Spark自学之路(十三)——Spark 机器学习库
Spark 机器学习库MLlib
- Spark提供了一个基于海量数据的机器学习库,它提供了常用机器学习算法的分布式实现
- 开发者只需要有 Spark 基础并且了解机器学习算法的原理,以及方法相关参数的含义,就可以轻松的通过调用相应的 API 来实现基于海量数据的机器学习过程
- Spark-Shell的即席查询也是一个关键。算法工程师可以边写代码边运行,边看结果
- MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作 MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的工作流(Pipeline)API,具体如下:
算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
特征化工具:特征提取、转化、降维和选择工具;
工作流 (Pipeline):用于构建、评估和调整机器学习工作流的工具;
持久性:保存和加载算法、模型和管道;
实用工具:线性代数、统计、数据处理等工具。
Spark 机器学习库从1.2 版本以后被分为两个包:
- spark.mllib 包含基于RDD的原始算法API。Spark MLlib 历史比较长,在1.0 以前的版本即已经包含了,提供的算法实现都是基于原始的 RDD
- spark.ml 则提供了基于DataFrames 高层次的API,可以用来构建机器学习工作流(PipeLine)。ML Pipeline 弥补了原始 MLlib 库的不足,向用户提供了一个基于 DataFrame 的机器学习工作流式 API 套件
MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤:
机器学习工作流概念
在介绍工作流之前,先来了解几个重要概念:
DataFrame:使用Spark SQL中的DataFrame作为数据集,它可以容纳各种数据类型。较之RDD,DataFrame包含了schema 信息,更类似传统数据库中的二维表格。它被ML Pipeline用来存储源数据。例如,DataFrame中的列可以是存储的文本、特征向量、真实标签和预测的标签等
Transformer:翻译成转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。比如一个模型就是一个 Transformer。它可以把一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame
Estimator:翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。在 Pipeline 里通常是被用来操作 DataFrame 数据并生成一个 Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。比如,一个随机森林算法就是一个 Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。
Parameter:Parameter 被用来设置 Transformer 或者 Estimator 的参数。现在,所有转换器和估计器可共享用于指定参数的公共API。ParamMap是一组(参数,值)对
PipeLine:翻译为工作流或者管道。工作流将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出
构建一个工作流
要构建一个 Pipeline工作流,首先需要定义 Pipeline 中的各个工作流阶段PipelineStage(包括转换器和评估器),比如指标提取和转换模型训练等。有了这些处理特定问题的转换器和评估器,就可以按照具体的处理逻辑有序地组织PipelineStages 并创建一个Pipeline
然后就可以把训练数据集作为输入参数,调用 Pipeline 实例的 fit 方法来开始以流的方式来处理源训练数据。这个调用会返回一个 PipelineModel 类实例,进而被用来预测测试数据的标签
工作流的各个阶段按顺序运行,输入的DataFrame在它通过每个阶段时被转换:

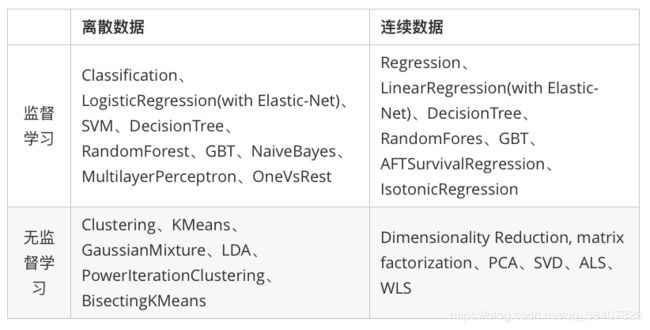
更具体的说,工作流的各个阶段按顺序运行,输入的DataFrame在它通过每个阶段时被转换。 对于Transformer阶段,在DataFrame上调用transform()方法。 对于估计器阶段,调用fit()方法来生成一个转换器(它成为PipelineModel的一部分或拟合的Pipeline),并且在DataFrame上调用该转换器的transform()方法。 上面,顶行表示具有三个阶段的流水线。 前两个(Tokenizer和HashingTF)是Transformers(蓝色),第三个(LogisticRegression)是Estimator(红色)。 底行表示流经管线的数据,其中圆柱表示DataFrames。 在原始DataFrame上调用Pipeline.fit()方法,它具有原始文本文档和标签。 Tokenizer.transform()方法将原始文本文档拆分为单词,向DataFrame添加一个带有单词的新列。 HashingTF.transform()方法将字列转换为特征向量,向这些向量添加一个新列到DataFrame。 现在,由于LogisticRegression是一个Estimator,Pipeline首先调用LogisticRegression.fit()产生一个LogisticRegressionModel。 如果流水线有更多的阶段,则在将DataFrame传递到下一个阶段之前,将在DataFrame上调用LogisticRegressionModel的transform()方法。
值得注意的是,工作流本身也可以看做是一个估计器。在工作流的fit()方法运行之后,它产生一个PipelineModel,它是一个Transformer。 这个管道模型将在测试数据的时候使用。 下图说明了这种用法。
