MySQL高可用框架--组复制(group replication)搭建测试
一、框架搭建
1.首先备份主库数据,有两种方法,冷备份和热备份。冷备份需要先停止master服务,sudo/etc/init.d/mysql stop,然后通过cp或者scp等命令将数据文件传输到指定文件夹,这里我选择在一台服务器上启动三个实例来搭建组复制,所以就用sudo cp -R /var/lib/mysql /home/piriineos/data/mysql/data1/来复制数据,需要注意的是,这里用root权限复制数据所以在目标地点的数据所有者是root,对mysql需要将数据文件改为mysql所有,sudo chown -R mysql /home/piriineos/data/mysql ,复制成功后还需要注意一点就是auto.cnf文件,用来保存根据sererid生成的server uuid,对组复制有用,用来唯一标识mysql实例,这里由于复制的master的文件,所以将uuid随便改几个数字以区别开来。
热备份不需要停止服务,这在生产环境是必须的条件。这里我用mysqldump来转储数据,mysqldump对innodb表来说不影响服务,但是对于myisam表会用FTWRL来锁住所有表,导致服务停止。这里我就不备份系统表了,mysqldump --databases mgr--single-transaction --master-data=2 -uroot -p -h127.0.0.1>/home/piriineos/data/msater_backup.sql 。 然后在初始化一个新的数据库,mysql_install_db --basedir=/var/lib/mysql--datadir=/home/piriineos/data/mysql/data1/ --user=mysql,然后启动实例用source或者通道将备份的库导入到新实例的库中,不过在此之前需要将新的两个数据库配置一下配置文件。
2.8.0的真正的配置文件并不是存储在/etc/mysql/my.cnf,可以将其打开发现!includedir /etc/mysql/mysql.conf.d/这么一句话,这是将这个文件里的内容include到my.cnf里,因而我将真正的配置文件复制两份到新的数据库那里,sudo cp /etc/mysql/mysql.conf.d/mysqld.cnf/home/piriineos/data/mysql/data1/ ,同样需要更改所有者,然后配置参数。
首先是实例启动参数的配置:
port = 3307
pid-file =/tmp/mysql1.pid
socket =/tmp/mysql1.sock
datadir =/home/piriineos/data/mysql/data1/mysql
log-error =/home/piriineos/data/mysql/error1.log
server-id = 13307 #这个必须设置,不然会使用默认值
然后是mysql运行参数的设置:
innodb_buffer_pool_size = 1073741824 #我的机器总内存8G,系统运行占用3G,因而每个实例分配1G内存
innodb_buffer_pool_instances = 1
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1 #跟上一个参数配合使用,在每次事务的提交阶段分别前后写入硬盘
binlog_checksum = NONE #组复制必须关闭
open_files_limit = 65535
thread_cache_size = 8
transaction_isolation =READ-COMMITTED
然后是日志和gtid的参数设置:
log_bin = mysql-bin #避免使用默认服务器名
binlog_format = row #组复制必须
slow_query_log = 1
slow_query_log_file =/home/piriineos/data/mysql/data1/mysql/mysql-slow.log
skip-slave-start = 1
log-slave-updates = 1 #必须
gtid-mode = ON #必须
enforce-gtid-consistency = ON #必须
binlog_gtid_simple_recovery=1 #在5.7.17后建议开启,加快恢复速度
master_info_repository=TABLE #必须
relay_log_info_repository=TABLE #必须
sync_relay_log = 1
sync_master_info = 100
sync_relay_log_info = 100
relay-log-index = relay-log.index
relay-log = relay-log
然后是组复制参数设置:
transaction_write_set_extraction =XXHASH64 #唯一确定事务影响行的主键,必须开启
loose-group_replication_group_name ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa' #唯一标识一个组
loose-group_replication_ip_whitelist ='127.0.0.1/8' #允许接入组的ip来源
loose-group_replication_local_address ='127.0.0.1:33062' #用于组间通信的地址
loose-group_replication_group_seeds ='127.0.0.1:33061,127.0.0.1:33062,127.0.0.1:33063' #donor地址
loose-group_replication_bootstrap_group =OFF #引导节点设置
loose-group_replication_single_primary_mode= true #单主模式
