7天深度学习-day4-神经网络学习“你拍我猜”
分类人、狗、猫,‘class’是0,代表是人;1代表是猫猫;2代表是狗狗;
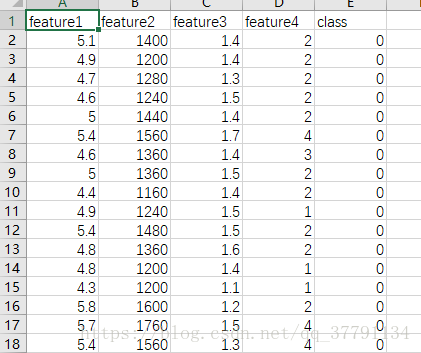
特征是 4个数据特征,暂且不知特征怎么来的,反正是csv文件,150个样本。
遇到很多困难。
1、加载数据、
为了加载数据并很好地进行格式化,我们将使用两个非常有用的包,即 Pandas 和 Numpy。 你可以在这里阅读文档:
- https://pandas.pydata.org/pandas-docs/stable/
- https://docs.scipy.org/
%matplotlib inline
# Importing pandas and numpy
import pandas as pd
import numpy as np
from IPython.display import display
# present all plots in the notebook
# Reading the csv file into a pandas DataFrame
dataset = pd.read_csv('data.csv')
#random all the rows in dataset
dataset = dataset.sample(frac=1)
# print data shortcut
dataset[:10]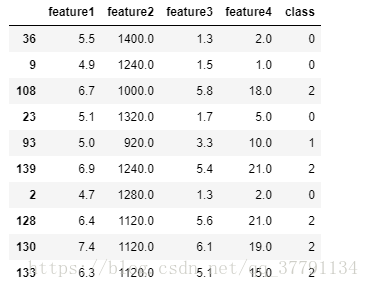
2、数据分析 - 绘制数据,可视化的数据分析
首先让我们对数据进行绘图,看看他们互相之间的关系是什么。首先来看试一下feature1和feature2
# Importing matplotlib
import matplotlib.pyplot as plt
# Function to help us plot
def plot_points(dataset):
X = np.array(dataset[["feature1","feature2"]])
y = np.array(dataset["class"])
people = X[np.argwhere(y==0)]
cat = X[np.argwhere(y==1)]
dog = X[np.argwhere(y==2)]
plt.scatter([s[0][0] for s in people], [s[0][1] for s in people], s = 25, color = 'red', edgecolor = 'k')
plt.scatter([s[0][0] for s in cat], [s[0][1] for s in cat], s = 25, color = 'cyan', edgecolor = 'k')
plt.scatter([s[0][0] for s in dog], [s[0][1] for s in dog], s = 25, color = 'yellow', edgecolor = 'k')
plt.xlabel('Feature_1')
plt.ylabel('Feature_2')
# Plotting the points
plot_points(dataset)
plt.show()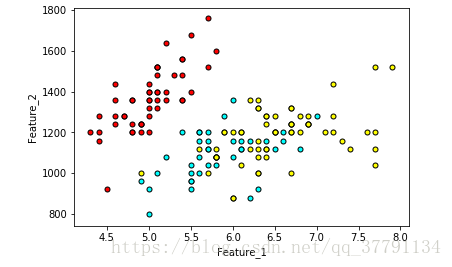
图上红色是人,青色是小猫,黄色是小狗。 粗略来说,这两个feature并没有很好地分离图像小狗,小猫和人。 也许将另两个features考虑进来会有帮助? 接下来我们将绘制一组图,用seaborn的pairplot函数来试试吧!