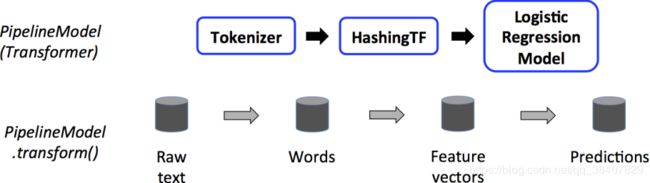
在上图中,PipelineModel具有与原始流水线相同的级数,但是原始流水线中的所有估计器都变为变换器。 当在测试数据集上调用PipelineModel的transform()方法时,数据按顺序通过拟合的工作流。 每个阶段的transform()方法更新数据集并将其传递到下一个阶段。工作流和工作流模型有助于确保培训和测试数据通过相同的特征处理步骤
例子:查找出所有包含"spark"的句子,即将包含"spark"的句子的标签设为1,没有"spark"的句子的标签设为0。
需要使用SparkSession对象 Spark2.0以上版本的spark-shell在启动时会自动创建一个名为spark的SparkSession对象,当需要手工创建时,SparkSession可以由其伴生对象的builder()方法创建出来。
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
# 从(id, text, label)元祖列表得到一个训练样本(DataFrame).
training = spark.createDataFrame([
(0, "a b c d e spark", 1.0),
(1, "b d", 0.0),
(2, "spark f g h", 1.0),
(3, "hadoop mapreduce", 0.0)
], ["id", "text", "label"])
# 配置 ML pipeline,包含三个阶段: tokenizer, hashingTF, 和 lr.
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.001)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
#现在构建的Pipeline本质上是一个Estimator,在它的fit()方法运行之后,它将产生一个PipelineModel,#它是一个Transformer。
# 使用训练样本建立模型.
model = pipeline.fit(training)
# 构建测试数据.
test = spark.createDataFrame([
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
], ["id", "text"])
# 调用之前训练好的PipelineModel的transform()方法,让测试数据按顺序通过拟合的工作流,生成预测结
#果
prediction = model.transform(test)
selected = prediction.select("id", "text", "probability", "prediction")
for row in selected.collect():
rid, text, prob, prediction = row
print("(%d, %s) --> prob=%s, prediction=%f" % (rid, text, str(prob), prediction))
#(4, spark i j k) --> prob=[0.1596407738787475,0.8403592261212525], #prediction=1.000000
#(5, l m n) --> prob=[0.8378325685476744,0.16216743145232562], prediction=0.000000
#(6, spark hadoop spark) --> prob=[0.06926633132976037,0.9307336686702395], #prediction=1.000000
#(7, apache hadoop) --> prob=[0.9821575333444218,0.01784246665557808],
#prediction=0.000000特征提取
TF-IDF (HashingTF and IDF)
“词频-逆向文件频率”(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
词语由t表示,文档由d表示,语料库由D表示。词频TF(t,d)是词语t在文档d中出现的次数。文件频率DF(t,D)是包含词语的文档的个数。如果我们只使用词频来衡量重要性,很容易过度强调在文档中经常出现,却没有太多实际信息的词语,比如“a”,“the”以及“of”。如果一个词语经常出现在语料库中,意味着它并不能很好的对文档进行区分。TF-IDF就是在数值化文档信息,衡量词语能提供多少信息以区分文档。其定义如下:
![]()
![]()
是语料库中总的文档数。公式中使用log函数,当词出现在所有文档中时,它的IDF值变为0。加1是为了避免分母为0的情况。TF-IDF 度量值表示如下:![]()
在Spark ML库中,TF-IDF被分成两部分:TF (+hashing) 和 IDF。
TF: HashingTF 是一个Transformer,在文本处理中,接收词条的集合然后把这些集合转化成固定长度的特征向量。这个算法在哈希的同时会统计各个词条的词频。
IDF: IDF是一个Estimator,在一个数据集上应用它的fit()方法,产生一个IDFModel。 该IDFModel 接收特征向量(由HashingTF产生),然后计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重。
Spark.mllib 中实现词频率统计使用特征hash的方式,原始特征通过hash函数,映射到一个索引值。后面只需要统计这些索引值的频率,就可以知道对应词的频率。这种方式避免设计一个全局1对1的词到索引的映射,这个映射在映射大量语料库时需要花费更长的时间。但需要注意,通过hash的方式可能会映射到同一个值的情况,即不同的原始特征通过Hash映射后是同一个值。为了降低这种情况出现的概率,我们只能对特征向量升维。i.e., 提高hash表的桶数,默认特征维度是 2^20 = 1,048,576.
