使用CentOS6.8搭建Hadoop集群
概述:
集群cluster,能将很多进程分布到多台计算机上;通过联合使用多台计算机的存储、计算资源完成更庞大的任务。
为了实现无限量的存储和计算能力,在生产环境中必须使用集群来满足需求。
注意事项:
1)集群中的计算机在时间上要同步,系统时间不能差太多(约30秒内),如果设置时间后重启时间又不准确了(可能是主板电池老化),可以启用NTP(Network Time Protocol网络时间协议)服务解决(CentOS7安装时就可以设置自动同步)。
2)集群中的计算机在网络上能够相互访问
i.虚拟机的网络使用NAT模式
ii.固定IP,要规划好IP地址和主机名()
iii.全部关闭防火墙
iv.全部实现Hosts解析
v.全部实现免密码SSH访问(可以统一密钥对)
-.NameNode-对应的是-master、DataNode-对应的是-slave
--前提:安装三个虚拟机(内存最好在8~13G),分别作为master、slave1、slave2
记住三个虚拟机的名字和IP
1.安装JDK
如果安装的是minimal(最小版),跳过卸载直接去下载安装,如果安装的不是minimal(最小版),那么你需要卸除原有的JDK。
1.1卸载非LinuxJDK
卸载OpenJDK(最小化安装不带Open JDK)
Gnome桌面版自带OpenJDK,OpenJDK是JDK的一个开源实现
与Oracle官方JDK相似度近95%,一般情况下可以使用
但大数据的Hadoop不支持OpenJDK
通过rpm查找jdk和java的安装信息
rpm是RedHat包管理器,包管理器能够管理应用的安装卸载
类似于Maven管理Jar包
rpm -qa | grep jdk
java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
卸载
对于如上的每一行输出,都调用rpm -e --nodeps,如(:
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
-e 表示卸载
--nodeps 表示不考虑是否有依赖问题,强制卸载
1.2下载:
上浏览器上下载linuxJDK压缩包(搜索Linux JDK 64)
提示路径:http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-x64.tar.gz
或者温馨jdk链接:https://pan.baidu.com/s/1Yg7Nwp-JQSC7eNDDe2uaaA 提取码:mjnk
1.3:将JDK压缩包上传到虚拟机的 ~/
解压提取 tar zxvf jdk….tar.gz
将得到的jdk1.8…移动到/usr/local/中
mv jdk1.8…/ /usr/local/jdk
1.4配置环境变量
vi /etc/profile
在/etc/profile的最后添加如下内容
#JDK1.8
JAVA_HOME=/usr/local/jdk
JRE_HOME=/usr/local/jdk/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASSPATH PATH
保存(i 进入编辑模式 ESC 退出编译模式 :wq 保存并退出 :q! 退出不保存)
然后刷新环境变量
source /etc/profile
注意:上面的环境变量JAVA_HOME=这边填写的是你JDK的位置(路径)
------测试JDK安装是否成功
java -version
----------------------------安装Hadoop---------------------
1.安装Hadoop
到Hadoop官方下载 hadoop-xxx.tar.gz(选择稳定版)
温馨Hadoop链接:https://pan.baidu.com/s/1uAfgrBQaz6ST7_iPl4tcTw 提取码:cn8w (本版本2.7.5)
上传到master虚拟机上的 ~/
解压提取 tar zxvf hadoop-xxx.tar.gz
将得到的hadoop-xxx…移动到/usr/local/hadoop中(可以不移动,但是在配置关于路径的配置文件时,注意路径)
2.配置Hadoop
打开 vi /etc/profile,在最后添加
#Hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH执行source /etc/hadoop更新环境变量
-------------
3.关于搭建Hadoop集群的配置
首先--进入/usr/local/hadoop/etc/hadoop
1.打开hadoop-env.sh指定JDK位置
# The java implementation to use.
export JAVA_HOME=JDK位置2.打开core-site.xml指定NameNode
fs.defaultFS
hdfs://master:9000
--master:表示NameNode(根据自己的master名字自己改变),9000:表示端口号(不用改变就行)
3.打开hdfs-site.xml指定SecondaryNameNode,关闭权限检查
dfs.namenode.secondary.http-address
hdfs://master:50090
dfs.permissions.enabled
false
-----------这里的master与上面的意思一样
4.打开slaves文件,指定担任DataNode的主机
master #让master同时成为datanode,生产环境不需要!