loose-group_replication_enforce_update_everywhere_checks= false
loose-group_replication_start_on_boot =false #避免重启自动自动组复制
3.配置文件写好后,通过mysqld或者mysqld_safe启动实例,需要注意的是这里有个坑,就是启动的时候必须用mysql身份进行,用其他用户和root都不行,这个说在5.7已经修复,但是我现在8.0了还是有问题。。sudo -umysql mysqld_safe--defaults-file=/home/piriineos/data/mysql/data1/my.cnf 。启动成功后将备份的数据导入,mysql -uroot -p
4.启动三个实例后在上面创建复制用户,create user '[email protected]' identified by 'u201313742'。然后给授予复制的权限,grant replication slave on *.* to '[email protected]'identified by 'u201313742'。
5.安装引擎,8.0中默认是不安装组复制引擎的,install plugin group_replication soname'group_replication.so'。可以通过show plugins查看是否安装成功。
6.检查组复制相关参数是否设置正确,show variables like '%group%;'如果不正确通过set global设置。检查完毕后准备启动组复制。这里一定要注意的一点是,如果你是mysqldump并且没有dump系统库,或者你在新实例上reset master过,那么一定要检查gtidexecuted和gtid purged参数,上面两个会导致新库的这两个参数被清空,从而使slave将master的所有gtid事务全都拉取过来。可以通过set globalgtid_purge='xx'来将slave已经执行过的gtid事务标记。
7.检查完毕后先启动master。master作为第一个节点需要初始化整个组复制环境,set globalgroup_replication_bootstrap_group=on;将节点配置到某个channel,change master tomaster_user='repl',master_password='u201313742' for channel'group_replication_recovery';这里有个warning就是显示使用密码登录很不安全,不知道有什么办法可以更安全登录。然后start group_replication启动组复制,并且将bootstrap的参数关闭。
8.master启动完毕后再启动两个slave,同样需要安装组复制引擎,并且创建复制用户,并授权,注意要与master的用户一致。然后changemaster to master_user='repl',master_password='u201313742' for channel'group_replication_recovery';然后start group_replication。
9.观察节点状态是否正确,可以通过select * from mysql.group_replication_members;来查看跟组复制相关的一些表来了解节点状态,如果节点全都是online,则说明一切正常,slave已经追上或者快要追上master,如果为recovery则说明slave正在从donor恢复或者正尝试连接donor进行恢复,如果是error(仅本地有此状态)则说明这个节点已经挂了。需要注意的是,组复制遵从多数原则,即需要大于组成员数一半的节点才能正常工作,因而两个节点时有个节点宕机那么另一个节点会进入super_read_only状态避免写入,同理三个节点则最多容忍一个节点宕机,以此类推。
下面是我踩过的一些坑:
1.[ERROR] Plugin group_replicationreported: 'This member has more executed transactions than those present in thegroup. Local transactions: 1d1d8fd2-74a5-11e8-b1d4-80fa5b3b3f3d:1 > Grouptransactions: '
2018-06-23T09:36:09.290682Z0 [ERROR] Plugin group_replication reported: 'The member contains transactionsnot present in the group. The member will now exit the group.'
slave执行的事务gtid与master不一致,如果只是因为误操作,或者是一些无关紧要的数据,可以通过set globalgroup_replication_allow_local_disjoint_gtids_join=on;来忽略这些事务,或者通过reset master清空gtidexecuted表然后重新设置gtid purged参数跟master的gtid executed一致来跳过这些事务。如果这些数据不一致会导致问题那么可以通过pt-table-sync来检查误差数据并同步,然后再通过reset master等操作重设gtid相关参数,需要注意的是这个工具需要binlog格式为statment以使slave也能执行同样检查语句。
2.[ERROR] Plugin group_replication reported:'There was an error when connecting to the donor server. Please check thatgroup_replication_recovery channel credentials and all MEMBER_HOST columnvalues of performance_schema.replication_group_members table are correct andDNS resolvable.'
