shell编程05【自定义函数和高级命令】
自定函数
语法
linux shell 可以用户定义函数,然后在shell脚本中可以随便调用。shell中函数的定义格式如下
[ function ] funname [()]
{
action;
[return int;]
}
注意
- 必须在调用函数地方之前,先声明函数,shell脚本是逐行运行。不会像其它语言一样先预编译
- 函数返回值,只能通过$? 系统变量获得,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255)
实例
#!/bin/bash
fSum 2 3
function fSum()
{
echo $1,$2
return $(($1+S2))
}
fSum 5 7
total=$?
echo $total,$?
输出
[root@hadoop-node01 ~]# . fun1.sh
2,3
5,7
5,0
脚本调试
sh -vx fun1.sh
[root@hadoop-node01 ~]# sh -vx fun1.sh
#!/bin/bash
fSum 2 3
+ fSum 2 3
fun1.sh: line 2: fSum: command not found
function fSum()
{
echo $1,$2
return $(($1+S2))
}
fSum 5 7
+ fSum 5 7
+ echo 5,7
5,7
+ return 5
total=$?
+ total=5
echo $total,$?
+ echo 5,0
5,0
高级命令
| 序号 | 命令 | 说明 |
|---|---|---|
| 1 | cut | 从一个文本文件或者文本流中提取文本列 |
| 2 | sort | 对 File 参数指定的文件中的行排序 |
| 3 | uniq | 可以去除排序过的文件中的重复行 |
| 4 | wc | 计算文件的Byte数、字数或是列数 |
| 5 | sed | 流编辑器,不改变原有内容,加载到临时缓冲区中编辑,然后将结果输出 |
| 6 | awk | 编程语言 |
cut
cut语法
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
![]()
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/rvm/bin:/usr/local/jdk8/bin:/root/apps/redis-5.0.3/src:/root/apps/zookeeper/bin:/root/bin
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11
案例
- 将 PATH 变量取出,我要找出第五个路径。
[root@hadoop-node01 ~]# echo $PATH | cut -d ':' -f 5
/usr/sbin
- 将 PATH 变量取出,我要找出第三和第五个路径。
[root@hadoop-node01 ~]# echo $PATH | cut -d ':' -f 3,5
/sbin:/usr/sbin
- 将 PATH 变量取出,我要找出第三到最后一个路径。
[root@hadoop-node01 ~]# echo $PATH | cut -d ':' -f 3-
/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/rvm/bin:/usr/local/jdk8/bin:/root/apps/redis-5.0.3
/src:/root/apps/zookeeper/bin:/root/bin
- 将 PATH 变量取出,我要找出第一到第三个路径。
[root@hadoop-node01 ~]# echo $PATH | cut -d ':' -f 1-3
/usr/local/sbin:/usr/local/bin:/sbin
- 将 PATH 变量取出,我要找出第一到第三,还有第五个路径。
[root@hadoop-node01 ~]# echo $PATH | cut -d ':' -f 1-3,5
/usr/local/sbin:/usr/local/bin:/sbin:/usr/sbin
sort
命令对 File 参数指定的文件中的行排序
| 参数 | 说明 |
|---|---|
| -b: | 忽略每行前面开始出的空格字符; |
| -c: | 检查文件是否已经按照顺序排序; |
| -d: | 排序时,处理英文字母、数字及空格字符外,忽略其他的字符; |
| -f: | 排序时,将小写字母视为大写字母; |
| -i: | 排序时,除了040至176之间的ASCII字符外,忽略其他的字符; |
| -m: | 将几个排序号的文件进行合并; |
| -M: | 将前面3个字母依照月份的缩写进行排序; |
| -n: | 依照数值的大小排序; |
| -o<输出文件>: | 将排序后的结果存入制定的文件; |
| -r: | 以相反的顺序来排序; |
| -t<分隔字符>: | 指定排序时所用的栏位分隔字符; |
| +<起始栏位>- <结束栏位>: |
以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。 |
举例:对/etc/passwd 的账号进行排序
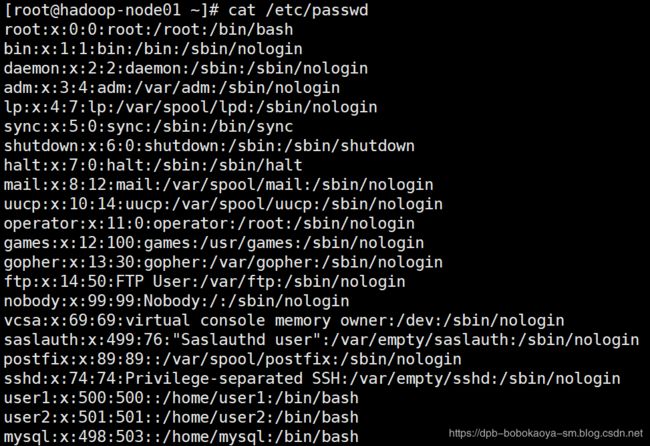
默认按照首字母排序
cat /etc/passwd | sort
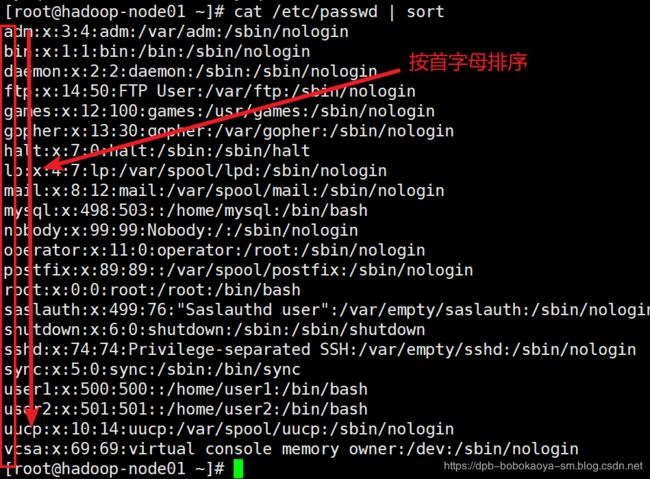
按照":"分隔符分割排序,
cat /etc/passwd | sort -t ':' -k 3
按照":"分割,-k 3 表示按照第三个分割的字符排序,默认是数据字典排序
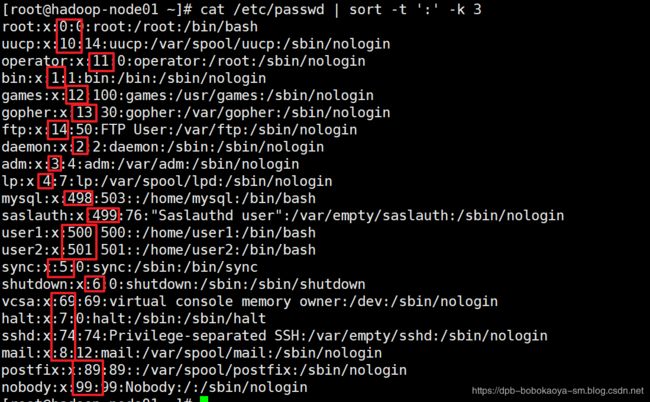
cat /etc/passwd | sort -t ':' -k 3n