在下面的代码段中,我们以一组句子开始。首先使用分解器Tokenizer把句子划分为单个词语。对每一个句子(词袋),我们使用HashingTF将句子转换为特征向量,最后使用IDF重新调整特征向量。这种转换通常可以提高使用文本特征的性能。
from pyspark.ml.feature import HashingTF, IDF, Tokenizer
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()
sentenceData = spark.createDataFrame([
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
], ["label", "sentence"])
#在得到文档集合后,即可用tokenizer对句子进行分词
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
#得到分词后的文档序列后,即可使用HashingTF的transform()方法把句子哈希成特征向量,这里设置哈希表的#桶数为2000。
wordsData = tokenizer.transform(sentenceData)
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20)
featurizedData = hashingTF.transform(wordsData)
#可以看到,分词序列被变换成一个稀疏特征向量,其中每个单词都被散列成了一个不同的索引值,特征向量在某
#一维度上的值即该词汇在文档中出现的次数。
#最后,使用IDF来对单纯的词频特征向量进行修正,使其更能体现不同词汇对文本的区别能力,IDF是一个#Estimator,调用fit()方法并将词频向量传入,即产生一个IDFModel。
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedData)
rescaledData = idfModel.transform(featurizedData)
rescaledData.select("label", "features").show()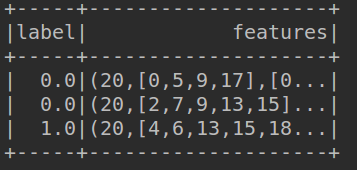
Word2Vec
是一种著名的 词嵌入(Word Embedding) 方法,它可以计算每个单词在其给定语料库环境下的 分布式词向量(Distributed Representation,亦直接被称为词向量)。词向量表示可以在一定程度上刻画每个单词的语义。
CountVectorizer
CountVectorizer旨在通过计数来将一个文档转换为向量。当不存在先验字典时,Countvectorizer作为Estimator提取词汇进行训练,并生成一个CountVectorizerModel用于存储相应的词汇向量空间。该模型产生文档关于词语的稀疏表示,其表示可以传递给其他算法,例如LDA。
特征变换
在机器学习处理过程中,为了方便相关算法的实现,经常需要把标签数据(一般是字符串)转化成整数索引,或是在计算结束后将整数索引还原为相应的标签。
Spark ML包中提供了几个相关的转换器,例如:StringIndexer、IndexToString、OneHotEncoder、VectorIndexer,它们提供了十分方便的特征转换功能,这些转换器类都位于org.apache.spark.ml.feature包下。
值得注意的是,用于特征转换的转换器和其他的机器学习算法一样,也属于ML Pipeline模型的一部分,可以用来构成机器学习流水线,以StringIndexer为例,其存储着进行标签数值化过程的相关 超参数,是一个Estimator,对其调用fit(..)方法即可生成相应的模型StringIndexerModel类,很显然,它存储了用于DataFrame进行相关处理的 参数,是一个Transformer(其他转换器也是同一原理)。
StringIndexer
StringIndexer转换器可以把一列类别型的特征(或标签)进行编码,使其数值化,索引的范围从0开始,该过程可以使得相应的特征索引化,使得某些无法接受类别型特征的算法可以使用,并提高诸如决策树等机器学习算法的效率。
索引构建的顺序为标签的频率,优先编码频率较大的标签,所以出现频率最高的标签为0号。
如果输入的是数值型的,我们会把它转化成字符型,然后再对其进行编码。
#首先,引入必要的包,并创建一个简单的DataFrame,它只包含一个id列和一个标签列category:
from pyspark.ml.feature import StringIndexer
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()
df = spark.createDataFrame(
[(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")],
["id", "category"])
#随后,我们创建一个StringIndexer对象,设定输入输出列名,其余参数采用默认值,并对这个DataFrame进行
#训练,产生StringIndexerModel对象:
indexer = StringIndexer(inputCol="category", outputCol="categoryIndex")
model = indexer.fit(df)
#随后即可利用该对象对DataFrame进行转换操作,可以看到,StringIndexerModel依次按照出现频率的高低,
#把字符标签进行了排序,即出现最多的“a”被编号成0,“c”为1,出现最少的“b”为0。
indexed = model.transform(df)
indexed.show()
+---+--------+-------------+
| id|category|categoryIndex|
+---+--------+-------------+
| 0| a| 0.0|
| 1| b| 2.0|
| 2| c| 1.0|
| 3| a| 0.0|
| 4| a| 0.0|
| 5| c| 1.0|
+---+--------+-------------+ IndexToString
StringIndexer相对应,IndexToString的作用是把标签索引的一列重新映射回原有的字符型标签。