主机名解析不正确,我看了下/etc/hosts文件,发现piriineos主机名居然解析为127.0.1.1,而我的donor名单都是127.0.0.1,把piriineos也设置为127.0.0.1即可。
3.[ERROR] Plugin group_replicationreported: '[GCS] Timeout while waiting for the group communication engine to beready!'
一般是组中半数以上节点挂了。
4.[ERROR] Slave I/O for channel'group_replication_recovery': Fatal error: Invalid (empty) username whenattempting to connect to the master server. Connection attempt terminated.Error_code: 1593
忘记给slave也change master to了。
5.[ERROR] Slave SQL for channel'group_replication_recovery': Error 'Operation CREATE USER failed for'piriineos'@'127.0.0.1'' on query. Default database: ''. Query: 'CREATE USER'piriineos'@'127.0.0.1' IDENTIFIED WITH 'mysql_native_password' AS'*077BFD72D9E814194FBA9A90A6A8DB13BC476718'', Error_code: 1396
slave apply了master操作系统表的事务,这里是master上创建用户的语句,忘记set sql_log_bin=0;了,不想让slave执行的操作都需要设置它。这里的解决办法是直接把这个事务的gtid放到purged表中,跳过他即可。
二、框架原理
1.组复制基于分布式一致性协议(paxos协议的变体),遵循大多数规则,在多主模式下事务提交需要(N/2+1)的节点数同意才能通过。组复制其实跟gelera replication很相似,除了大多数规则,关于galera跟MGR的比较可以看看这篇文章
Galera vs Group Replication的区别。通过一致性协议,MGR可以保证事务全局的原子性和有序性。组中维护一个全局的事务执行列表,存储了全局认可的已执行事务,此时各个节点可以分别在自己的库中执行自己的事务,但是在提交时需要广播通知其他的所有节点,广播中包括这个事务的相关信息(影响的行等)和事务提交时全局事务列表,收到广播的节点将事务收进事务队列(该队列中的事务都是广播后的事务),事务队列中的事务会进行冲突检测,出现冲突的事务只提交最先广播(队列最前面)的事务,其他的rollback。有人可能会疑惑为什么每个节点单独rollback而不通知其他节点仍然可以保持一致性,这是因为事务队列是全局一致的,顺序也是全局一致的,因而冲突检测的结果自然也就一样了。
2.冲突检测的原理大致如下:冲突检测有两个因素:事务是否修改了同样的数据(以行为单位,通过主键识别);是否是同时修改的。通过事务执行时的数据库快照版本来判定。数据库的快照是用GTID SET来标识的。事务提交前从全局变量gtid_executed中获取GTID SET。这个GTIDSET就是代表了当前事务在提交前,数据库中已经执行了的GTIDs。也即是当前事务提交前,数据库的快照版本。数据库的快照版本会随着事务的Binlog Events一起广播到其他的节点上,用来做冲突检测。
冲突检测时,从冲突检测数据库中找到当前事务修改的数据的记录。如果没有找到,就没有冲突。如果找到了,则将自己的快照版本和冲突检测数据库中记录的GTID SET进行比对:如果自己的快照版本中包含了冲突检测数据库中记录的所有GTIDs,那么就没有冲突。自己的快照中包含了,说明该事务在初始节点上执行时,上一次对本行数据的修改已经在初始节点上提交了。所以就不是同时执行的。如果自己的快照版本中没有包含冲突检测数据库中记录的所有GTIDs,则说明当前事务在初始节点上执行时,上一次对本行数据的修改还没有在初始节点上执行。因此判定为同时执行。
