python3爬虫 - cookie登录
实战1:使用cookie登录哈工大ACM站点
获取站点登录地址
http://acm.hit.edu.cn/hoj/system/login
查看要传送的post数据
user和password
Code:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
__author__ = 'pi'
__email__ = '[email protected]'
"""
import urllib.request, urllib.parse, urllib.error
import http.cookiejar
LOGIN_URL = 'http://acm.hit.edu.cn/hoj/system/login'
values = {'user': '******', 'password': '******'} # , 'submit' : 'Login'
postdata = urllib.parse.urlencode(values).encode()
user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36'
headers = {'User-Agent': user_agent, 'Connection': 'keep-alive'}
cookie_filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(cookie_filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
request = urllib.request.Request(LOGIN_URL, postdata, headers)
try:
response = opener.open(request)
page = response.read().decode()
# print(page)
except urllib.error.URLError as e:
print(e.code, ':', e.reason)
cookie.save(ignore_discard=True, ignore_expires=True) # 保存cookie到cookie.txt中
print(cookie)
for item in cookie:
print('Name = ' + item.name)
print('Value = ' + item.value)
get_url = 'http://acm.hit.edu.cn/hoj/problem/solution/?problem=1' # 利用cookie请求訪问还有一个网址
get_request = urllib.request.Request(get_url, headers=headers)
get_response = opener.open(get_request)
print(get_response.read().decode())
# print('You have not solved this problem' in get_response.read().decode())
Note:
1. 直接open http://acm.hit.edu.cn/hoj/problem/solution/?
problem=1页面不知道去哪了,根本不是直接用浏览器登录后的界面!
用cookie登录就能够正常訪问。html代码中会有一句话you have not solved this problem。由于我没做这道题。
2. 原理:创建一个带有cookie的opener,在訪问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来訪问其它网址。查看登录之后才干看到的信息。[python 3.3.2 爬虫记录]
反复使用cookie登录
上面代码中我们保存cookie到文件里了,以下我们能够直接从文件导入cookie进行登录,不用再构建包括username和password的postdata了
import urllib.request, urllib.parse, urllib.error import http.cookiejar cookie_filename = 'cookie.txt' cookie = http.cookiejar.MozillaCookieJar(cookie_filename) cookie.load(cookie_filename, ignore_discard=True, ignore_expires=True) print(cookie) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) get_url = 'http://acm.hit.edu.cn/hoj/problem/solution/?problem=1' # 利用cookie请求訪问还有一个网址 get_request = urllib.request.Request(get_url) get_response = opener.open(get_request) print(get_response.read().decode())
皮皮Blog
实战2:使用cookie登录伯乐在线
获取站点登录地址
1. chrome浏览器中按F12审查元素 > Network > Headers > General > Request URL: http://www.jobbole.com/login/?redirect=http://www.jobbole.com/
然而这个并非其真实站点登录网址^-^
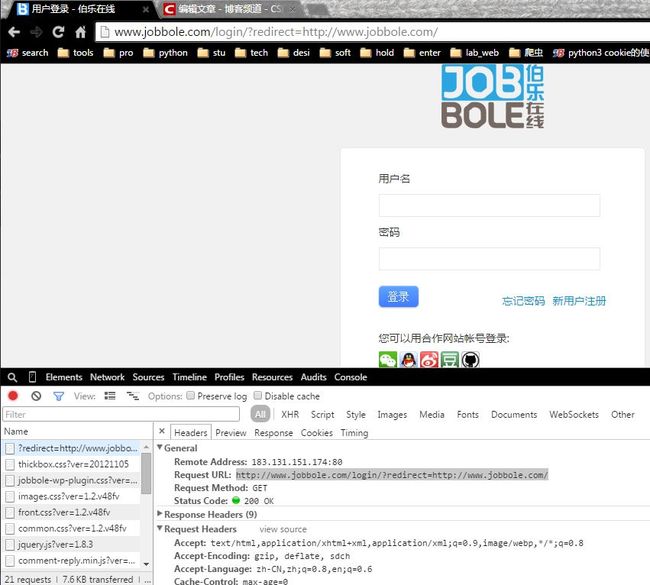
2. 也能够下载软件Fiddler for .NET2查看相关信息。执行python程序訪问和直接在浏览器中刷新都能够在fiddler中找到相关信息。
Note: fiddler事实上是抓包用的,是独立的工具。类似这样的前端登录动作,也能够用casperjs。还能够用HttpWatch浏览器嵌入工具。
查看200所在的条目(200:请求成功 处理方式:获得响应的内容,进行处理)
![]()
以下是登录后看到的request中有webforms的信息相应的网址是也就是其真实站点登录网址http://www.jobbole.com/wp-admin/admin-ajax.php
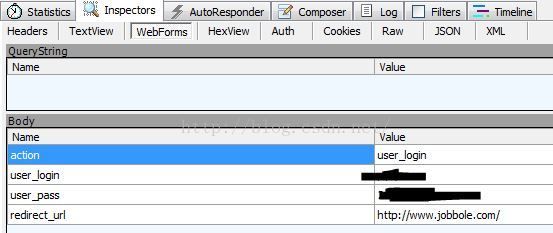
(吓死爷了。第一次上传居然忘了把password遮住!
