jsoup+Java多线程爬虫-Lv1.0
刚刚接触爬虫这个领域,使用Java+jsoup写了一个简单的网络爬虫。就是直接从网站上爬取文本信息,原理也没有那么复杂。
这里用到了jsoup,是一个Java的HTML解析器,可以直接去解析URL或者HTML文本。可以通过DOM和CSS选择器等方法去提取和操作数据。有关jsoup就不做过多介绍,解析HTML文本用的都是基础操作,感兴趣的话也可以自己去学习。
要爬取的网页是:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2017/index.html,这里展示的是国家统计局2017年的城乡划分的结果,网站的主页面如下:
爬取思路
首先明确最终的目的:爬取这个网站上所有地区的文本信息并打印到控制台上。
流程图大致是这样的:
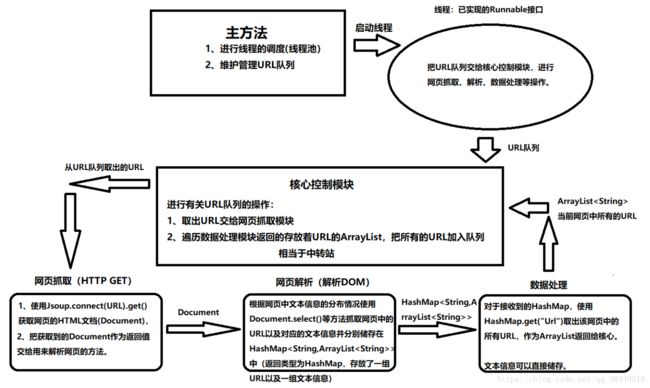
现在说明一下各个逻辑的实现:
1、首先要对爬取的网站有足够的了解,这个网页的大致情况是这样的:
(1):除了最后一层网页只有文本信息以外,其余的网页都是一条文本信息对应一个文本信息对应一个URL地址的
(2):除了最后一层之外,每一层的数字和文本信息对应的URL是相同的
(3):所有的URL地址都是相对地址
(4):我们不需要数字文本,必须把数字文本剔除掉

2、知道了网页的信息之后,开始写代码,项目结构图是这样的(面向对象思想)

导入jsoup依赖:
org.jsoup
jsoup
1.11.3
3、主方法(WormMain)
package root.InternetWorm;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
public class WormMain {
//待抓取的Url队列,全局共享
public static final LinkedBlockingQueue UrlQueue = new LinkedBlockingQueue<>();
public static final WormCore wormCore = new WormCore();
public static void main(String[] args) {
//要抓取的根URL
String rootUrl = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2017/61.html";
//先把根URL加入URL队列
UrlQueue.offer(rootUrl);
Runnable runnable = new MyRunnable();
//开启固定大小的线程池,爬取的过程由10个线程完成
ExecutorService Fixed = Executors.newFixedThreadPool(10);
//开始爬取
for (int i = 0;i < 10;i++){
Fixed.submit(runnable);
}
//关闭线程池
Fixed.shutdown();
}
} 主方法中定义全局共享的URL队列,同时定义Runnable实现类所要使用的核心控制模块(WormCore)类的对象,使用线程池进行线程的调度管理,以及根URL的定义以及入队列操作
4、Runnable实现类:
package root.InternetWorm;
import java.io.IOException;
import static root.InternetWorm.WormMain.UrlQueue;
import static root.InternetWorm.WormMain.wormCore;
class MyRunnable implements Runnable {
@Override
public void run() {
while (true) {
try {
Thread.sleep(200);
//把主方法中的URL队列传给核心控制类,开始该线程的爬取
wormCore.Wormcore(UrlQueue);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
}这个实现类使线程不停的调用核心控制类的方法,就是不停的进行爬取操作,有关加锁的操作放在了核心控制类中。
5、核心控制类(WormCore)
package root.InternetWorm;
import org.jsoup.nodes.Document;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.concurrent.LinkedBlockingQueue;
public class WormCore {
//Document获取层对象
private volatile Catch Catch = new Catch();
//Document解析层对象
private volatile Analysis analysis = new Analysis();
//数据处理层对象
public volatile Access access = new Access();
public void Wormcore(LinkedBlockingQueue UrlQueue) throws IOException, InterruptedException {
synchronized (this) {
if (!UrlQueue.isEmpty()) {
String Url = UrlQueue.take();
//通过Url队列中的Url抓取Document,进行Url和文本信息的抓取
Document document = Catch.CatchDocument(Url);
//数据解析模块返回的数据(含有文本信息以及URL)
HashMap> DataMap = analysis.AnalysisDocument(document, Url);
//数据处理模块分离出的、只含有URL的集合
ArrayList UrlList = access.DataAccess(DataMap);
//定义迭代器,把抓取到的Url添加到Url队列中
Iterator iterator = UrlList.iterator();