3.组复制提供失败检测:组复制提供了一种故障检测机制,其能够找到和报告哪些服务器是没有响应的,并假定其是死的。更深入地说,故障检测器是提供关于哪些服务器可能已死的信息的分布式服务。后续如果组同意怀疑可能是真的,则由组来决定该服务器确实已经失败。这意味着组中的其余成员进行协调决定排除给定成员。服务器无响应时触发怀疑机制。当服务器A在给定时间段内没有从服务器B接收消息时,发生超时就会引起怀疑。 如果服务器与组的其余部分隔离,则它怀疑所有其他服务器都失败。由于无法与组达成协议(因为它无法获得大多数成员认可),因此其怀疑没有后果。当服务器以此方式与组隔离时,它无法执行任何本地事务。
4.组复制提供组成员视图服务:MySQL组复制依赖于组成员服务group membership service。这是内置的插件。它定义哪些服务器是在线的并参与在复制组中。在线服务器列表通常称为视图view。因此,组中的每个服务器具有一致的视图,其是在给定时刻积极参与到组中的成员。
复制组的成员们不仅需要同意事务是否提交,而且也需要决定当前视图。因此,如果服务器同意新的服务器成为组的一部分,则该组本身被重新配置以将该服务器集成在其中,从而触发视图改变。相反的情况也发生,如果服务器自愿地离开组,则该组动态地重新布置其配置,并且触发视图改变。
当成员自愿离开时,它首先启动动态组重新配置。这触发一个过程,所有成员必须同意新的视图(也就是新视图中没有该离开成员)。然而,如果成员不由自主地离开(例如它已意外停止或网络连接断开),则故障检测机制实现这一事实,并且提出该组的重新配置(新视图没有该离开成员)。如上所述,这需要来自组中大多数成员的同意。如果组不能够达成一致(例如,以不存在大多数服务器在线的方式进行分区),则系统不能动态地改变配置,从而阻止脑裂情况引起的多写。
三、框架测试
1.主节点宕机测试:
*主节点宕机分为两种情况,一种是情况不太严重的,仅仅是因为某种原因服务器崩溃了,但是 数据还在并且完好。
首先让三个实例进组,然后kill掉master。ps -ef|grep mysql找到master的进程:mysql 650 1 0 19:51 ? 00:00:04 /usr/sbin/mysqld --daemonize--pid-file=/var/run/mysqld/mysqld.pid,然后sudo kill -9 650。然后查看此时组的状态,select* from performance_schema.replication_group_members;

此时3307端口的实例被选为的新的master,这里插入一些数据模拟宕机后应用继续向新主库插 入数据,insert into mgr.tb1 (name) values('test'),('test')....('test');然后启动宕机节点sudo /etc/init.d/mysql start,并将其加入组中,查看节点状态:

可以发现是recovering状态,代表新加入节点正在从donor那里拉取落后的事务并进行重现。
等待状态变为online后查看mgr.tb1表的数据:

查看主节点和宕机节点的gtid参数:


*然后模拟主节点宕机并且数据丢失的情况,首先备份主节点重要库的数据,mysqldump --databasesmgr --single-transaction --master-data=2 -uroot -p -h127.0.0.1 -P3306 >/home/piriineos/data/msater_backup.sql,并记录此时的gtid executed,然后先kill掉现在的3307 端口 的新主节点,然后 sudo rm -rf/home/piriineos/data/mysql/data1/mysql/ 模拟数据丢失, 查看此时组的状态发现3308端口实 例成为了新的主节点,同样插入一些数据。
用mysql_install_db重建数据库,重启节点后将备份的数据导入到新库中,需要注意的是这里的 系统表都是mysql_install_db重建的,因而以前系统表和binlog等数据都不存在了,因而需要设置 gtidpurged,将其设置为之前记录的gtid executed,不然启动组复制后会从donor拉去重复数据,设置 将节点加入组中,查看show master status发现宕机节点已经追上其他节点。
不过实际情况肯定要比这种模拟复杂的多,像宕机节点加入后进行追赶时应用仍然会像主节点 插入数据,此时如果插入速度过快导致新节点追不上组中其他节点会进行流量控制降低数据更新速 度来让新节点追上来。
组复制通过heartbeat发现有节点不能通信时会通知其他节点不再往该节点发送数据,如果发现 不能通信的是主节点,则会根据权重选取新的主节点,通过这个机制组复制能够快速的从主节点宕 机中恢复过来。不过仍然存在的问题是主节点切换后应用不知道,需要中间件调节,还有就是宕机 的节点恢复和重新加入组需要手动操作。
