Hadoop学习笔记1
Hadoop学习笔记1
- 1 大数据概述
- 1.1 什么是大数据
- 1.2 大数据典型应用
- 1.2.1影视推荐系统
- 1.2.2 精准营销系统
- 2 Hadoop概述
- 2.1Hadoop简介
- 2.2 Hadoop1.x与Hadoop2.x的区别
- 2.3Hadoop发行版
- 2.3.1 CDH
- 2.3.2 HDP
- 2.4 Hadoop生态系统
- 2.4.1HDFS
- 2.4.2Yarn
- 2.4.3MapReduce
- 2.4.4ZooKeeper
- 2.4.5Hive
- 2.4.6 HBase
1 大数据概述
1.1 什么是大数据
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
一定时间范围与常规软件工具:RDBMS
海量:SKU1000000000 * 1KB = 1,000,000,000KB = 1,000GB = 1TB
大数据中计量单位一般使用如下(由小到大):B、KB、MB、GB、TB、PB、EB、ZB、YB、NB„„
高增长率:淘宝网在2016年12月份的月活跃用户数量为4.93亿。所谓月活跃用户指的是,在一个月中所有活跃用户去重后的数量。
4.93亿/ 30天= 1650万
最少:1650万* 1MB = 16,500,000MB = 15.5TB
最多:4.93亿* 1MB = 493,000,000MB = 493TB
多样化:
新处理模式:
1.2 大数据典型应用
1.2.1影视推荐系统
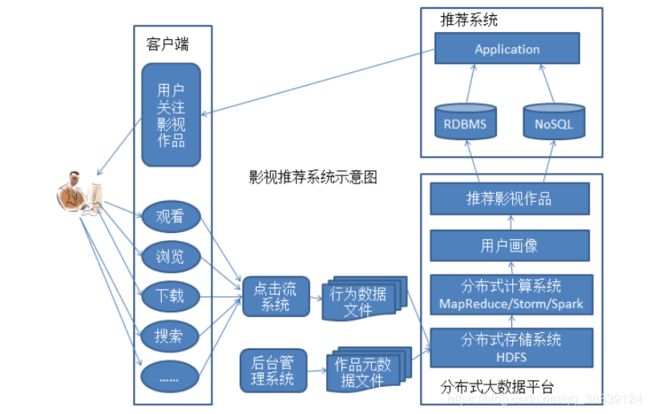

1.2.2 精准营销系统
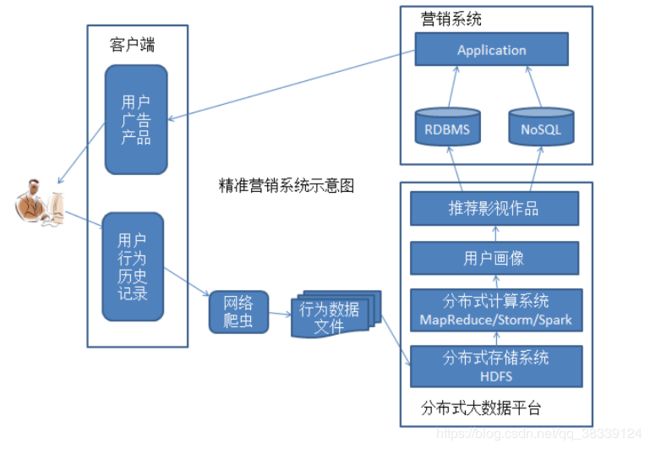
2 Hadoop概述
2.1Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,其主要用于解决海量级(PB级)数据的存储与计算问题。(1PB= 1024TB)Hadoop适合解决大数据问题,主要是因为其包含了两大系统:大数据存储系统HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)与大数据计算系统MapReduce。
对于Hadoop2.x,其又新增了一个系统Yarn(Yet Another Resource Negotiator,另一种资源协调者),其主要用于资源管理(CPU、内存、硬盘、网络„„)。故,Hadoop2.x由三个框架构成:
