2018 CVPR Partially Shared Multi-Task Convolutional Neural Network with Local Constraint 学习
具有局部约束的部分共享多任务卷积神经网络用于人脸属性学习
摘要
在本文中,我们通过同时考虑身份信息和属性关系来研究面部属性学习问题。尤其是,
我们首先介绍一个部分共享的多任务卷积神经网络(PS-MCNN),其中四个任务专用网络(TSNets)和一个共享网络(SNet)通过部分共享(PS)结构连接,以学习更好的共享和任务特定表示。为了利用身份信息来进一步提高性能,我们引入了局部学习约束,该约束最小化了每个样本的表示与具有相同身份的本地几何邻域之间的差异。 因此,我们提出了局部约束正则化多任务网络,称为局部约束的部分共享多任务卷积神经网络(PS-MCNNLC),其中集成了PS结构和局部约束来一起帮助框架学习更好的属性表示。CelebA和LFWA的实验结果证明了所提方法的前景。
1 介绍
面部属性学习[26,1,2,30,37,8,18,9]在许多现实世界的应用中引起了很多关注,如面部识别和验证[33,23,32,34,27]。 它旨在学习中级表示作为低级功能和高级标签之间的抽象。 然而,大规模的面部属性学习仍然是一个非常具有挑战性的问题,因为在野外捕获的面部通常受到诸如照明,姿势和表情等因素的变化的影响。
1.1
由于卷积神经网络(CNN)的成功[16,35,31,6,24,10,11],深度CNN表示已被广泛用于面部属性学习。 例如,Razavian等。 利用面孔通过识别网络提取面部特征,然后训练SVM进行属性分类[30]。 此外,Hand和Chellappa考虑利用属性相关性为属性分类构建可靠的深层体系结构 特别是,多任务深度CNN(MCNN)是通过共享所有属性的较低层网络并共享较高层来实现密切相关的。
属性通过拆分结构。 基于许多属性强相关的假设,MCNN将所有40个属性划分为9个属性组,以便类似的属性在组内,并且为每个组独立地学习高级特征。
虽然MCNN通过利用属性的补充信息已经成为最先进的性能,但是不同组之间的交互受到限制,因为它们在分裂后是独立的。 当组到达MCNN的高层时,组中消失的共享信息就会出现。 因此,属性组难以有效地利用该属性
从网络开始到结束的相关性,以提升整体表现。 从多任务学习的角度来看,有必要学习整个网络中的组(任务)之间的共享特征来建模
复杂的属性关系。 此外,MCNN忽略样本的身份信息,这意味着它们的相互依赖性并编码局部几何结构。由于这种局部结构通常有助于特征学习,忽略身份信息的现有属性学习方法可能不合适。
在本文中,我们以同时考虑身份信息和属性关系的新视角研究了多任务人脸属性学习问题。 我们假设结合身份信息和任务关系建模使我们能够开发更准确的多任务属性学习算法。 我们的假设基于两个见解:(1)有效的相互作用在不同的属性组(任务)之间帮助导致更准确的属性关系建模; (2)信息性身份标签通过建模属性学习的局部几何结构,进一步帮助提高性能。
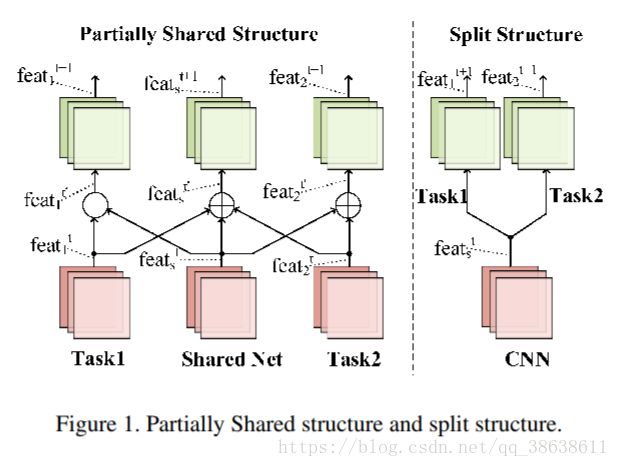
2.1分体式结构
首先,我们提出了一种新颖的部分共享多任务卷积神经网络(PS-MCNN),其中任务关系由共享网络(SNet)捕获,并且任务特定网络(TSNets)捕获不同任务之间的可变性。与MCNN类似,根据空间信息将所有属性分成若干组,然后可以考虑每组的分类学习
作为一项个人任务。 PS-MCNN的关键思想在于为所有组共享一个公共网络,以学习共享功能,并构建特定于组的网络。