2.高并发OLTP场景测试:
*测试环境为:操作系统:debian8;cpu:i7 6700HQ(2.6GHz);内存:三星8G;硬盘:西数机械 硬盘1T。
*用sysbench来模拟oltp高并发场景,首先准备测试数据:sysbench./home/piriineos/sysbench- 1.0/tests/include/oltp_legacy/oltp.lua--mysql-host=127.0.0.1 --mysql-port=3307 --mysql-user=root –mysql- password=u201313742 --oltp-test-mode=complex--oltp-tables-count=5 --oltp-table-size=100000 – threads=5 --time=60 --report-interval=10prepare。
测试脚本用的是sysbench自带的,这个脚本进行了五种不同形式(ref、all、order by等)的随机数查询,以及随机的update,delete和insert。测试模式是complex,即增删改查全都测试并且使用事务,测试五个表,每个表100000条数据(主要是当时手滑给/挂载的空间太少了,只有10G,不敢弄多了数据),并发连接数为3(怕太多了给电脑跑崩溃了)。测试跟实例在同一台电脑,因而会对结果有一些影响。
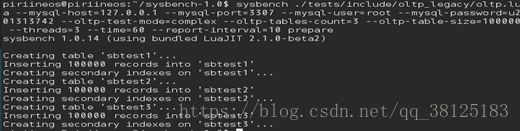
然后执行测试:sysbench./tests/include/oltp_legacy/oltp.lua --mysql-host=127.0.0.1 –mysql- port=3307 --mysql-user=root--mysql-password=u201313742 --oltp-test-mode=complex –oltp-tables- count=3 --oltp-table-size=100000 --threads=3--time=60 --report-interval=10 run >> /home/piriineos/work/sysbench.log。
此时master和slave的状态为:
show processlist(master):

show processlist(slave):
show master status(master):

show master status(slave):

查看sysbench执行日志:
[ 10s ] thds: 3 tps: 54.19 qps: 1088.30(r/w/o: 762.86/216.76/108.68) lat (ms,95%): 369.77 err/s: 0.00 reconn/s: 0.00
[ 20s ] thds: 3 tps: 68.80 qps: 1377.21(r/w/o: 963.21/276.40/137.60) lat (ms,95%): 200.47 err/s: 0.00 reconn/s: 0.00
[ 30s ] thds: 3 tps: 55.50 qps: 1108.80(r/w/o: 777.00/220.80/111.00) lat (ms,95%): 204.11 err/s: 0.00 reconn/s: 0.00
[ 40s ] thds: 3 tps: 53.00 qps: 1060.30(r/w/o: 742.00/212.30/106.00) lat (ms,95%): 176.73 err/s: 0.00 reconn/s: 0.00
[ 50s ] thds: 3 tps: 69.20 qps: 1384.90(r/w/o: 968.80/277.70/138.40) lat (ms,95%): 167.44 err/s: 0.00 reconn/s: 0.00
[ 60s ] thds: 3 tps: 73.40 qps: 1468.00(r/w/o: 1027.60/293.60/146.80) lat (ms,95%): 4.57 err/s: 0.00 reconn/s: 0.00
SQL statistics:
queries performed:
read: 52416
write: 14976
other: 7488
total: 74880
transactions: 3744 (61.30 per sec.)