)
查看要传送的post数据
1. 上面使用fiddler看到的webforms就是登录要用的post数据要包括的(当中redict_url是能够不加上去的)
2. 或者使用浏览器Elements > html文档中所要提交的数据有name和password。然而这个并非真实的post数据^-^

查看headers信息
假设不自己加入headers信息中的User-Agent。python代码登录时会默认使用User-Agent: Python-urllib/3.4
我们在chrome浏览器中按F12审查元素 > Network > Headers中能够看到User-Agent应该设置为:'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36'
一般要加入的headers信息有:
'Host': '', 'Accept': '', 'User-Agent': '', 'Accept-Language': '', Accept-Encoding
登录后查看request headers
发现cookie发生了变化,加上了username***和password*************
Cookie:
wordpress_test_cookie=WP+Cookie+check
Cookie:
wordpress_test_cookie=WP+Cookie+check; wordpress_logged_in_0efdf49af511fd88681529ef8c2e5fbf=****%7C1440690138%*********************
#!/usr/bin/env python # -*- coding: utf-8 -*- """ __title__ = '' __author__ = 'pi' __mtime__ = '8/23/2015-023' __email__ = '[email protected]' # code is far away from bugs with the god animal protecting I love animals. They taste delicious. ┏┓ ┏┓ ┏┛┻━━━┛┻┓ ┃ ☃ ┃ ┃ ┳┛ ┗┳ ┃ ┃ ┻ ┃ ┗━┓ ┏━┛ ┃ ┗━━━┓ ┃ 神兽保佑 ┣┓ ┃ 永无BUG。 ┏┛ ┗┓┓┏━┳┓┏┛ ┃┫┫ ┃┫┫ ┗┻┛ ┗┻┛ """ import urllib.request, urllib.parse, urllib.error import http.cookiejar LOGIN_URL = 'http://www.jobbole.com/wp-admin/admin-ajax.php' get_url = 'http://www.jobbole.com/' # 利用cookie请求訪问还有一个网址 values = {'action': 'user_login', 'user_login': '*****', 'user_pass': '******'} postdata = urllib.parse.urlencode(values).encode() user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36' headers = {'User-Agent': user_agent} cookie_filename = 'cookie_jar.txt' cookie_jar = http.cookiejar.MozillaCookieJar(cookie_filename) handler = urllib.request.HTTPCookieProcessor(cookie_jar) opener = urllib.request.build_opener(handler) request = urllib.request.Request(LOGIN_URL, postdata, headers) try: response = opener.open(request) # print(response.read().decode()) except urllib.error.URLError as e: print(e.code, ':', e.reason) cookie_jar.save(ignore_discard=True, ignore_expires=True) # 保存cookie到cookie.txt中 for item in cookie_jar: print('Name = ' + item.name) print('Value = ' + item.value) get_request = urllib.request.Request(get_url, headers=headers) get_response = opener.open(get_request) print('个人主页' in get_response.read().decode()) Note:
1. cookie登录不成功则会输出:
Name = wordpress_test_cookie
Value = WP+Cookie+check
这个就说明之前根本没有登录成功,主要是真实登录地址不正确!
2. cookie登录成功时会输出:
Name = wordpress_0efdf49af511fd88681529ef8c2e5fbf
Value = *****%***%*******************(value中会包括账户和password)
而且jobbole_response.read()输出中存在“个人主页”“退出登录”字样。就说明登录成功了。否则仅仅会有“登录”“注冊”之类的字符串。
使用刚刚保存的cook_jar.txt文件登录參见[python爬虫 - Urllib库及cookie的使用 - 从文件里获取Cookie并訪问]
皮皮Blog
实战3:使用cookie登录知乎
眼下知乎採用动态验证码破解还没验证。这样post里面还须要captcha的參数。待定。。。
Note:这个_xsrf事实上能够不submit,它已经作为cookie写进去了。能够看看登入www.zhihu.com的返回的header。
皮皮Blog
实战4:使用cookie登录本科站点爬取成绩信息
注意这个站点是https的站点。只是和上面的cookie登录的http站点一样登录。登录的是电子科大门户(由于小编就是UESTC的嘛)
获取本科站点登录地址
1. chrome浏览器中按F12审查元素 > Network > Headers > General > Request URL:https://uis.uestc.edu.cn/amserver/UI/Login
能够看到其真实站点登录网址为https://uis.uestc.edu.cn/amserver/UI/Login
2. 当然也能够用fiddler抓取https的请求,只是要配置一下:Tools > fiddler options > https > capture...和decrypt都打√ > 然后依据提示安装一证书yes就能够了
查看要传送的post数据
打开fiddler后。浏览器中登录门户站点,在fidddles中看到相应的webforms实际提交的数据。只是也仅仅要IDToken1', 'IDToken2这两个数据。

代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
__author__ = 'pi'
__email__ = '[email protected]'
"""
import urllib.request
import urllib.parse
import urllib.error
import http.cookiejar
LOGIN_URL = r'https://uis.uestc.edu.cn/amserver/UI/Login' # 登录教务系统的URL
get_url = 'http://eams.uestc.edu.cn/eams/teach/grade/course/person.action' # 利用cookie请求訪问还有一个网址
values = {'IDToken1': '201106******', 'IDToken2': '***********'}
postdata = urllib.parse.urlencode(values).encode()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36'}
cookie_filename = 'cookie_jar.txt'
cookie_jar = http.cookiejar.MozillaCookieJar(cookie_filename)
handler = urllib.request.HTTPCookieProcessor(cookie_jar)
opener = urllib.request.build_opener(handler)
request = urllib.request.Request(LOGIN_URL, postdata, headers)
try:
response = opener.open(request)
# print(response.read().decode())
except urllib.error.URLError as e:
print(e.code, ':', e.reason)
cookie_jar.save(ignore_discard=True, ignore_expires=True) # 保存cookie到cookie.txt中
for item in cookie_jar:
print('Name = ' + item.name)
print('Value = ' + item.value)
get_request = urllib.request.Request(get_url, headers=headers)
get_response = opener.open(get_request)
print(get_response.read().decode())