三种方式模拟登录新版知乎
python环境 3.6.2
1、使用selenium库实现模拟登陆:
selenium是进行自动化测试的一种库,配合浏览器相对应的webdriver,可以模拟浏览器行为登录知乎,大大方便、简化了登录操作。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 创建Chrome Webdriver对象
browser = webdriver.Chrome('F:\chromedriver.exe')
# 调用get()方式打开登录界面
browser.get('https://www.zhihu.com/signup?next=%2F')
等待页面加载完成
time.sleep(3)
# 设置窗口大小
browser.set_window_size(1366,760)
# 模拟浏览器行为,通过注册页面转到登录界面
ele = browser.find_element(By.XPATH, '//span[text()="登录"]')
ele.click()
# 定位到input输入框
user = browser.find_element_by_name('username')
# 清空input用户名输入框默认内容
user.clear()
# 输入用户名
user.send_keys("13643551349")
# 定位密码框并进行操作,同上
pwd = browser.find_element(By.NAME, 'password')
pwd.clear()
pwd.send_keys('password')
# 定位登录按钮,并进行点击,实现模拟登陆知乎
login = browser.find_element(By.XPATH, '//button[@type="submit"]')
login.click()
# 关闭浏览器
browser.quit()因为我用的是Chrome浏览器做的测试,所以要下载与Chrome对应的Chrome webdriver版本,并在创建browser对象的时候指定路径,如果需要进行登录后的操作,下载无界面的浏览器phantomjs,加快运行效率,注意phantomjs对selenium 2.48.0版本以下提供支持。
2、使用requests库实现模拟登录。
关键点:
1、在调试工具中发送错误账号密码,查看post请求的路径,
![]()
应为在提交表单前必须先get一个图片URL的请求,如图

它的返回结果是json字符串,表明是否展示验证码,在测试过程中第一次请求我是返回false的,所以代码中省略了将验证码到表单中
![]()
如果value值为true,则需要在表单数据中添加验证码post到https://www.zhihu.com/api/v3/oauth/sign_in,由于我调试的时候发送了错误的账号密码,第二次登录的时候需要提交验证码。
2、一定要创建一个session对象,使用requests.Session(),他可以保持一个会话状态,从另个一角度讲,将无状态的协议变成有状态的协议,如果直接使用requests.get()方法,服务器将会返回错误状态码。
3、创建请求头,设置user_agent参数,authorization参数,避免403,401错误。
4、表单数据:

在post表单中有两个值是动态变化的,timestamp,signature,第一个是时间戳,第二个是数字签名,signature是根据js动态生成的。
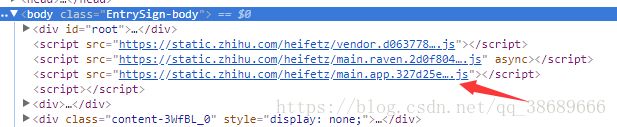
全区搜索signature可得到相关js代码。
下面这段js代码使用python的hmac库实现的动态生成数字签名,代码中的get_signature()函数,就是对表单里的client_id、password、timestamp字段进行update操作,从而得出signature数字签名。
function(e,t,n){
"use strict";
function r(e,t){
var n=Date.now(),r=new a.a("SHA-1","TEXT");
return r.setHMACKey("d1b964811afb40118a12068ff74a12f4","TEXT"),r.update(e),r.update(i.a),r.update("com.zhihu.web"),r.update(String(n)),s({clientId:i.a,grantType:e,timestamp:n,source:"com.zhihu.web",signature:r.getHMAC("HEX")},t)}import hashlib
import hmac
import requests
import time
import base64
import http.cookiejar as ch
import json
# 创建session,通过session发起请求会保持一个会话状态
session = requests.Session()
# session.cookies = ch.LWPCookieJar('cookies.txt')
# try:
# session.cookies.load(ignore_discard=True)
# except:
# print ("cookie未能加载")
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'origin': 'https://www.zhihu.com',
'referer': 'https://www.zhihu.com/signup?next=%2F',
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20', # 如果缺少此参数,会报出‘缺少验证码票据’错误
}
# 获取当前时间戳
timestamp = str(int(time.time()*1000))
# 获取登录时用到的数字签名
def get_signature(time):
h = hmac.new('d1b964811afb40118a12068ff74a12f4'.encode('utf-8'), digestmod=hashlib.sha1)
h.update(''.join(['password', "c3cef7c66a1843f8b3a9e6a1e3160e20", "com.zhihu.web", time]).encode('utf-8'))
return h.hexdigest()
#获取验证码
def get_chptcha():
chptcha_url = 'https://www.zhihu.com/api/v3/oauth/captcha?lang=en'
response = session.get(chptcha_url, headers=headers)
print(response.text)
ch_judge = json.loads(response.text).get('show_captcha')
if ch_judge:
#img_response = session.put(chptcha_url, #headers=headers).text.get('img_base64')