slave1
slave2
Slaves文件的作用是当使用start-dfs.sh启动HDFS时,会自动将各个datanode节点自动启动起来。
5.vi /etc/hosts
Hosts的作用是可以在网络使用名字替换IP地址,添加文件内容如下:
192.168.2.10 master
192.168.2.11 slaves1
192.168.2.12 slaves2
6.将master的/etc/hosts分发到各个节点(master是根节点)
再分发之前安装scp(每个节点都要安装),如果不安装会出现以下错误
结果提示:
-bash: scp: command not found想当然用yum install scp命令安装,
结果提示:
No package scp available.后来发现scp这东西应该属于openssh-clients这个包,
运行:
yum -y install openssh-clients (注:两台机器都需要安装)
--现在发布
scp /etc/hosts root@slaveXX :/etc/hosts
注意slaveXX表示slave1、slave2…,每个节点都要分发
7.节点直接免密登录
---------在NameNode(master)上使用ssh-keygen命令生成密钥对(可以不看)
1.先运行一下ssh命令,查看是否能用
ssh
2.生成密钥对(一路回车,如果已经有了,直接使用现有的)
ssh-keygen
3.(介绍)生成的密钥对在~/.ssh中,分别是:
id_rsa #私钥
id_rsa.pub #公钥~
4.发送公钥使之免密码
在NameNode上将本地的公钥发送给所有节点(包括自己),之后就可以不用输入密码登陆
ssh-copy-id slaveXX
注意slaveXX表示master、slave1、slave2…
5.发布配置到DataNode(slave),这样就可以不用配置和安装JDK与Hadoop--------
分发JDK
scp -r /usr/local/jdk root@slaveXX:/usr/local
分发Hadoop
scp -r /usr/local/hadoop root@slaveXX:/usr/local
分发/etc/profile
scp /etc/profile root@slaveXX:/etc/
注意要在每个节点上执行source /etc/profile
--------------------启动--------------------------
1.格式化(初始化)
在namenode上运行
hdfs namenode -format
--注意:每次格式化,都会在每个节点上(包括自己)的/tmp/中创建 hadoop-root
重启再格式化
stop-all.sh关闭
start-all.sh开启
2.启动
在namenode上运行
start-dfs.sh
----检查启动结果

【1】用JPS查看Java进程

NameNode #NameNode启动了,NameNode上要有此进程
DataNode #DataNode启动了,DataNode上要有此进程
SecondaryNameNode #SecondaryNameNode启动了
#这个是SecondaryNameNode上的辅助进程
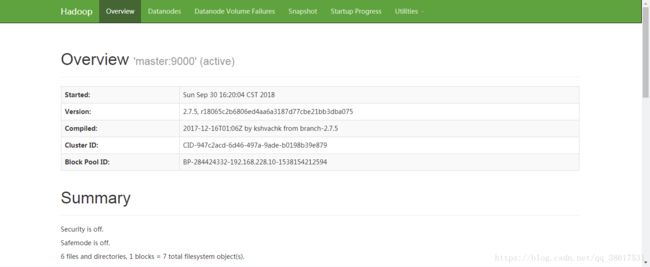
【2】用master(或者master的IP):50070查看Hadoop站点,检查各个节点是否启动,如下图
【3】用命令测试,检查HDFS是否工作正常
hdfs dfs -mkdir /abc
hdfs dfs -ls /
-----------------------------温馨提示-------------------------------
1.查看及修改主机名
1.1查看主机名
hostname
1.2修改主机名(通常不需要)
vi /etc/sysconfig/network内容如下,HOSTNAME对应的就是主机名
NETWORKING=yes
HOSTNAME=s1
---上面操作之后,重启Linux
reboot
2.重启网络服务
service network restart
3.网络时间同步
3.1下载ntpdate
yum -y install ntpdate
3.2同步时间
ntpdate ntp.api.bz
4..启动出现节点缺少进程,查看日志,看是否格式化成功。如果格式化没有成功
每个节点上先执行 rm -rf /tmp/hadoop-root 再次格式化
检查配置文件,防火墙,时间是否一致
然后再次格式化,不允许连续格式化两次