从架构的开始到结束的每个组都要学习任务特定的功能,这使得它与现有的MCNN不同,后者在低级层学习共享功能,同时在高级层学习任务特定功能。这种多任务学习方式有助于有效地利用来自不同任务的补充信息,同时最大限度地保留特定的特定信息
任务。图1给出了两个结构示例,以显示PS-MCNN和MCNN的相应策略。
2.2。 部分共享结构
为了克服分裂结构的上述局限性,我们提出了一种称为部分共享(PS)结构的新型网络结构,用于多任务学习。 PS结构
由两种类型的网络组成:任务特定网络(TSNet)和共享网络(SNet)。 TSNet专注于学习特定任务的功能,而SNet则学习为每项任务共享的信息表示。 SNet通过简单的连接模式与每个TSNet交互:为了确保SNet和TSNet层之间的最大信息流,我们将TSNet层与SNet层连接起来。 SNet的每一层都从前一层TSNet获得额外的输入,并将自己的特征映射传递给下一层共享和任务
特定网络。 如图1所示,信息流可以表述如下:
2.3。 部分共享的多任务卷积神经网络
基于所提出的PS结构,我们引入了一种新的部分共享多任务卷积神经网络(PS-MCNN)用于人脸属性学习。 与MCNN类似,我们将所有40个属性分成四个属性组,包括Upper,Middle,Lower和Whole Image,根据它们的相应位置。 然后,可以将每个组的属性分类视为单独的属性学习任务。 下面列出了详细的组配置。
上组:弓形眉毛,眼袋,秃头,刘海,黑头发,金色头发,棕色头发,浓密眉毛,眼镜,灰色头发,窄眼,后退发际线,戴帽子。
中间组:大鼻子,高颧骨,尖尖的鼻子,玫瑰色的脸颊,Side角,戴着耳环。
下组:大嘴唇,双下巴,山羊胡,小胡子,嘴微微打开,没有胡子,戴口红,戴项链,戴领带。
整个图像组:5点钟阴影,有吸引力,模糊,胖乎乎的,重妆,男性,椭圆形脸,苍白的皮肤,直发,微笑,波浪形的头发,年轻。图2显示了PS-MCNN的架构,其中四个TSNets 被利用用于四个相应的属性组以学习任务特定的特征并且构造一个SNet
用于共享表示学习。 同时,TSNets和SNet通过每个深度的PS结构连接,以便更好地在不同任务之间进行交互。
2.4。 设计决策
为了充分利用PS-MCNN在面部属性学习等特定任务中的有效性,有两个重要因素需要进一步探索。
网络初始化:由于PS-MCNN由五个独立的网络组成,如图2所示,因此有许多可用的初始化策略。 例如,我们可以为TSNets和SNet选择相同的初始化,或者我们可以从头开始训练所有网络。 它需要实验来为面部属性学习场景做出最佳选择,
SNet的通道数:SNet的通道数决定了每个TSNet的共享表示的比例。 有两种极端情况。
当共享信道的数量变为零时,SNet消失并且PS-MCNN退化为四个独立的TSNets。 另一方面,当共享信道的分数变为1时,所有特征都是共享特征,PS-MCNN仅包括SNet。
3具有局部约束的部分共享网络用于面部属性学习
由于身份信息通常存在于人脸属性学习中的训练数据中,我们利用这些信息来提高属性分类性能。本节首先介绍局部学习约束。 然后我们将它与PS-MCNN结合起来解决人脸属性学习的问题。
3.1。 本地学习约束
根据[7,3],以全局方式学习良好的表示可能不是一个好的策略,因为它通常不考虑当地的几何数据结构。因此如果我们能够以简单的方式对几何结构进行编码并将其融入表示学习的过程中,那么找到它将更有效。
