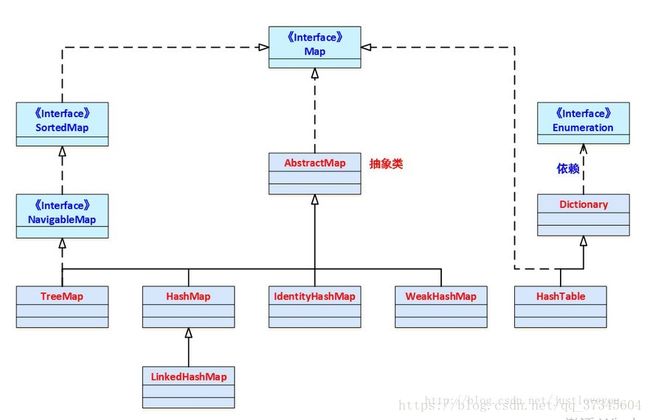
map详解
map是什么?
b.键唯一
c.键对应的值唯一
map的分类
EnumMap
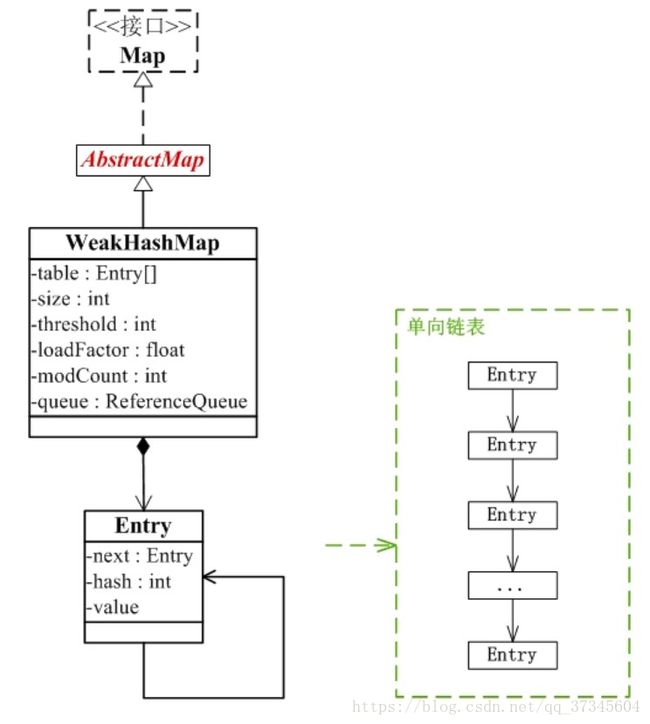
WeakHashMap
IdentityHashMap
HashMap
Dictionary
HashTable
SortedMap
NavigableMap


TreeMap
LinkedHashMap
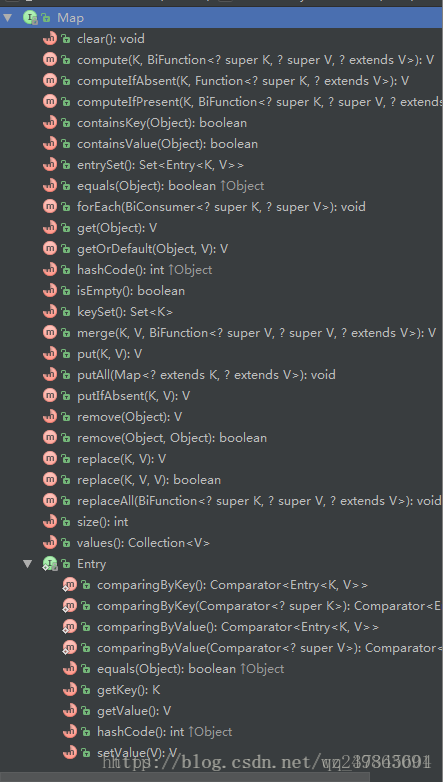
map的遍历
Map map = new HashMap();
for (Integer in : map.keySet()) {
//map.keySet()返回的是所有key的值
String str = map.get(in);//得到每个key多对用value的值
System.out.println(in + " " + str);
} Iterator> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
} for (Map.Entry entry : map.entrySet()) {
//Map.entry 映射项(键-值对) 有几个方法:用上面的名字entry
//entry.getKey() ;entry.getValue(); entry.setValue();
//map.entrySet() 返回此映射中包含的映射关系的 Set视图。
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
} for (String v : map.values()) {
System.out.println("value= " + v);
}HsahMap的底层原理
存储:
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
} void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取指定 bucketIndex 索引处的 Entry
Entry e = table[bucketIndex];
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry(hash, key, value, e);
// 如果 Map 中的 key-value 对的数量超过了极限
if (size++ >= threshold)
// 把 table 对象的长度扩充到原来的2倍。
resize(2 * table.length);
} 当系统决定存储HashMap中的key-value对时,完全没有考虑Entry中的value,仅仅只是根据key来计算并决定每个Entry的存储位置。我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可。
hash(int h)方法根据key的hashCode重新计算一次散列。此算法加入了高位计算,防止低位不变,高位变化时,造成的hash冲突。
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}我们可以看到在HashMap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。前面说过HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的 元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表,这样就大大优化了查询的效率。
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 hash 码值总是相同的。我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,在HashMap中是这样做的:调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:
static int indexFor(int h, int length) {
return h & (length-1);
}这个方法非常巧妙,它通过 h & (table.length -1) 来得到该对象的保存位,而HashMap底层数组的长度总是 2 的 n 次方,这是HashMap在速度上的优化。在 HashMap 构造器中有如下代码:
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;这段代码保证初始化时HashMap的容量总是2的n次方,即底层数组的长度总是为2的n次方。
读取:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
} 有了上面存储时的hash算法作为基础,理解起来这段代码就很容易了。从上面的源代码中可以看出:从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
总结
区别详解:点击打开链接