https://seaborn.pydata.org/generated/seaborn.pairplot.html
# plotting high-dimensional
import seaborn as sns
sns.pairplot(dataset, hue='class', vars=["feature1","feature2","feature3","feature4"])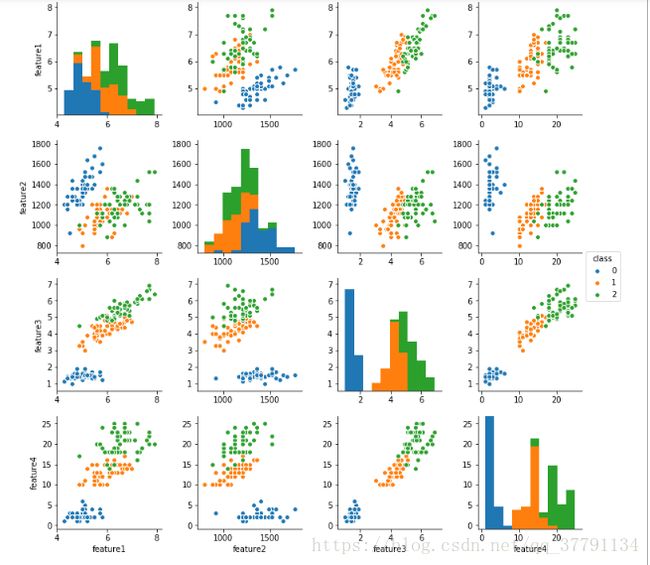
图上class=0,代表是人;1代表是猫猫;2代表是狗狗;
任务1: 将训练集拆分成自变量data及应变量标签label的组合
数据集中['feature1','feature2','feature3','feature4']是自变量data;
['class']则是应变量标签label;
可参考使用pandas中的iloc,loc用法。
https://pandas.pydata.org/pandas-docs/version/0.21/generated/pandas.DataFrame.iloc.html
https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.DataFrame.loc.html
# separate dataset into data - feature table and label table
data = dataset.iloc[:,0:4]
label = dataset.iloc[:,-1]
display(data[:10])
display(label[:10])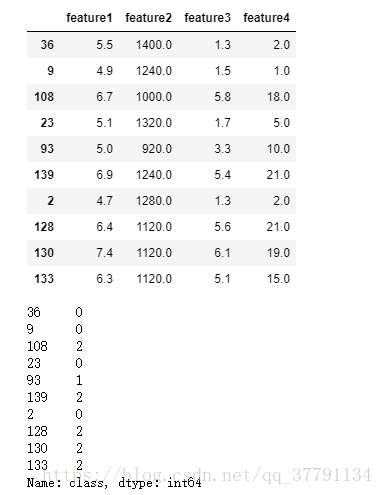
3、任务2: 将分类进行 One-hot 编码
为了实现softmax的概率分布,我们将使用Pandas 中的 get_dummies 函数来对label进行One-hot编码。
问题1: one-hot编码的作用是什么呢?
回答:(请双击cell进行回答) 1、使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。 2、将离散特征通过one-hot编码映射到欧式空间,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。 3、离散特征进行one-hot编码后,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化
# TODO: Make dummy variables for labels
dummy_label = pd.get_dummies(label)
# Print the first 10 rows of our data
dummy_label[:10] 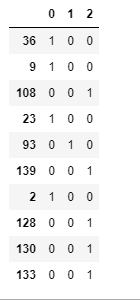
4、任务3: 数据标准化
由于神经网络是计算权重,因此我们需要对数据进行标准化的预处理。 我们注意到feature2和feature4的范围比feature1和feature3要大很多,这意味着我们的数据存在偏差,使得神经网络很难处理。 让我们将两个特征缩小,使用(x-min)/(max-min))来将特征归到(0, 1)。
# TODO: Scale the columns
min2 = np.min(data['feature2'] )
max2 = np.max(data['feature2'] )
data['feature2'] =(data.iloc[:,1]-min2) / (max2 -min2)
min4 = np.min(data['feature4'] )
max4 = np.max(data['feature4'] )
data['feature4'] =(data.iloc[:,3]-min4) / (max4 -min4)
# Printing the first 10 rows of our procesed data
data[:10]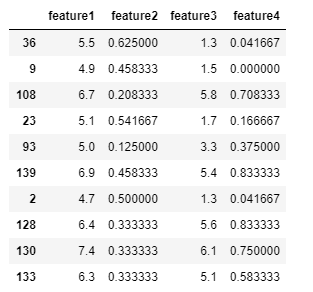
5、任务4: 将数据分成训练集和测试集
为了测试我们的算法,我们将数据分为训练集和测试集。 测试集的大小将占总数据的 10%。
你可以使用numpy.random.choice或者sklearn.model_selection.train_test_split函数。
https://docs.scipy.org/doc/numpy/reference/generated/numpy.random.choice.html
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
问题2: 拆分测试集的目的是什么?还有其他的拆分方式吗?