其主要使用场景一般都是和StringIndexer配合,先用StringIndexer将标签转化成标签索引,进行模型训练,然后在预测标签的时候再把标签索引转化成原有的字符标签。当然,你也可以另外定义其他的标签。
首先,和StringIndexer的实验相同,我们用StringIndexer读取数据集中的“category”列,把字符型标签转化成标签索引,然后输出到“categoryIndex”列上,构建出新的DataFrame。
from pyspark.ml.feature import IndexToString, StringIndexer
from pyspark.sql import SparkSession
#首先,和StringIndexer的实验相同,我们用StringIndexer读取数据集中的“category”列,把字符型标签转
#化成标签索引,然后输出到“categoryIndex”列上,构建出新的DataFrame。
spark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()
df = spark.createDataFrame(
[(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")],
["id", "category"])
indexer = StringIndexer(inputCol="category", outputCol="categoryIndex")
model = indexer.fit(df)
indexed = model.transform(df)
#随后,创建IndexToString对象,读取“categoryIndex”上的标签索引,
# 获得原有数据集的字符型标签,然后再输出到“originalCategory”列上。
# 最后,通过输出“originalCategory”列,可以看到数据集中原有的字符标签。
converter = IndexToString(inputCol="categoryIndex", outputCol="originalCategory")
converted = converter.transform(indexed)
converted.select("id", "categoryIndex", "originalCategory").show()
+---+-------------+----------------+
| id|categoryIndex|originalCategory|
+---+-------------+----------------+
| 0| 0.0| a|
| 1| 2.0| b|
| 2| 1.0| c|
| 3| 0.0| a|
| 4| 0.0| a|
| 5| 1.0| c|
+---+-------------+----------------+OneHotEncoder
独热编码(One-Hot Encoding) 是指把一列类别性特征(或称名词性特征,nominal/categorical features)映射成一系列的二元连续特征的过程,原有的类别性特征有几种可能取值,这一特征就会被映射成几个二元连续特征,每一个特征代表一种取值,若该样本表现出该特征,则取1,否则取0。
One-Hot编码适合一些期望类别特征为连续特征的算法,比如说逻辑斯蒂回归等。
from pyspark.ml.feature import OneHotEncoder, StringIndexer
from pyspark.sql import SparkSession
#首先创建一个DataFrame,其包含一列类别性特征,需要注意的是
# ,在使用OneHotEncoder进行转换前,DataFrame需要先使用StringIndexer将原始标签数值化:
spark = SparkSession.builder.master("local[*]").appName("Word Count").getOrCreate()
df = spark.createDataFrame([
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c")
], ["id", "category"])
stringIndexer = StringIndexer(inputCol="category", outputCol="categoryIndex")
model = stringIndexer.fit(df)
indexed = model.transform(df)
#随后,我们创建OneHotEncoder对象对处理后的DataFrame进行编码,
# 可以看见,编码后的二进制特征呈稀疏向量形式,与StringIndexer编码的顺序相同,
# 需注意的是最后一个Category(”b”)被编码为全0向量,若希望”b”也占有一个二进制特征,
# 则可在创建OneHotEncoder时指定setDropLast(false)。
encoder = OneHotEncoder(inputCol="categoryIndex", outputCol="categoryVec")
encoded = encoder.transform(indexed)
encoded.show()
+---+--------+-------------+-------------+
| id|category|categoryIndex| categoryVec|
+---+--------+-------------+-------------+
| 0| a| 0.0|(2,[0],[1.0])|
| 1| b| 2.0| (2,[],[])|
| 2| c| 1.0|(2,[1],[1.0])|
| 3| a| 0.0|(2,[0],[1.0])|
| 4| a| 0.0|(2,[0],[1.0])|
| 5| c| 1.0|(2,[1],[1.0])|
+---+--------+-------------+-------------+VectorIndexer
之前介绍的StringIndexer是针对单个类别型特征进行转换,倘若所有特征都已经被组织在一个向量中,又想对其中某些单个分量进行处理时,Spark ML提供了VectorIndexer类来解决向量数据集中的类别性特征转换。
通过为其提供maxCategories超参数,它可以自动识别哪些特征是类别型的,并且将原始值转换为类别索引。它基于不同特征值的数量来识别哪些特征需要被类别化,那些取值可能性最多不超过maxCategories的特征需要会被认为是类别型的。
