目前一些目标检测论文中所提到的一些模型的作用
FPN(Feature Pyramid Network)算法:
特征金字塔网络(FPN)是目标检测中生成金字塔形状特征表示的代表性模型架构之一。它采用通常为图像分类设计的骨干模型,然后通过自上而下和横向连接,并组合不同的特征层来构建特征金字塔。FPN 取代了检测器(如 Faster R-CNN)中的特征提取器,并生成更高质量的金字塔特征图【1】。
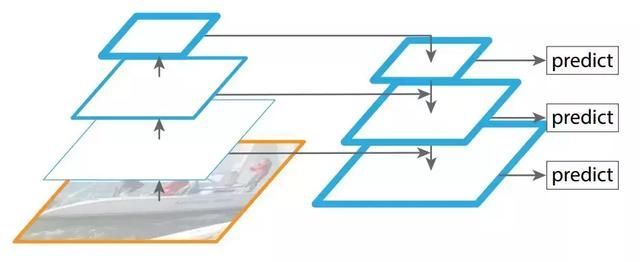
图注:特征金字塔网络,选自 arXiv: 1612.03144。
FPN 由自下而上和自上而下路径组成。其中自下而上的路径采用下采样,是用于提取特征的常用卷积网络,空间分辨率自下而上地下降。当空间分辨率下降,且检测到更高层的结构时,每层的语义值增加。
原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的【2】。
同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
【1】谷歌大脑提出NAS-FPN:一种学会自动架构搜索的特征金字塔网络:http://www.360kuai.com/pc/9f5779082a933626a?cota=4&sign=360_57c3bbd1&refer_scene=so_1
【2】FPN(feature pyramid networks)算法讲解:https://blog.csdn.net/u014380165/article/details/72890275
【3】FPN(特征图金字塔网络)理论基础与具体实现:https://blog.csdn.net/qq_17550379/article/details/80375874
RetinaNet:
paper:Focal Loss for Dense Object Detection
link:RetinaNet
该方法是一种对one stage系的改进。众所周知,detector主要分为以下两大门派:

这种鱼(speed)与熊掌(accuracy)不可兼得的局面一直成为Detection的瓶颈。
目前精度最高的目标检测器都是基于R-CNN结构衍生出来的two-stage目标检测方法,相反one-stage的探测器应用于目标可能位置的密集采样中,具有更快更简单的特点但是精度落后two-stage的检测器【2】;
究其原因,就是因为one-stage的密集检测器在训练过程中会遇到foreground和background受制于万恶的 “类别不平衡”的问题【1】 。
1、什么是“类别不平衡”呢?
详细来说,检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的bbox属于background。
2、“类别不平衡”又如何会导致检测精度低呢?
因为bbox数量爆炸。
正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。
3、那为什么two-stage系就可以避免这个问题呢?
因为two-stage系有RPN罩着。
第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最初生成的anchor那样夸张了。就等于是 从 “类别 极 不平衡” 变成了 “类别 较 不平衡” 。
不过,其实two-stage系的detector也不能完全避免这个问题,只能说是在很大程度上减轻了“类别不平衡”对检测精度所造成的影响。
接着到了第二个stage时,分类器登场,在初筛过后的bbox上进行难度小得多的第二波分类(这次是细分类)。这样一来,分类器得到了较好的训练,最终的检测精度自然就高啦。但是经过这么两个stage一倒腾,操作复杂,检测速度就被严重拖慢了。
4、那为什么one-stage系无法避免该问题呢?