while (iterator.hasNext()) {
UrlQueue.put(iterator.next());
}
//打印URL队列中的URL条数以及队列是否为空
System.out.println(UrlQueue.size());
System.out.println(UrlQueue.isEmpty());
//为空说明爬取完毕,由于个人技术问题,在抓取完毕之后只能强制退出
if (UrlQueue.isEmpty()) {
System.out.println("抓取完毕!");
System.exit(1);
}
}
}
}
}
这段代码实现了:
1、把URL队列的队首弹出交给网页抓取模块获取Document
2、把Document交给网页解析模块获取文本/URL信息
3、把信息的Map交给数据处理模块获取网页中所有的URL并再加入URL队列
由于使用的是广度优先搜索,所以当URL队列为空的时候就说明已经爬取完了
6、网页抓取(CatchDocument):
package root.InternetWorm;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
import java.net.SocketTimeoutException;
public class Catch {
//根据网页的Url获取网页Document
public Document CatchDocument(String Url) throws IOException {
try {
return Jsoup.connect(Url)
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)").timeout(5000).get();
//如果出现了超时问题就继续抓取
}catch (SocketTimeoutException s){
return Jsoup.connect(Url)
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)").timeout(5000).get();
}
}
}根据核心控制类传来的URL获取Document并返回,注意设置超时时间以及如果超时之后的操作
7、网页解析:
package root.InternetWorm;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.HashMap;
import static root.InternetWorm.Util.IsNumber;
public class Analysis {
//根据Document解析网页
public HashMap> AnalysisDocument(Document document, String Url){
//因为网页上的URL为相对地址,所以在这里进行URL的拼接,这是前半部分
String Before_Url = Url.substring(0, Url.lastIndexOf("/") + 1);
//储存文本信息的List
ArrayList Text = new ArrayList<>();
//储存Url的List
ArrayList Urls = new ArrayList<>();
HashMap> Message = new HashMap<>();
//最后一个页面的前三个文本不是我们想要的
int Flag = 1;
Elements elements = document.select("tr[class]").select("a[href]");
//最后一个页面的处理
if(elements.isEmpty()){
elements = document.select("tr[class]").select("td");
for (Element element : elements) {
if (!IsNumber(element.text()) && Flag > 3) {
System.out.println(element.text());
}
Flag++;
}
//普通页面的处理
}else {
for (Element element : elements) {
if (!IsNumber(element.text())) {
Text.add(element.text());
System.out.println(element.text());
Urls.add(Before_Url + element.attr("href"));
}
}
}
//把文本集合和URL集合装到Map中返回
Message.put("text",Text);
Message.put("Url",Urls);
return Message;
}
} 因为最后一个页面和前几个页面是不一样的,所以在这里就要对不同的页面有不同的解析方式。因为我们不需要数字文本信息,所以使用IsNumber()方法来剔除数字文本(自己实现的数字字符串检验方法)
相对路径和绝对路径的问题:虽然可以使用element.attr("abs:href")来直接获取绝对地址,但是,如果要把Document存到本地的话这个方法就没有用了,所以为了以后项目的扩展性,我还是采用了URL拼接的方法来获取绝对地址。
8、数据处理:
package root.InternetWorm;
import java.util.ArrayList;
import java.util.HashMap;
public class Access {
//数据处理,把信息中的Url返回给核心,文本信息储存
public ArrayList DataAccess(HashMap> Message){
return Message.get("Url");
}
}
这里的操作很简单:把HashMap中保存URL的集合提取出来保存就可以了,文本信息可以进行保存。
因为实现效率以及网络原因,爬取全国的地区信息大致需要1小时左右,所以先爬取了陕西省的信息作为演示,后续我会完善这个项目
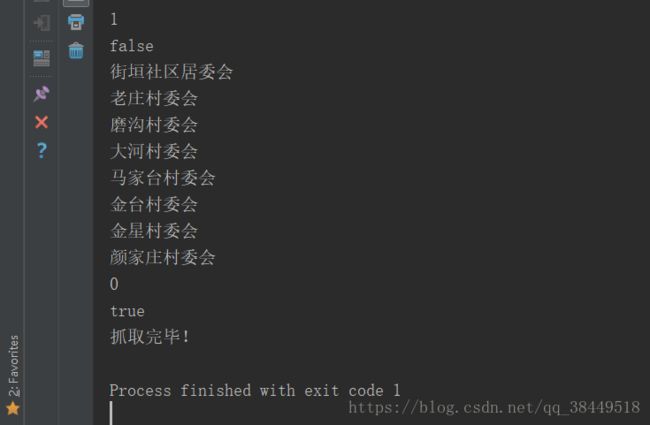
数据处理方面没有写的太多,只是打印到控制台了,后面我会补上这段代码
仅供个人学习使用,希望大家可以给出好的建议。