你的回答:分成训练集合测试集,测试集是为了检验从训练集顺利出来的模型的好坏,泛化性。 上面是按照数据量拆分的,其实还有按照数据分布的拆分。
TODO: split train and test dataset
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(data,test_size=0.1, random_state=0)
train_label, test_label = train_test_split(dummy_label,test_size=0.1, random_state=0)
print("Number of training samples is", len(train_data))
print("Number of testing samples is", len(test_data))
print(train_data[:10])
print(test_data[:10])
print(train_label[:10])
print(test_label[:10]) 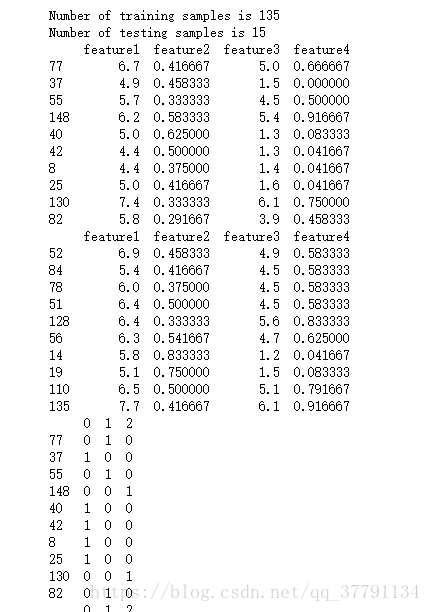
6、任务5: 训练多分类的神经网络
下列函数会训练二层神经网络。 首先,我们将写一些 helper 函数。

p指代x的特征数量;
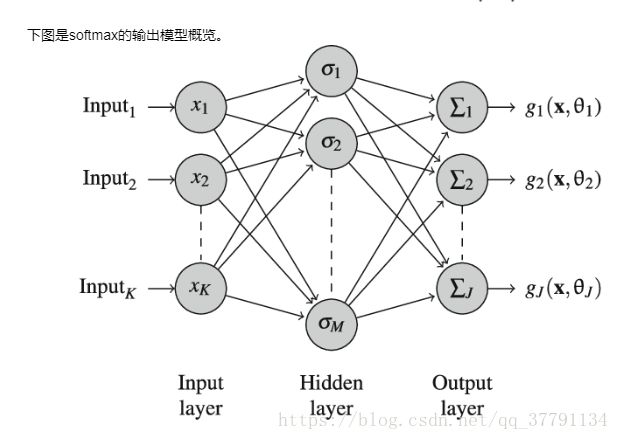
softmax函数常用于多分类目标的模型,他会把所有的output对sum(output)进行均一化,用于减少模型预测偏差。https://zh.wikipedia.org/wiki/Softmax%E5%87%BD%E6%95%B0
sigmoid函数常用于二分类目标的模型,他会将离散数值转换为概率数值。https://zh.wikipedia.org/wiki/S%E5%87%BD%E6%95%B0
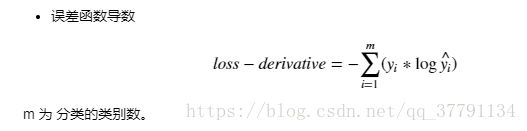
# TODO: Activation (softmax) function
def softmax(x):
z =np.exp(x)
s = z/ sum(z)
return s
def loss_derivative(x,y,y_hat):
loss = -(y * np.log(y_hat)).sum()
return loss
7、反向误差传递函数

# TODO: Write the error term formula
def error_term_formula(x, y, y_hat):
error_term = np.dot( (x[:,np.newaxis]), ( (y-y_hat)[np.newaxis,:] ))
return error_term8、任务6: 训练你的神经网络
设置你的超参数,训练你的神经网络
问题3: learnrate的设置有什么技巧?
