JAVA1.8新特性Stream流
今天我们来学习一下Java 8 的新特新—>Stream流;
Stream流
stream流是Java8的新特性,它也是有关于集合的新api;
Stream 作为 Java 8 的一大亮点,它与 java.io 包里的 InputStream 和 OutputStream 是完全不同的概念。Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作,或者大批量数据操作;
Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性;
下面我们用一个例子来引入Stream流的操作:
Stream流的数据操作特性
这里有一个集合
List list = Arrays.asList(1,2,3,4,5);
我们要写一个方法找偶数,返回一个新的list包含结果;
用我们以前的方法做的话就会比较繁琐:
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4,5);
System.out.println(exec(list, new Predicate<Integer>(){
@Override
public boolean test(Integer i) {
return i % 2 == 0;
}
}));
//System.out.println(exec(list, i -> i % 2 == 0));
}
// 设计模式中,策略模式
public static List<Integer> exec(List<Integer> list, Predicate<Integer> predicate) {
List<Integer> list2 = new ArrayList<>();
for(Integer i :list) {
if(predicate.test(i)) {
list2.add(i);
}
}
return list2;
}
在这里我们使用了设计模式中的策略模式,将它的处理方法拿出来,可以对它的使用方法进行主动的编写,同时我们用了一个新的模式Predicate,这个模式叫做断言模式,顾名思义就是对我们要进行的处理进行断言操作,断定它能进行的功能;比如上面的例子就是我们求出了list集合中所有的偶数,那我们如果不想对他进行求偶操作呢?比如我们想求出集合中所有大于三的数据呢?
这个时候我们就可以改变这个断言,重新写入想要的操作;
System.out.println(exec(list, new Predicate<Integer>(){
@Override
public boolean test(Integer i) {
return i >3;
}
在不用断言模式的时候,我们甚至需要新写一个方法,然后调用它,有了断言模式,我们就可以主动的给exec这个方法传入我们想要的策略;
甚至我们可以对断言进行简写;即lambda表达式;
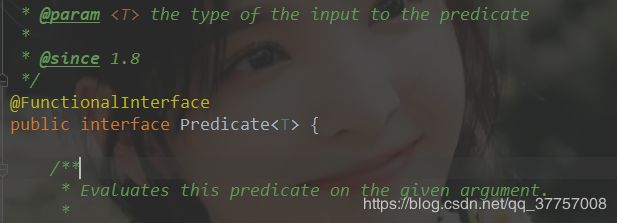
这里我们可以看到这个接口是一个函数式接口,就是单方法接口;所以我们完全可以用lambda表达式给他写入断言;
System.out.println(exec(list,i -> i % 2 == 0);
System.out.println(exec(list,i -> i > 3);
用了lambda表达式就大大减少了我们的代码量;
可是这也是比较麻烦的 ;而且在之前我们遍历集合的时候就需要循环,或者 Iterator 迭代器来遍历;这也都是很浪费时间和空间的;
那有没有一种方法,是我们不用调用方法,直接用语句来获得所有的偶数呢?这个时候我们就需要用到jdk1.8的新特性,Stream流,将数组元素变为一条数据流,然后对这个数据流进行操作,过滤或者收集想要的数据;
- 特点:
-
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
-
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
-
Stream 的数据源本身可以是无限的。
Stream()类的方法
- filter (过滤器)
这个过滤器的方法就是对流中的数据一个一个的进行筛选,看看它是不是符合规则,如果不符合就拦截住,也就是舍弃,如果符合要求,则让他通过,进行下一步的操作,说白了就像一个滤网一样,我们可以设置过滤的规则,然后它对数据流进行筛选;
比如上面的例子来说我们就可以用这样的方法;
List<Integer> list = Arrays.asList(1,2,3,4,5,6);
List<Integer> stream = list.stream().filter( i ->
i%2 == 0).collect(Collectors.toList());
System.out.print(stream);
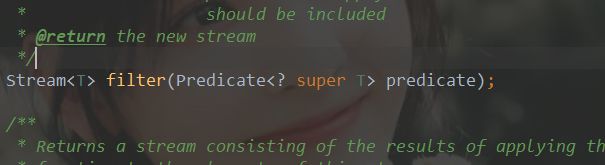
我们可以看到filter的参数就是一个Predicae<>断言;也就是说我们可以给它里面传一个lambda表达式,就是过滤的规则; 同时它返回的又是一个Stream流对象,这时我们又可以用它的collect(收集器),对过滤下来的数据收集起来,把他存入一个List集合;然后这时候我们输出得到的这个集合,就是我们收集的数据;
- map (映射)
映射的, lambda把原有的元素转换为另一个元素, 不会改变个数;
上面的filter过滤器就是给把我们的数据按我们的规则筛选出来,那map()方法就是将我们的元素按照规则映射成另外的元素;比如我们要得到上面的list集合中的所有元素的2倍的集合,这时候我们就需要用到map()方法;
List<Integer> list4 = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> collect = list4.stream().map(i ->
i * 2).collect(Collectors.toList());
System.out.println(collect);
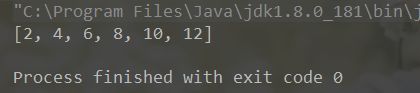
这只是简单的映射,我们又得到了需要的数据,同时原集合仍然存在;我们再看看map()方法的参数;


这里我们需要一个Function()参数,这个模式的方法lambda表达式的写法就是一个参数,返回一个结果;
map(i -> i * 2)
这句映射就很直观的帮我们解释了Function接口的特性;
- == flatMap(扁平化映射)==
这个类就好比是流的类型转换;
比如我们现在定义了一个list集合,它的元素是字符串数组;
List<String[]> list = new ArrayList<>();
list.add(new String[]{"张三", "李四"});
list.add(new String[]{"王五", "张三"});
list.add(new String[]{"钱七", "周八"});
如果我们想将它里面的每个字符串提取出来,组成一个新的集合,按照原来的方法我们就需要两重遍历,先遍历集合,后遍历数组,得到每一个字符串元素,再新建一个集合,将它们存进去;
List<String> list2 = new ArrayList<>();
for (String[] strings : list) {
for (String string : strings) {
list2.add(string);
}
}
System.out.println(list2);
可如果用flatmap方法做扁平化映射时就特别简单,我们一句话就可以得到这个集合;
List<String> list3 = list.stream().flatMap( s ->
Arrays.stream(s)).collect(Collectors.toList());
flatmap的参数同样是一个Function,只是这次我们传入的参数是list集合的元素String[]数组,把它映射成一个数组流Arrays.stream,然后collect收集起来;这个方法就很方便;