适当的嵌入功能。 事实上,除了全局分类损失之外,面部验证方法[33,4,28,36,17]通常采用局部约束损失,例如对比损失[33]或三重损失[28]。 此外,我们还发现,对于相同的身份,面部属性标签非常相似。 这意味着属性通过身份相关具有一定的局部几何结构,这是对传统全局属性学习的补充。
为了实现局部学习的目标,我们通过首先定义具有与几何邻域相同的标识的样本然后约束几何邻域的属性表示彼此接近来提出局部学习约束。 因此,具有相同身份的样本将具有更多属性相似性。 我们将局部学习约束的损失函数表示为LCLoss:

3.2。 具有局部约束的部分共享多任务卷积神经网络
我们将局部学习约束和PS-MCNN结合起来,如图3所示,并计算最终层的连接特征的LCLoss,以约束所有
四组。 因此,提出了一种局部约束的部分共享多任务卷积神经网络(PSMCNN-LC),其目标函数可以表述如下:

其中ALossi是第i个TSNet的属性丢失,λ是LCLoss的权重。 在配方中,LCLoss作为局部学习正则化,并帮助PS-MCNN-LC模型局部几何结构。 正则化参数λ控制局部学习约束的强度。 例如,当λ几乎为零时,LCLoss对属性学习的影响有限。 另一方面,如果λ变得太大,则PS-MCNN-LC更加关注身份学习,并且可能损害属性预测性能。
3.3.烧蚀分析
我们在第二节讨论设计决策。 4.1和Sec。 4.2修复模型超参数。 然后,基于固定模型,在第二节中验证了PS体系结构的有效性。 4.3从两个方面来看。 最后进行复杂性分析
在第二节4.4。 消融研究的实验细节如下所示。
数据集:CelebA数据集[18]根据建议的配置分为训练集(160k图像),验证集(20k图像)和测试集(20k图像)。 为了更好的比较,我们还测试了LFWA数据集的性能[12]。网络架构:PS-MCNN和PSMCNN-LC都由5个具有相同架构的网络组成,包括4个TSN和1个SNet。 详细参数
表1中列出了TSNets的通道数,而SNet的通道数将在第2节中单独讨论。4.2
4.1。 网络初始化
我们已经尝试了三种用于网络初始化的配置:(1)SNet和TSNets在CelebA的训练集上被预训练,称为FR;(2)SNet和TSNets从头开始训练; (3)SNet在人脸识别任务上预先训练,而每个TSNet在CelebA上的组内的属性预测任务上预训练,称为TS。 如表2所示,配置(3)表现最佳,因为FR初始化4293表1. PS-MCNN中TNets的网络架构。 SNet也共享这种结构,但通道数不同。注意在每个卷积层和完全连接层之后采用批量标准化[14]和ReLU [22]。
表2.不同网络初始化下PS-MCNN的性能。
帮助SNet提取更好的共享表示,而TS初始化鼓励TSNets保留更多任务特定功能。 然而,当FR初始化应用于SNet和TSNets时,TSNets更加关注与身份相关的区域,而与其他区域相对应的属性没有得到很好的学习[30]。
4.2。 SNet的通道数
我们尝试了六种不同数量的通道,如表3所示。有两种极端情况:(1)SNet的通道数为零,PS-MCNN退化为四个TSN,称为Inde。 组; (2)只有
共享表示但没有任务特定的特征导致PS-MCNN成为单个SNet,在表3中称为SNet。两种极端情况的性能明显差于常规PSMCNN的性能。
由于前者没有共享功能,后者没有任务特定功能,因此这两种情况都不适合建模属性关系。
4.3。 PS架构的有效性
为了消除网络的其他因素的影响(例如,属性分组),我们训练PS-MCNN和Inde。 集团(4个独立的TSNets)对4个密切相关