#我们读入一个数据集,然后使用VectorIndexer训练出模型,
# 来决定哪些特征需要被作为类别特征,将类别特征转换为索引,
# 这里设置maxCategories为10,即只有种类小10的特征才被认为是类别型特征,
# 否则被认为是连续型特征:
from pyspark.ml.feature import VectorIndexer
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()
data = spark.read.format('libsvm').load('file:///usr/local/spark/data/mllib/sample_libsvm_data.txt')
indexer = VectorIndexer(inputCol="features", outputCol="indexed", maxCategories=10)
indexerModel = indexer.fit(data)
categoricalFeatures = indexerModel.categoryMaps
indexedData = indexerModel.transform(data)
indexedData.show()
+-----+--------------------+--------------------+
|label| features| indexed|
+-----+--------------------+--------------------+
| 0.0|(692,[127,128,129...|(692,[127,128,129...|
| 1.0|(692,[158,159,160...|(692,[158,159,160...|
| 1.0|(692,[124,125,126...|(692,[124,125,126...|
| 1.0|(692,[152,153,154...|(692,[152,153,154...|
| 1.0|(692,[151,152,153...|(692,[151,152,153...|
| 0.0|(692,[129,130,131...|(692,[129,130,131...|
| 1.0|(692,[158,159,160...|(692,[158,159,160...|
| 1.0|(692,[99,100,101,...|(692,[99,100,101,...|
| 0.0|(692,[154,155,156...|(692,[154,155,156...|
| 0.0|(692,[127,128,129...|(692,[127,128,129...|
| 1.0|(692,[154,155,156...|(692,[154,155,156...|
| 0.0|(692,[153,154,155...|(692,[153,154,155...|
| 0.0|(692,[151,152,153...|(692,[151,152,153...|
| 1.0|(692,[129,130,131...|(692,[129,130,131...|
| 0.0|(692,[154,155,156...|(692,[154,155,156...|
| 1.0|(692,[150,151,152...|(692,[150,151,152...|
| 0.0|(692,[124,125,126...|(692,[124,125,126...|
| 0.0|(692,[152,153,154...|(692,[152,153,154...|
| 1.0|(692,[97,98,99,12...|(692,[97,98,99,12...|
| 1.0|(692,[124,125,126...|(692,[124,125,126...|
+-----+--------------------+--------------------+特征选择
特征选择(Feature Selection)指的是在特征向量中选择出那些“优秀”的特征,组成新的、更“精简”的特征向量的过程。它在高维数据分析中十分常用,可以剔除掉“冗余”和“无关”的特征,提升学习器的性能。
特征选择方法和分类方法一样,也主要分为有监督(Supervised)和无监督(Unsupervised)两种,卡方选择则是统计学上常用的一种有监督特征选择方法,它通过对特征和真实标签之间进行卡方检验,来判断该特征和真实标签的关联程度,进而确定是否对其进行选择。
和ML库中的大多数学习方法一样,ML中的卡方选择也是以estimator+transformer的形式出现的,其主要由ChiSqSelector和ChiSqSelectorModel两个类来实现。
from pyspark.ml.feature import ChiSqSelector
from pyspark.ml.linalg import Vectors
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()
df = spark.createDataFrame([
(7, Vectors.dense([0.0, 0.0, 18.0, 1.0]), 1.0,),
(8, Vectors.dense([0.0, 1.0, 12.0, 0.0]), 0.0,),
(9, Vectors.dense([1.0, 0.0, 15.0, 0.1]), 0.0,)], ["id", "features", "clicked"])
selector = ChiSqSelector(numTopFeatures=1, featuresCol="features",
outputCol="selectedFeatures", labelCol="clicked")
result = selector.fit(df).transform(df)
result.show()
+---+------------------+-------+----------------+
| id| features|clicked|selectedFeatures|
+---+------------------+-------+----------------+
| 7|[0.0,0.0,18.0,1.0]| 1.0| [18.0]|
| 8|[0.0,1.0,12.0,0.0]| 0.0| [12.0]|
| 9|[1.0,0.0,15.0,0.1]| 0.0| [15.0]|
+---+------------------+-------+----------------+