它就可以用在我们平时大规模数据转换的时候,用流的方式,得到需要的格式;
- forEach
遍历流,接收一个Consumer
list3.stream().forEach( (a) -> {
System.out.println(a);
} );
- map的流遍历
接收一个BiConsumer
Map<String, String> map = new HashMap<>();
map.put("a", "张");
map.put("b", "李");
map.forEach( (key, value) -> {
System.out.println("key:" +key + " value:" + value);
} );
重要模式
上面说了很多种的模式,再这里我们统一进行一下说明;
-
Predicate 断言接口
对应的lambda 一个参数,返回结果是boolean
(a) -> { return true|false; } -
BiPredicate 双参数断言
对应的lambda 两个参数,返回结果是boolean
(a, b) -> { return true|false; } -
Function 函数接口
对应的lambda 一个参数,一个返回结果,参数和返回结果的类型可以不一样 -
BiFunction 双参数函数接口
两个参数,一个结果
(a, b) -> { 根据ab返回一个结果} -
Consumer 消费接口
一个参数 没有结果
(a) -> { 不需要return } -
BiConsumer 双参数消费接口
两个参数,没有结果
(a,b) -> { 不需要return } -
Supplier 生产者接口
没有参数,返回一个结果
() -> {return 结果}
有了这些模式知识的帮忙我们就可以更好的理解Stream()中方法的参数需求了;
7. 其它常见api
求个数count()
System.out.println(list3.stream().count());
去除重复distinct()
System.out.println(list3.stream().distinct().collect(toList()));
获取最大最小值(参数需要一个比较器)
// 返回的是Optional 类型,怕集合为空时,没有合法的最大值
List<String> list4 = Arrays.asList("zhang", "li", "zhao", "wang");
System.out.println(list4.stream().max((a, b) -> a.compareTo(b)));
System.out.println(list4.stream().min((a, b) -> a.compareTo(b)));
如果是数字流,除了最大最小值外,还有平均值,和
System.out.println(IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).max());
System.out.println(IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).min());
System.out.println(IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).average());
System.out.println(IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).sum());
有了上面的知识我们来做一个比较复杂的需求:
我们定义了一个学生类,它的属性包括名字,性别,所在城市;
public class Student {
private String name;
private String sex;
private String city;
public Student(String name, String sex, String city) {
this.name = name;
this.sex = sex;
this.city = city;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", city='" + city + '\'' +
'}';
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
}
然后我们定义一个集合存放学生类的对象
List<Student> students = Arrays.asList(
new Student("zhang", "男", "西安"),
new Student("li", "男", "西安"),
new Student("wang", "女", "北京"),
new Student("zhao", "女", "上海"),
new Student("zhou", "男", "北京")
);
这时我们如果想要按照性别进行分组存储呢?(男生存在一起,女生存在一起)
按照我们本来的方法需要定义map数组,按照键值对形式,将性别和对象形成映射,然后存储起来;
具体代码:
Map<String, List<Student>> map2 = new HashMap<>();
for (Student student : students) {
if (student.getSex().equals("男")) {
List<Student> nan = map2.get("男");
if (nan == null) {
nan = new ArrayList<>();
map2.put("男", nan);
}
nan.add(student);
} else {
List<Student> nv = map2.get("女");
if (nv == null) {
nv = new ArrayList<>();
map2.put("女", nv);
}
nv.add(student);
}
}
System.out.println(map2);
我们发现上面的逻辑很复杂,我们也很容易出错,同时这只是我们按照性别分组,那如果类别特别多的话,比如我们按照所在城市分组呢?难道我们每一个都要进行判断吗?显然这是不现实的,这时我们就必须用Stream流来实现了:
//按照性别分组
Map<String, List<Student>> map3 = students.stream().collect(
Collectors.groupingBy( s -> s.getSex() ));
System.out.println(map3);
这里我们用了groupingBy方法,传入的参数是一个Function,分组的标准就是我们function的返回属性;
//按照所在城市分组
Map<String, List<Student>> map4 = students.stream().collect(
Collectors.groupingBy( s -> s.getCity()));
System.out.println(map4);
答案:
{
女=[Student{name=‘wang’, sex=‘女’, city=‘北京’}, Student{name=‘zhao’, sex=‘女’, city=‘上海’}],
男=[Student{name=‘zhang’, sex=‘男’, city=‘西安’}, Student{name=‘li’, sex=‘男’, city=‘西安’}, Student{name=‘zhou’, sex=‘男’, city=‘北京’}]
}
{
上海=[Student{name=‘zhao’, sex=‘女’, city=‘上海’}],
西安=[Student{name=‘zhang’, sex=‘男’, city=‘西安’}, Student{name=‘li’, sex=‘男’, city=‘西安’}],
北京=[Student{name=‘wang’, sex=‘女’, city=‘北京’}, Student{name=‘zhou’, sex=‘男’, city=‘北京’}]
}