属性(Chubby,Double Chine,Moustache,No Beard),每个属性对应一个TSNet。 我们将它们称为Inde。 表4中的组(单个)和PS-MCNN(单个)通过比较Inde的错误率。 组(单)和PS-MCNN(单),我们看到没有属性分组,性能增益仍然很大。 因此,主要的性能增益确实来自所提出的部分共享结构而不是其他因素。
此外,PS架构要求SNet在每一层连接到TSNets,以便尽可能地增强属性组之间的信息交换。 我们还研究了其他可能的设计以减少SNet的参数。 特别是,我们在表5中提供了具有减少的SNet的PS-MCNN的实验结果,其每两层融合并广播来自TSNets的特征。
从表5中可以看出,由于不同属性组之间信息交换的减少,这种设计模型的整体性能下降。 因此,SNet的当前设计适合于释放潜力
PS结构的能力。
表5.具有不同SNets设计的PS-MCNN的错误率。
4.4。 复杂性分析
我们分析了MCNN [9]和PS-MCNN的计算成本与浮点运算(FLOPs)的乘加数,这在以前的工作中常用[10,11]。 虽然实际运行时间可能受到包括编码质量和GPU带宽在内的其他因素的影响,但是这种成本分析提供了速度上限的估计。 如表6所示,PSMCNN比MCNN消耗的FLOP少约22%,并且仅具有1/20的MCNN参数。 因此,PS-MCNN是一个更实用的网络。 我们在下面阐明PS-MCNN和MCNN之间的设计差异。
MCNN分别对前两个卷积层采用7×7和5×5内核,这导致了大量的FLOP。 它直接将14×14×500个特征图馈送到每个组的完全连接层,从而产生大量参数。 相反,PSMCNN在整个网络中使用3×3内核,并向完全连接的层输入6×5×128个特征映射。 因此,虽然PS-MCNN有5个子网,但每个子网都经过精心设计,以减少参数和FLOP的数量,同时通过添加更多层来最大化其学习能力。
5实验
我们现在用PS-MCNN和PSMCNN-LC进行面部属性学习的实验。 我们使用与第二节中讨论的相同的数据集和网络体系结构。 4.PS-MCNN和PS-MCNN-LC的详细配置描述如下。
培训设置:我们使用带有64个批量大小的CelebA数据集的对齐图像进行培训。 我们将初始学习率设置为0.001,并在训练期间将其减少两次。 所有网络都使用标准的小批量SGD方法在Caffe [15]平台上进行培训[16]。
特别是,我们首先训练SNet在CelebA上只有身份损失。 然后,我们删除最后一个完全连接的SNet层并将其链接到4个TSNets。 最后,对整个PSMCNN进行了属性分类丢失训练。
网络配置:根据表2和表3,我们为SNet选择1/4通道的TSNets,同时使用TS初始化配置初始化四个TSNets和SNet与FR初始化配置。
5.1。基线
我们将PS-MCNN和PS-MCNN-LC与三个强基线进行比较。 LNets + ANet [18]是面部属性学习的第一种深度学习方法。 MCNN [9]是最好的
最先进的方法,采用网络中的分离架构。 为了更好地进行比较,我们还报告了四个独立TSNets的性能,称为Inde.Group。 结果报告在表7中。
5.2。 与基线比较
根据表7,PS-MCNN的平均错误率为7.78%,优于所有竞争方法。 特别是,与最先进的MCNN方法相比,CelebA的错误率降低了11.0%。 采用LCLoss后,错误率进一步降低了19.8%。 LFWA的表现也得到了显着改善。
与LNets + ANet的比较:PS-MCNN的表现优于LNets + ANet超过30%。 我们将它归功于ANet的天真架构,它共享所有功能直到最后一个完全连接的层。 因此,ANet对任务特定功能学习的关注非常有限。
