17-seq2seq-映射关系
一、前言
本例将简单使用seq2seq模型训练出一个简单的词向量映射关系的案例,往细一点说,就是首先准备有映射关系的数据用来作为数据集,然后将输入数据映射到语义空间传入编码器,然后得到它的状态信息,然后把状态信息传入解码器并且该信息和EOS(终止符)作为第一个结点的输入,之后把第一个时间结点的输出和上一个结点的状态信息置入第二个时间结点的输入中去,依次循环,直到最后得到EOS的结果为止。此时拿到解码器的输出与真实输出的长度做全连接,然后得到的全连接层做哑编码处理,使用交叉熵损失函数或者平方和损失函数做梯度优化处理来训练本次的模型。
二、相关概念
Seq2Seq任务可以理解为,从一个Sequence做某些工作映射到(to)另外一个Sequence的任务,泛指Sequence到Sequence的映射问题。一个Sequence可以理解为一个字符串序列,在给定一个字符串序列后,希望得到与之对应的另一个字符串序列,如机器翻译,Seq2Seq不关心输入和输出的序列是否长度对应。
三、有关代码
1.导包和获取数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
EOS=0
vocab_size=6
input_embedding_size=10
def generate_data(batch_size,isTrain=True,seqlen=5):
batch_x=[]
batch_y=[]
dict_pre={0:4,1:3,2:2,3:1,4:0}
for _ in range(batch_size):
offset_x=np.random.randint(0,5,[seqlen])
offset_y=[dict_pre[ot] for ot in offset_x]
batch_x.append(np.array(offset_x))
batch_y.append(np.array(offset_y))
batch_x=np.array(batch_x).transpose((1,0))
batch_y=np.array(batch_y).transpose((1,0))
return batch_x,batch_y
2.定义有关参数和网络信息
#获取一批次数据
sample_now,sample_f=generate_data(isTrain=True,batch_size=3)
#获取词个数
seq_length=sample_now.shape[0]
#批次大小
batch_size=10
#学习率
learning_rate=0.04
tf.reset_default_graph()
#定义占位符
encoder_inputs=tf.placeholder(shape=(None,None),dtype=tf.int32)
decoder_targets=tf.placeholder(shape=[None,None],dtype=tf.int32)
decoder_inputs=tf.placeholder(shape=[None,None],dtype=tf.int32)
embeddings = tf.Variable(tf.random_uniform([vocab_size, input_embedding_size], -1.0, 1.0), dtype=tf.float32)
encoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, encoder_inputs)
decoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, decoder_inputs)
#搭建seq2seq网络模型
encoder_cell = tf.nn.rnn_cell.LSTMCell(seq_length)
encoder_outputs, encoder_final_state = tf.nn.dynamic_rnn(
encoder_cell, encoder_inputs_embedded,
dtype=tf.float32, time_major=True,
)
del encoder_outputs
#解码
decoder_cell = tf.nn.rnn_cell.LSTMCell(seq_length)
decoder_outputs, decoder_final_state = tf.nn.dynamic_rnn(
decoder_cell, decoder_inputs_embedded,
initial_state=encoder_final_state,
dtype=tf.float32, time_major=True, scope="plain_decoder",
)
decoder_logits = tf.contrib.layers.linear(decoder_outputs, seq_length)
decoder_prediction = tf.argmax(decoder_logits, 2)
loss = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(decoder_targets, depth=seq_length, dtype=tf.float32),
logits=decoder_logits,
))
#loss=tf.reduce_sum(tf.pow(tf.one_hot(decoder_targets,depth=seq_length)-decoder_logits,2))
train_op=tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
3.训练模型展示loss变化
loss_track=[]
show_epoch=50
training_epochs=5001
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(training_epochs):
batch_x,batch_y=generate_data(isTrain=True,batch_size=batch_size)
encoder_inputs_=batch_x
decoder_targets_=batch_y.tolist()
decoder_targets_.append([EOS]*len(decoder_targets_[-1]))
decoder_targets_=np.array(decoder_targets_).reshape(seq_length+1,-1)
decoder_inputs_=batch_y.tolist()
decoder_inputs_=[[EOS]*len(decoder_inputs_[-1])]+decoder_inputs_
decoder_inputs_=np.array(decoder_inputs_).reshape(seq_length+1,-1)
#print(decoder_targets_,'____________',decoder_inputs_)
feed_dict={encoder_inputs:encoder_inputs_,decoder_targets:decoder_targets_,
decoder_inputs:decoder_inputs_}
_,loss_=sess.run([train_op,loss],feed_dict=feed_dict)
loss_track.append(loss_)
if epoch%show_epoch==0:
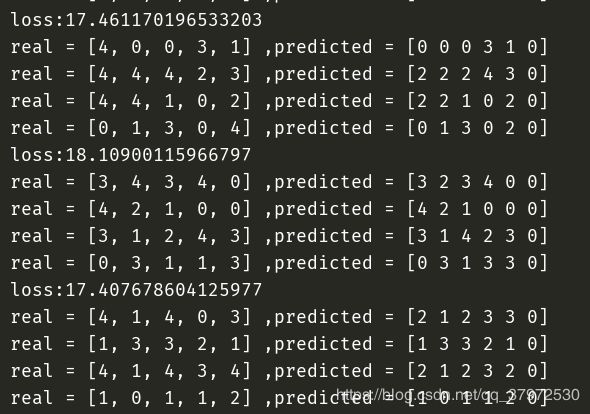
print('loss:{}'.format(loss_))
predict_=sess.run(decoder_prediction,feed_dict)
for i, (inp, pred) in enumerate(zip(feed_dict[encoder_inputs].T, predict_.T)):
print('real = {}'.format([dict_value[item] for item in inp]))
print('predicted = {}'.format(pred))
if i >= 3:
break
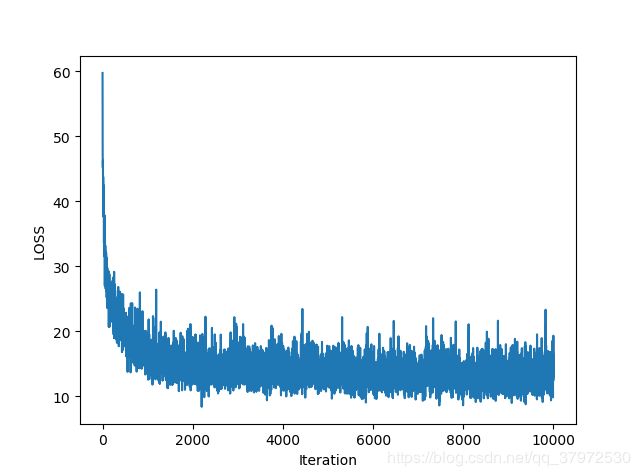
plt.ylabel('LOSS')
plt.xlabel('Iteration')
plt.plot(loss_track)
plt.show()
4、结果附图
四、总结与分析
1.本篇本来是准备写回归预测但是由于对seq2seq的理解不是特别深入,导致相关函数无法自己编写,而且有关的内容介绍所使用到的API博主下载了多个版本的TensorFlow都没有找到,故只是简单的实现了一下seq2seq中最简单的用法,若所写有错误,请指正批评。
2.本篇并没有加入seq2seq常用的attention机制,所以准确率会有所缺失。后面若有其他机会,再行更新。