1、HDFS:分布式文件系统,提供了高可靠性、高扩展性及高吞吐率的数据存储服务。
2、MapReduce:分布式计算系统,提供了高扩展性、高容错性的离线计算服务,易于代码编写。
3、Yarn:集群资源管理系统。
Hadoop之父是Doug Cutting,其在研发一个网络搜索引擎Nutch时遇到问题,然后查阅了Google的两篇论文:GFS(Google File System)与MapReduce(分布式计算),很快Doug将这两个理论应用到了Nutch上,形成了NDFS(Nutch Distributed File Syste)与新的MapReduce。即Hadoop的前身。
2.2 Hadoop1.x与Hadoop2.x的区别

2.3Hadoop发行版
目前Hadoop发行版大多是收费的,但企业在使用Hadoop时选择的一个重要标准就是是否收费,所以大多数企业选择的都是免费的。目前比较知名的免费Hadoop发行版有两个:CDH与HDP。
2.3.1 CDH
CDH,Cloudera’s Distribution, including Apache Hadoop,是Cloudera公司开发的一款免费Hadoop发行版,是我国使用最多的一个发行版。
2.3.2 HDP
HDP,Hortonworks Data Platform,Hortonworks数据平台,是Hortonworks公司开发的一款100%开源的Hadoop发行版。该版本允许载入、存储、处理和管理几乎任何格式和任何规模的数据。
2.4 Hadoop生态系统
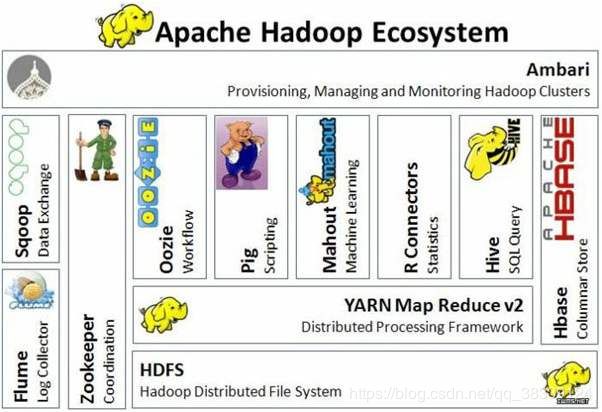
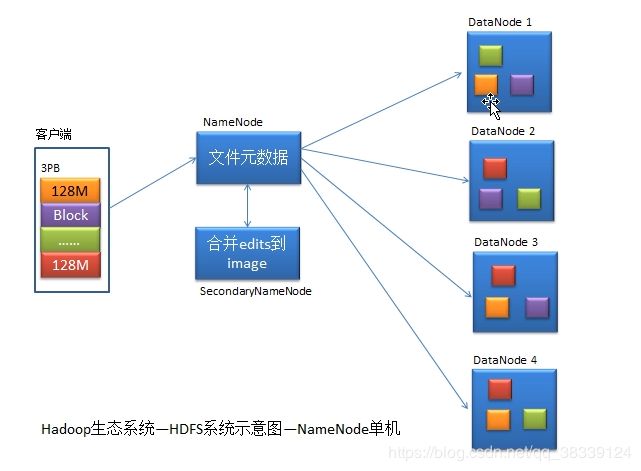
2.4.1HDFS
HDFS是一个高可靠、高扩展、海量级大数据存储系统。
1、海量级:这里的海量级指的是HDFS适合处理海量级大小的文件,即文件越大越好。因为HDFS会将其要存储的文件切割成大小相等的数据块(Block),并为每个文件生成一条元数据(文件名、文件大小、切割块数、数据块的存储位置等)。
2、高可靠:HDFS采用集群冗余方式保证了数据的可靠性。其会将每一个数据块默认保存三份,分别存储在不同的机器上。一旦一台正在使用的数据块所在机器发生故障,集群会根据文件元数据自动获取到其它机器上的该数据块。
3、高扩展:若集群中节点机器资源出现了紧张局势,可马上在集群中添加新的节点机器,HDFS能够自动感知到它们。