与MCNN的比较:MCNN使用拆分结构,其中较低层与所有属性共享,而较高层是专门为组学习的。
因此,较低层仅学习共享功能,而较高层仅学习任务特定功能。 相反,PS-MCNN旨在学习所有层中的共享功能,同时保留任务特定功能。 因此,PS-MCNN能够建立更好的属性关系,以提高分类性能。
与Inde的比较。 Group:我们比较Inde。 与PS-MCNN分组以验证SNet的必要性。 如表7所示,Inde的错误率。 该组平均比PS-MCNN和PS-MCNN-LC高1.07%和1.83%。 我们将此归因于缺少共享功能。 学习所有任务的互补共享表示对于改进这些任务至关重要
多任务学习的泛化性能。 特别地,PS-MCNN和PS-MCNN-LC都构建单个网络SNet以实现该目标。 通过学习整个网络的共享功能,PS-MCNN鼓励这四项任务通过利用彼此的功能来提高性能。
为了更好地理解共享特征通道数量的影响,我们在表8中显示了两个样本的conv2层的特征映射。对于SNet,Upper Group将更多权重放在除了上部区域之外的其他区域上,以便作为Lower Group ,这有助于每个任务利用来自其他组的信息,更好地属性关系。 例如,整个图像组中的男性和下组中的无胡子是强相关的。 SNet能够帮助建模这些属性关系以获得更高的性能。
LCLoss的有效性:PS-MCNN-LC在CelebA数据集上显着优于PS-MCNN,因为LCLoss捕获了基于此的局部几何结构
身份信息。 参数λ反映了局部学习约束的强度。 根据表9,不同的λ值可导致PS-MCNN-LC的显着不同的性能。特别地,当λ变得几乎为零时,LCLoss对属性学习的影响有限,因此PS-MCNN-LC的表现与PS-MCNN类似。。 另一方面,如果λ变得太大,则PS-MCNN-LC更加关注身份学习,并且属性预测性能不可避免地受到损害。
总的来说,当前身份约束的设置是一种简单有效的方法,用于建模具有相同身份的样本的属性相似性。 此外,这种通用身份约束可能始终无效,需要研究更灵活的方案。
为了更好地说明LCLoss的影响,我们在图4中不同λ下的400k相同同一性图像对的fc7层上显示了组特征余弦相似性。尽管四组的平均相似性不同,但相似性随着λ的增加而增加。 但是,同一个人可能有几个不同的属性标签。 当大的λ强迫同一个人的不同图像的特征变得高度相似时,PS-MCNN-LC无法学习相同身份的属性标签变化,这会损害表9中所示的最终性能。因此,它是 在考虑具有相同标识的不同样本的属性标签一致性和属性标签变量时,选择适当的λ的权衡。
ter共享和任务特定功能。 为了利用身份信息,我们引入了一种LCLoss,它可以最小化每个样本的特征与具有相同身份的局部几何邻域之间的差异。 因此,我们提出了PS-MCNN-LC,其中PS结构和局部约束被集成在一起,以帮助框架学习更好的属性特征。 CelebA和LFWA的实验结果证明了所提方法的前景。
结论
在本文中,我们通过同时考虑身份信息和属性关系建模来研究面部属性学习问题。 尤其是,我们首先介绍PS-MCNN,其中四个TSNets和一个SNet通过PS结构连接,以学习更好的共享和任务特定功能。 为了利用身份信息,我们引入了一种LCLoss,它可以最小化每个样本的特征与具有相同身份的局部几何邻域之间的差异。 因此,我们提出了PS-MCNN-LC,其中PS结构和局部约束被集成在一起,以帮助框架学习更好的属性特征。 CelebA和LFWA的实验结果证明了它的前景提出的方法。