queries: 74880 (1226.07 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 61.0715s
total number of events: 3744
Latency (ms):
min: 2.68
avg: 48.70
max: 3409.39
95th percentile: 196.89
sum: 182324.61
Threads fairness:
events (avg/stddev): 1248.0000/46.27
execution time (avg/stddev): 60.7749/0.41
其中比较重要的是tps、qps和latency 95th percent,tps平均为61.3,qps平均为1226.07,前95 的请求响应时间为196ms,这个值太大了,在实际生产环境是不可以接受的,不过考虑到这里三个实 例都运行在同一个服务器,并且使用的是机械硬盘(ssd没空间了),而且观察到每10s的请求延时一 直在下降,说明测试时间还是太短,时间长了后innodb buffer pool等内存数据稳定后延时应该会稳定 到一个低一些的值,因而这么高也是情理之中。
这次测试因为条件限制存在着一些问题,比如说多个实例在同一服务器;测试跟mysql实例在同一服务器;测试数据过少;测试并发度不够;测试时间太短;测试次数不够;没有对从库进行读测 试。
其中在测试完成后观察slave同步的过程中有一个发现,由于有一个节点是master宕机后变成 slave,因而两个slave的参数设置有一些不一致,其中一个sync_relay_log=1,sync_master_info=100,
sync_relay_log_info=100;而另一个则全都为默认值10000,我通过手动show master status发现10000 的这一方完成同步的速度大概要比另一个快一倍,我把较慢的那个页设置为10000后很快也完成了 同步,可见这三个参数影响还是很大的。
3.测试是否有脑裂:
*对于MGR来说是不存在脑裂的,因为MGR是大多数原则,正常运行或者做出决议等都需要大 多数节点参与,当部分节点失去连接时,多数那一方(数量需要大于N/2+1,不然也无法写入只能 读)正常运行,并把少数一方剔除,而少数一方的节点广播后发现节点数量少于N/2后就会强制进 入super read only状态,不再接受应用写入请求,因而也就不会造成多写问题。不过有个问题就是少数节点权限切换后对于应用是非透明的,应用依然会进行写入请求,因而需要其他组件来调节。
由于我是在一台电脑上运行的三个实例,没办法用改变ip的方法来让模拟脑裂,而通过iptables 禁用端口tcp连接也不知道为什么不管用,所以就不测试脑裂的情况了。
在某些非组复制集群上是有可能发生脑裂的,比如DRBD+heartbeat的方案,备库通过heartbeat 监视master状态,备库和master之间的连接中断但是master仍然活着,此时drbd以为master宕机自动升级为新的master就会导致脑裂,像这种类似的情况可以通过一些技巧来避免脑裂,比如说使用冗余的heartbeat连接,只有在全部连接都失连时才判断;连接断开后重启对方,避免同时存在多个活跃节点;设置仲裁节点,连接断开后双方各自ping一下仲裁节点判断是否是自己的问题;通过第三方节点(vip)来控制备库升级等。
四、总结
1.在使用MGR还是发现了一些问题,一个是节点切换对应用不透明,应用依然按照原来的认知写入和读取;一个是宕机后的节点恢复需要手动;一个是断开连接的节点重新连接后不会自动加入节点,与之类似的gelera cluster会等待连接恢复重连或者timeout踢出节点。
2.MGR的大多数原则也存在一些隐患,那就是无法处理大多数节点宕机的情况,这还是有可能的,当它们宕机后整个组将不能写入。
3.还有其他的一些限制比如:仅支持InnoDB表,并且每张表一定要有一个主键,用于做write set的冲突检测;必须打开GTID特性,二进制日志格式必须设置为ROW,用于选主与write set;COMMIT可能会导致失败,类似于快照事务隔离级别的失败场景;目前一个MGR集群最多支持9个节点;不支持外键于savepoint特性,无法做全局间的约束检测与部分部分回滚;二进制日志不支持binlog eventchecksum等。