表的情况下比较复杂。除此之外,我们也可以使用UUID来生成全局唯一的ID,这种方式实现简单。
另外基于 Twitter 早期开源的Snowflake的实现,以及相关改动方案。这是目前应用相对比较广
泛的一种方式。
在国内,有很多大厂也实现了自己的ID分成策略,比如微信的seqsvr,百度基于Snowflake算法使用java实现的UidGenerator,还有美团等等大厂。
实现
一、数据库ID
我们可以利用数据库自增字段来实现全局唯一ID,这种方式是实现简单,不需要额外的开发方案;但是在分库分表的情况下,实现比较复杂。
在这里我们讨论一下在分库分表的情况下,如何保证唯一ID。
在分库分表的情况下,在每一张分表中保存一个最小ID来保证单表自增,但是我们还需要维护一张路由表。用于将请求发送给对应的分表。
在这里,有两大缺点:
- 路由表的设计比较复杂,需要保证低延迟。
- 路由表的存储,如果数据量特别大,那么路由表也会占用大量的空间。
可见,这种方式需要设计合适的路由表,处理不同的ID请求发送到不同的分表中处理,需要保证访问的时间效率,而且在数据量过大的情况可能单个路由表就占用大量的空间,查找需要耗费大量的时间,如果针对路由表再进行路由,那么有可能随着数据量的增大陷入一个递归的状态。
二、使用java的AtomicInteger和Lock,这种方式适用于单点系统。
1.AtomicInteger方式
//订单服务
public class AtomicorderServiceImpl implements OrderService{
//使用CAS方式
AtomicInteger num=new AtomicInteger(0);
public String OrderId() throws Exception {
SimpleDateFormat dateFormat=new SimpleDateFormat("YYYYmmDDHHMMss");
return dateFormat.format(new Date())+"_"+num.addAndGet(1);
}
public String getOrderId() throws Exception {
return OrderId();
}
}
2.Lock方式
//订单服务
public class LockorderServiceImpl implements OrderService{
Lock lock;
public LockorderServiceImpl(Lock lock) {
this.lock=lock;
}
int num;
public String OrderId(){
SimpleDateFormat dateFormat=new SimpleDateFormat("YYYYmmDDHHMMss");
return dateFormat.format(new Date())+"_"+num++;
}
//使用显示锁
public String getOrderId() {
lock.lock();
String id=OrderId();
lock.unlock();
return id;
}
}
三、分布式锁
1.使用Redis:
//订单服务
public class RedisorderServiceImpl implements OrderService{
JedisPool pool;
public RedisorderServiceImpl(JedisPool pool) {
this.pool=pool;
}
public String getOrderId() throws Exception {
return OrderId();
}
//使用redis实现分布式锁
public String OrderId() throws Exception {
SimpleDateFormat dateFormat=new SimpleDateFormat("YYYYmmDDHHMMss");
return dateFormat.format(new Date())+"_"+pool.getResource().incr("orderId");
}
}
运行结果如下:
20194986170340_1
20194986170340_7
20194986170340_5
20194986170340_2
20194986170340_4
20194986170340_6
20194986170340_3
20194986170340_10
20194986170340_9
20194986170340_8
redis如下:

2.使用Zookeeper实现分布式锁:
//订单服务
public class ZkorderServiceImpl implements OrderService{
CuratorFramework client;
public ZkorderServiceImpl(CuratorFramework client){
this.client=client;
}
int num;
public String OrderId(){
SimpleDateFormat dateFormat=new SimpleDateFormat("YYYYmmDDHHMMss");
return dateFormat.format(new Date())+"_"+num++;
}
/**
* 使用ZK分布式锁
* @param client
* @return
* @throws Exception
*/
public String getOrderId() throws Exception {
InterProcessMutex mutex=new InterProcessMutex(client, "/OrderId");
mutex.acquire();
String id=OrderId();
mutex.release();
return id;
}
}
运行结果如下:
20195386170300_0
20195386170303_1
20195386170303_2
20195386170304_3
20195386170304_4
20195386170304_5
20195386170304_6
20195386170304_7
20195386170304_8
20195386170304_9
主线程如下,这里使用线程池启动了10个线程来模拟多线程并发访问:
public class MutilThreadGetId {
static CuratorFramework client;
static JedisPool pool;
static {
client=CuratorFrameworkFactory
.builder()
.connectString("192.168.217.111:2181")
.sessionTimeoutMs(5000)
.retryPolicy(new ExponentialBackoffRetry(5000, 10000))
.build();
client.start();
JedisPoolConfig config=new JedisPoolConfig();
config.setMaxTotal(10);
pool=new JedisPool(config,"127.0.0.1",6379,5000);
}
static OrderService orderService;
public static void main(String[] args) {
ExecutorService service=Executors.newCachedThreadPool();
final CountDownLatch latch=new CountDownLatch(1);
orderService=new AtomicorderServiceImpl();
orderService=new LockorderServiceImpl(new ReentrantLock());
orderService=new ZkorderServiceImpl(client);
orderService=new RedisorderServiceImpl(pool);
for(int i=0;i<10;i++) {
//提交订单任务
service.submit(new OrderServiceTask(orderService, latch));
}
latch.countDown();
service.shutdown();
}
}
四、MongoDB对象ID
mongodb设计的初衷是用作分布式数据库,在mongodb的文档中必须有一个"_id"键,这个键的值可以是任何类型的,默认是个ObjectId。如果插入的文档没有“_id”键,那么系统会自动帮我们创建一个,由服务器自动创建。
ObjectId使用12字节的存储空间,是一个由24个十六进制数字组成的字符串(每两个字节 可以存储两个十六进制数字)。ObjectId的12个字节按照如下的方式生成:

五、Snowflake算法
基于 Twitter 早期开源的Snowflake的实现,以及相关改动方案。这是目前应用相对比较广
泛的一种方式,其结构定义如下图所示:

- 整体长度通常是 64 (1 + 41 + 10+ 12 = 64)位,适合使用 Java 语言中的 long 类型来存
储。 - 头部是 1 位的正负标识位。
- 紧跟着的高位部分包含 41 位时间戳,通常使用 System.currentTimeMillis()。
- 后面是 10 位的 WorkerID,标准定义是 5 位数据中心 + 5 位机器 ID,组成了机器编号,以区
分不同的集群节点。 - 最后的 12 位就是单位毫秒内可生成的序列号数目的理论极限。
Snowflake 的官方版本是基于 Scala 语言,Java 等其他语言的参考实现有很多。
scala版本的可以参考 :https://github.com/twitter-archive/snowflake
java版本的可以参考:https://github.com/relops/snowflake
在国内比如百度基于该算法实现的UidGenerator。
UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
详情参考:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
美团公开的数据库方案Leaf-Segment:https://tech.meituan.com/2017/04/21/mt-leaf.html
六、微信分布式ID号生成器seqsvr
微信服务器端为每一份需要与客户端同步的数据(例如消息)都会赋予一个唯一的、递增的序列号(后文称为sequence),作为这份数据的版本号。在客户端与服务器端同步的时候,客户端会带上已经同步下去数据的最大版本号,后台会根据客户端最大版本号与服务器端的最大版本号,计算出需要同步的增量数据,返回给客户端。这样不仅保证了客户端与服务器端的数据同步的可靠性,同时也大幅减少了同步时的冗余数据。
其架构图如下:
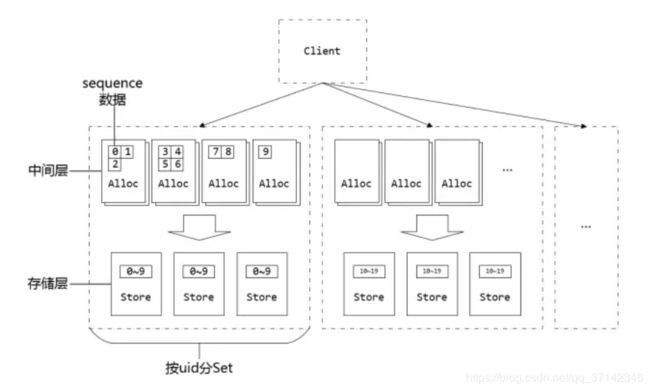
详情请参考:万亿级调用系统:微信序列号生成器架构设计及演变
对于分布式ID的生成策略本篇文章就介绍到这里。文章中涉及的代码地址如下:
https://github.com/ljcan/DistributeID_Generator