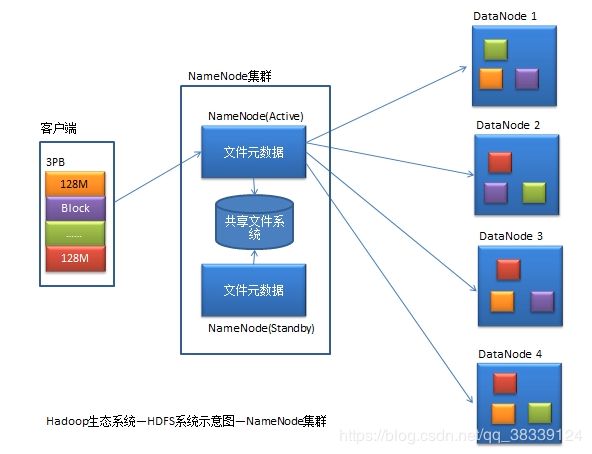
DataNode:用于存放真正的数据NameNode的功能:
1、存放文件元数据
2、监控DataNode的健康状
3、态负载均衡机架感知
4、动态扩容
2.4.2Yarn
Yarn是Hadoop2.x中的资源管理系统。其采用的是Master-Slave管理方式,即主从管理方式。主是ResourceManager进程,负责管理整个集群中所有资源;从是NodeManager进程,分布在各个DataNode中,负责管理本地资源。

2.4.3MapReduce
MapReduce是一个适合海量级数据的、可扩展的、高容错的、离线计算系统。其计算主要由Map与Reduce两类计算组件构成。
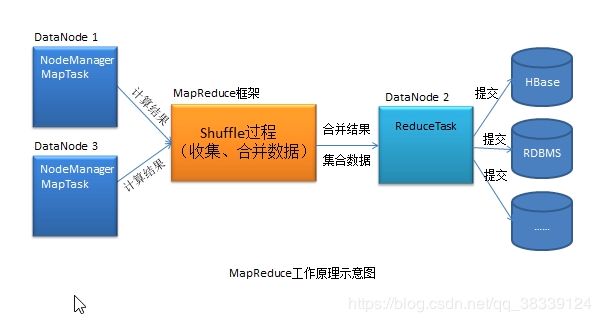
Map的计算与Reduce是否运行是无关的,虽然Reduce的提交才标志着任务的完成,但Reduce未启动并不影响Map的计算,这就是离线计算。
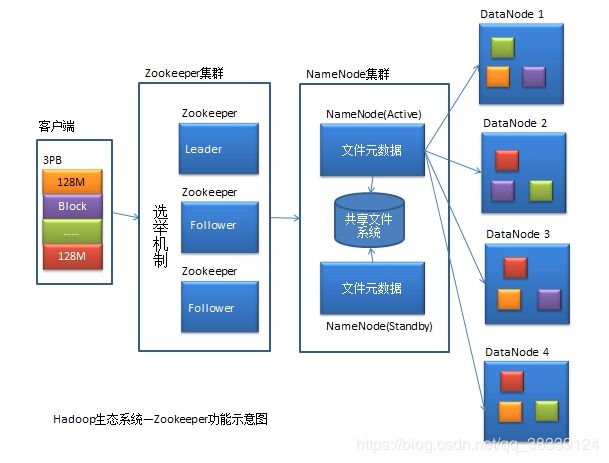
2.4.4ZooKeeper
Zookeeper是一个专门为分布式应用提供公布式的、开源的协调服务的,它主要是用来解决分布式应用中经常遇到的一些数据管理问题的。最典型的就是Master-Slave结构集群中Master故障后备用Master的启动问题。ZooKeeper也有可能发生故障,所以ZooKeeper也需要有集群。
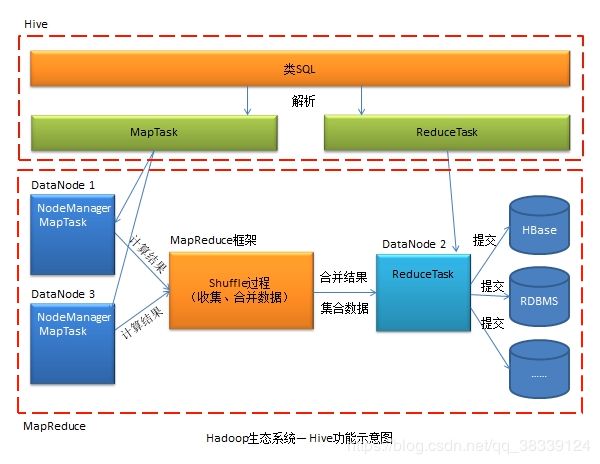
2.4.5Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
数据库中仅仅用于存放数据,而数据仓库则不仅可以存放数据,还可以根据数据进行决策支持、统计分析等。
2.4.6 HBase
HBase–Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是一个分布式的、面向列的开源数据库,该技术来源于Google论文“Bigtable”。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
使用Hive做相关数据查询,则需要对整个HDFS进行全盘扫描。若在HDFS之上再构建一层用于规划HDFS上的整个数据,那么将会大大提高数据检索效率。HBase就是构建于HDFS之上的数据库。注意,其不支持SQL语句,其以键值对的形式存放数据。有键就有索引,逵效率就会大大提高。