# result = base64.b64decode(img_response)
#with open('chpt.jpg', 'wb') as f:
#f.write(result)
else:
return ''
# 检测是否登录成功
def get_index(url):
r = session.get(url, headers=headers, allow_redirects=False, verify=False)
print(r.text, r.url)
with open('index_page.html', 'wb') as f:
f.write(r.content)
登录知乎
def zhihu_login(captcha, time):
post_data = {
"client_id": 'c3cef7c66a1843f8b3a9e6a1e3160e20',
"grant_type": 'password',
"timestamp": time,
"source":'com.zhihu.web',
'signature': get_signature(time),
'username': '+8613643551349',
"password": 'password',
"captcha": captcha,
"lang": 'en',
"ref_source": 'homepage',
"utm_source": '',
}
response = session.post(url='https://www.zhihu.com/api/v3/oauth/sign_in', data=post_data, headers=headers)
print(response.text)# session.cookies.save()
if __name__ == '__main__':
zhihu_login(get_chptcha(), timestamp)
get_index('https://www.zhihu.com/people/scorpion-15-3/activities')3、使用scrapy框架模拟登陆
思路与使用requests库,基本相同,以下是参考代码
import scrapy
import time
import hashlib
import hmac
import json
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
def __init__(self):
self.timestamp = str(int(time.time() * 1000))
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36',
'x - xsrftoken': 'ee248650 - a89e - 4dc0 - 8b2d - 1b78c9e4f5c5',
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20',
'x - udid': 'ALAvNZYlUw2PTglCYVZ2IRpoJdHHEAn7CU8 =',
'origin': 'https://www.zhihu.com',
'referer': 'https://www.zhihu.com/signup?next=%2F'
}
def get_signature(self):
h = hmac.new('d1b964811afb40118a12068ff74a12f4'.encode('utf-8'), digestmod=hashlib.sha1)
h.update(''.join(['password', "c3cef7c66a1843f8b3a9e6a1e3160e20", "com.zhihu.web", self.timestamp]).encode('utf-8'))
return h.hexdigest()
post_data = {
"client_id": 'c3cef7c66a1843f8b3a9e6a1e3160e20',
"grant_type": 'password',
"timestamp": '',
"source": 'com.zhihu.web',
'signature': '',
'username': '+8613643551349',
"password": "password",
"captcha": '',
"lang": 'en',
"ref_source": 'homepage',
"utm_source": '',
}
def parse(self, response):
print(response.text)
print(response.body)
def get_captcha(self, response):
print(response.text)
ch_judge = json.loads(response.text).get('show_captcha')
if ch_judge:
print('需要使用验证码')
# 由于登录过程中死活没有遇到需要验证码的登录,也就pass掉了。如果遇到了,用get。put、post方法,最后获取验证码跟表单数据post到相关页面。
pass
# img_response = session.put(chptcha_url, headers=headers).text.get('img_base64')
# result = base64.b64decode(img_response)
# with open('chpt.jpg', 'wb') as f:
# f.write(result)
else:
print('不需要输入验证码')
self.post_data["timestamp"] = self.timestamp
self.post_data['signature'] = self.get_signature()
return [scrapy.FormRequest(url='https://www.zhihu.com/api/v3/oauth/sign_in', formdata=self.post_data, headers=self.headers, callback=self.is_login)]
def start_requests(self):
# timestamp = str(int(time.time() * 1000))
return [scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
headers=self.headers, callback=self.get_captcha)]
def is_login(self, response):
response_obj = json.loads(response.text)
if response_obj.get('user_id') is not None:
for url in self.start_urls:
yield scrapy.Request(url=url, dont_filter=True,)