回答:一般根据经验,刚刚开始的时候学习率小点,0.01,0.03,0.1,0.3,3,10等规律去上升,多尝试,多经验。
# Training function
def train_nn(features, targets, epochs, learnrate):
# Use to same seed to make debugging easier
np.random.seed(42)
n_records, n_features = features.shape
last_loss = None
# Initialize weights
weights = np.zeros([features.shape[1],targets.shape[1]])
for e in range(epochs):
del_w = np.zeros(weights.shape)
loss = []
for x, y in zip(features.values, targets.values):
# Loop through all records, x is the input, y is the target
# Activation of the output unit
# Notice we multiply the inputs and the weights here
# rather than storing h as a separate variable
output = softmax(np.dot(x, weights))
# The error, the target minus the network output
error = loss_derivative(x, y, output)
loss.append(error)
# The error term
error_term = error_term_formula(x, y, output)
#print(weights.shape)
del_w += error_term
# Update the weights here. The learning rate times the
# change in weights, divided by the number of records to average
weights += learnrate * del_w / n_records
# Printing out the mean square error on the training set
if e % (epochs / 10) == 0:
out = softmax(np.dot(x, weights))
loss = np.mean(np.array(loss))
print("Epoch:", e)
if last_loss and last_loss < loss:
print("Train loss: ", loss, " WARNING - Loss Increasing")
else:
print("Train loss: ", loss)
last_loss = loss
loss = []
print("=========")
print("Finished training!")
return weights
# TODO: SET Neural Network hyperparameters
epochs = 1000
learnrate = 0.03
weights = train_nn(train_data, train_label, epochs, learnrate)
10、任务7:计算测试 (Test) 数据的精确度
现在你的结果是One-Hot编号后的,想想如何获取的精度上的比较?
# TODO: Calculate accuracy on test data
# import pandas as pd
tes_out = test_label
predictions = pd.get_dummies(np.argmax(softmax(np.dot(test_data, weights)),axis=1))
# accuracy = None
accuracy = np.equal(tes_out,predictions).mean().min()
print("Prediction accuracy: {:.3f}".format(accuracy))Prediction accuracy: 0.933
11、任务8:用你的神经网络来预测图像是什么
在“images/”路径下有两张图片,我们已经使用通过图像提取特征的方式,分别得到了他们的4个feature值,存储在“validations.csv”中。
下面就由你来试试,看看你的神经网络能不能准确的预测他们吧!
# TODO: Open the 'validations.csv' file and predict the label.
# Remember, 0 = people, 1 = cat, 2 = dog
valid=pd.read_csv('./images/validations.csv')
min2 = np.min(valid['feature2'] )
max2 = np.max(valid['feature2'] )
valid['feature2'] =(valid.iloc[:,1]-min2) / (max2 -min2)
min4 = np.min(valid['feature4'] )
max4 = np.max(valid['feature4'] )
valid['feature4'] =(valid.iloc[:,3]-min4) / (max4 -min4)
predictions = np.argmax(softmax(np.dot(valid, weights)),axis=1)
print(predictions)[2 1]
12、任务9:(选做)神经网络分类算法的拓展应用
经过上面的神经网络训练,我们已经得到一个可以猜对三个对象的网络了!
如果想让你的神经网络判断更多的对象,我们就需要提供更多有标签的数据供他学习。
同时,我们也要教会我们的神经网络什么是特征(这个部分,我们已经帮你做好了:))。当我们把神经网络变得更深的时候,多层的神经网络就可以用来提取图像中的特征了!在正式的课程中,我们就会接触到深层网络的实现。
在这里,我们先借一个已经训练好能够识别1000个物体的网络来完成“你拍,我猜”的神奇功能吧。你可以随便上传一张照片到“images”的文件夹下,我们的神经网络就可以根据已经学习好的权重来猜你拍的照片是什么哦!快来试试吧!
上传的方法点击左上方的Jupyter图标,回到上级目录,进入‘/images’文件夹,并upload你所要分类的图片;
from ResNet_CAM import *
import glob
lists = glob.glob('images/*.png')
# TODO: Upload your image or pick up any image in the folder 'images/xx.png'
for img_path in lists:
fig, (ax1, ax2) = plt.subplots(1,2)
CAM = plot_CAM(img_path,ax1,ax2,fig)
plt.show()