因为one stage系的detector直接在首波生成的“类别极不平衡”的bbox中就进行难度极大的细分类,意图直接输出bbox和标签(分类结果)。而原有交叉熵损失(CE)作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
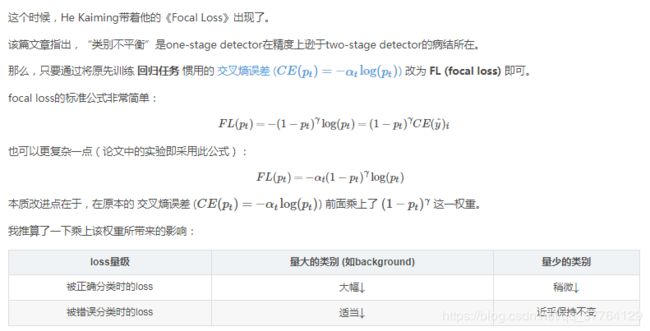
也就是说,一旦乘上了该权重,量大的类别所贡献的loss被大幅砍削,量少的类别所贡献的loss几乎没有多少降低。虽然整体的loss总量减少了,但是训练过程中量少的类别拥有了更大的话语权,更加被model所关心了。
为此,FAIR还专门写了一个简单的one-stage detector来验证focal loss的强大。并将该网络结构起名RetinaNet: 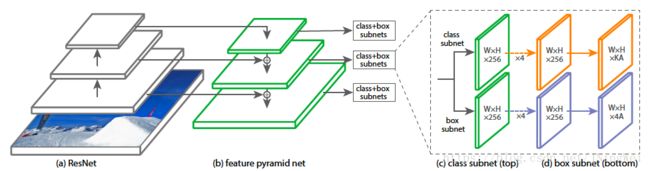
文章的两大贡献:

【1】论文阅读: RetinaNet:https://blog.csdn.net/JNingWei/article/details/80038594
【2】RetinaNet论文理解:https://blog.csdn.net/wwwhp/article/details/83317738
NAS(网络架构搜索):
机器学习算法的效果好坏不仅取决于参数,而且很大程度上取决于各种超参数。有些paper的结果很难重现原因之一就是获得最优超参值往往需要花很大的力气。超参数的自动搜索优化是一个古老的话题了。深度学习兴起前它主要针对传统机器学习算法中的模型超参数,比较经典的方法有随机搜索(Random search), 网格搜索(Grid search),贝叶斯优化(Bayesian optimization),强化学习(Reinforcement learning), 进化算法(Evolutionary Algorithm)等,统称为Hyperparameter optimization(HO)。像Auto-sklearn和Auto-WEKA都是比较有名的HO框架。对于深度学习说,超参数主要可为两类:一类是训练参数(如learning rate,batch size,weight decay等);另一类是定义网络结构的参数(比如有几层,每层是啥算子,卷积中的filter size等),它具有维度高,离散且相互依赖等特点。前者的自动调优仍是HO的范畴,而后者的自动调优一般称为网络架构搜索(Neural Architecture Search,NAS)。这些年来大热的深度神经网络,虽然将以前很另人头疼的特征提取自动化了,但网络结构的设计很大程度上还是需要人肉,且依赖经验。每年各AI顶会上一大批论文就是在提出各种新的更优的网络子结构。一个自然的诉求就是这个工作能否交给机器来做。
网络架构搜索主要包括以下三个方面:
- 搜索空间:定义了优化问题的变量,网络结构和超参数的变量定义有所不同,不同的变量规模对于算法的难度来说也不尽相同。
- 搜索策略:搜索策略定义了使用怎样的算法可以快速、准确找到最优的网络结构参数配置。常见的搜索方法包括:随机搜索、贝叶斯优化、进化算法、强化学习、基于梯度的算法。其中,2017 年谷歌大脑的那篇强化学习搜索方法将这一研究带成了研究热点,后来 Uber、Sentient、OpenAI、Deepmind 等公司和研究机构用进化算法对这一问题进行了研究,这个 task 算是进化算法一大热点应用。
- 评价预估:类似于工程优化中的代理模型(surrogate model),因为深度学习模型的效果非常依赖于训练数据的规模,大规模数据上的模型训练会非常耗时,对优化结果的评价将会非常耗时,所以需要一些手段去做近似的评估
具体描述见:神经网络架构搜索(NAS)综述
《Neural Architecture Search with Reinforcement Learning》(神经结构搜索与强化学习)
网站链接(开源代码):https://github.com/tensorflow/models此篇论文中的核心是:利用Reinforcement Learning(强化学习)机制训练一个RNN(循环神经网路)controller(控制器)去自动产生一个神经网络,无需人为手动设计网络,设计出的网络在相关有权威的数据集上都取得了很好的成绩。看完论文后发现没有硬件资源根本是无法使得训练跑起来的,有钱就是任性,论文用了800个GPU跑起来的。
摘自:网络结构搜索(1)—— NAS(Neural architecture search with reinforcement learning)论文笔记
本质上网络架构搜索,和围棋类似,是个高维空间的最优参数搜索问题。既然围棋上AlphaGo可以战胜人类,那在网络架构搜索上机器最后也很有可能可以取代人类。我们知道,AlphaGo主要是基于强化学习。2016年,MIT和Google的学者们差不多在同一时间发表论文,将强化学习引入到深度神经网络结构的搜索中,取得了不俗的成果。在几个小型的经典数据集上击败同时代同级别的手工设计网络。但这个方法有个缺点是消耗计算资源巨大,基本就不是一般人玩得起的。这个坑也是后面一大波工作改进的重点。比如下面的这种方法:
进阶篇:《Learning Transferable Architectures for Scalable Image Recognition》提出NASNet
源码链接:https://github.com/tensorflow/models/tree/master/research/slim/nets/nasnet
它假设整体网络是由cell重复构建的,那搜索空间就缩小到对两类cell(normal cell和reduction cell)结构的搜索上,从而大大减小了搜索空间。在CIFAR数据集上达到了比同期SOTA网络更高的精度,同时这样的分解也有助于知识的迁移,学习到的cell结构可以帮助在更大的图片分类数据集以及在物体检测数据集上得到SOTA的结果。注意在这个方法中,虽然cell结构是学习得到的,但如何重复和组合这些cell的元网络结构是预定义的。更拓展地,CMU和Google发表的论文《Hierarchical Representations for Efficient Architecture Search》中定义了一种层次化的网络结构:最底层为像卷积和池化等基本组件;中间层为这些组件所构成的图;最高层就是由这些图层叠而成的整体网络。
摘自:神经网络架构搜索(Neural Architecture Search)杂谈:https://blog.csdn.net/jinzhuojun/article/details/84698471
NAS-FPN:(Neural architecture search-Feature Pyramid Network)
设计特征金字塔架构的挑战在于其巨大的设计空间。组合不同尺度的可能连接数量随着网络层数的增加呈指数级增长。本文算法的目标是为 RetinaNet 框架发现更好的 特征金字塔网络(FPN) 架构。
本文的主要贡献是设计搜索空间,覆盖所有可能的跨尺度连接,已生成多尺度特征表示。在搜索过程中,研究者的目标是发现具有相同输入和输出特征级别并且可以被重复应用的微粒架构。模块化搜索空间使得搜索金字塔架构变得易于管理。模块化金字塔架构的另一个好处是可以随时检测目标(即「early exit」),虽然这种「early exit」方法已经被尝试过,但手动设计这种架构依旧相当困难【1】。
研究者构建的架构,即 NAS-FPN,在构建目标检测架构方面具有很大的灵活性。NAS-FPN 与各种骨干模型配合得很好,如 MobileNet、ResNet、AmoebaNet。它为移动端模型和高准确率模型在速度和准确率方面提供了更好的权衡。
在相同的推理时间下,与 RetinaNet 框架中的 MobileNetV2 骨干模型相结合,它的性能超过当前最佳的移动检测模型(与 MobilenetV2 结合的 SSDLite)2 个 AP。与强大的 AmoebaNet-D 骨干模型结合,NAS-FPN 在单个测试规模中达到了 48.3 的 AP 单模型准确率。其检测准确率超过了 Mask RCNN,同时使用的推理时间更少。几种模型的具体结果如图 1 所示。

图 1:移动设备上准确型模型(上)和快速型模型(下)的平均精度与推断时间关系。绿色折线是 NASFPN 与 RetinaNet 相结合的结果。详情请看图 9。
本文中的方法基于 RetinaNet 框架 [23],因为该框架简单、高效。RetinaNet 框架有两个主要的组成部分:一个骨架网络(通常是当前最优的图像分类网络)和一个特征金字塔网络(FPN)。本文算法的目标是为 RetinaNet 框架发现更好的 FPN 架构。图 2 所示为 RetinaNet 架构。
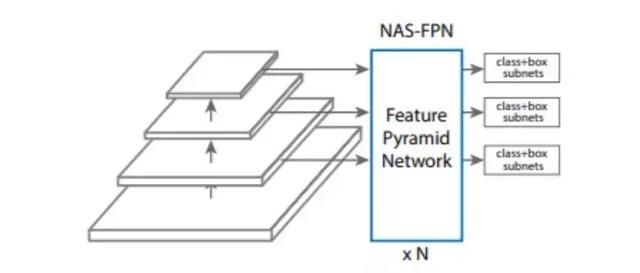
图 2:带有 NAS-FPN 的 RetinaNet。在本文中,特征金字塔网络将由神经架构搜索算法来搜索。骨干网络和用于类和框预测的子网络遵循 RetinaNet [23] 中的原始设计。
为了找到更好的 FPN,研究者利用 Quoc Le 等人在「Neural architecture search with reinforcement learning」中提出的神经架构搜索(NAS)框架。NAS 利用强化学习训练控制器在给定的搜索空间中选择最优的模型架构。控制器利用子模型在搜索空间中的准确度作为奖励信号来更新其参数。因此,通过反复试验,控制器逐渐学会了如何生成更好的架构。
研究者还为 FPN 设计了一个搜索空间来生成特征金字塔表征。为了实现 FPN 的可扩展性,研究者强制 FPN 在搜索过程中重复 N 次,然后连接到一个大型架构中。他们将这一特征金字塔架构命名为 NAS-FPN。
【1】谷歌大脑提出NAS-FPN:一种学会自动架构搜索的特征金字塔网络:http://www.360kuai.com/pc/9f5779082a933626a?cota=4&sign=360_57c3bbd1&refer_scene=so_1