排序默认是升序,降序排序加’r’
cat /etc/passwd | sort -t ':' -k 3nr
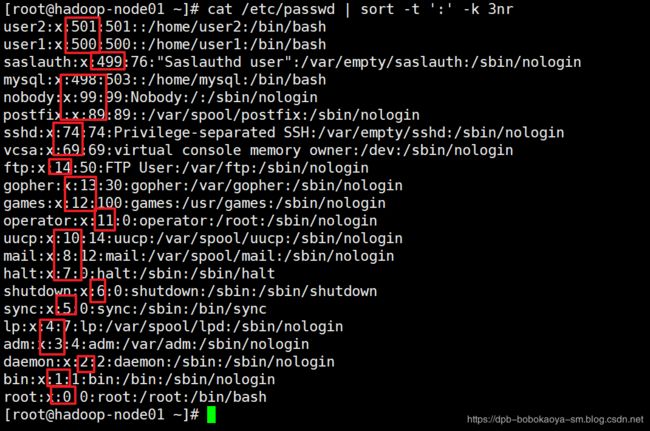
uniq
可以去除排序过的文件中的重复行
| 参数 | 说明 |
|---|---|
| -c 或 --count | 在每列旁边显示该行重复出现的次数; |
| -d 或 --repeated | 仅显示重复出现的行列; |
| -f<栏位> 或 --skip -fields=<栏位> | 忽略比较指定的栏位; |
| -s<字符位置> 或 --skip-chars=<字符位置> | 忽略比较指定的字符; |
| -u 或 --unique | 仅显示出一次的行列; |
| -w<字符位置> 或 --check-chars=<字符位置> | 指定要比较的字符。 |
准备数据
[root@hadoop-node01 ~]# vim a.txt
[root@hadoop-node01 ~]# cat a.txt
hello
java
name
java
php
spring
shell
shell
spring
springmvc
mybatis
hello
ajax
排序并去重
cat a.txt | sort | uniq
[root@hadoop-node01 ~]# cat a.txt | sort | uniq
ajax
hello
java
mybatis
name
php
shell
spring
springmvc
统计各行在文件中出现的次数:
sort a.txt | uniq -c
[root@hadoop-node01 ~]# sort a.txt | uniq -c
1 ajax
2 hello
2 java
1 mybatis
1 name
1 php
2 shell
2 spring
1 springmvc
在文件中找出重复的行:
sort a.txt | uniq -d
[root@hadoop-node01 ~]# sort a.txt | uniq -d
hello
java
shell
spring
wc
wc命令用来计算数字。利用wc指令我们可以计算文件的Byte数、字数或是列数
| 参数 | 说明 |
|---|---|
| -c或–bytes或 --chars | 只显示Bytes数; |
| -l或 --lines | 只显示列数; |
| -w或 --words | 只显示字数。 |
[root@hadoop-node01 ~]# wc -c /etc/passwd
973 /etc/passwd
[root@hadoop-node01 ~]# wc --bytes /etc/passwd
973 /etc/passwd
[root@hadoop-node01 ~]# wc --chars /etc/passwd
973 /etc/passwd
[root@hadoop-node01 ~]# wc -l /etc/passwd
22 /etc/passwd
[root@hadoop-node01 ~]# wc -w /etc/passwd
28 /etc/passwd
sed
sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
http://man.linuxde.net/sed
将文本的内容处理后显示在屏幕上,不会影响原来的数据
准备数据:
[root@hadoop-node01 ~]# cat sed.txt
aaa
bbb
ccc
在显示数据的最后一行追加一条记录
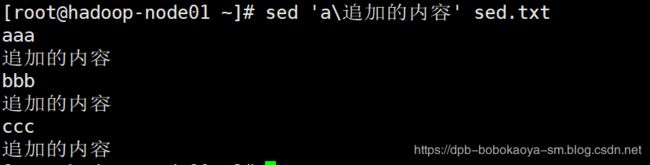
将内容中的aaa替换我haha

显示的数据删除第二行

awk
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势
http://man.linuxde.net/awk