hbase shell
最近要做数据分析测试,看hbase 中所存数据是否正确,之前未接触过,所以把用到的命令记录下来,以便后续查询使用
1、hbase shell
2、list 列出所有表
3、scan '表名' 查询整张表记录
4、get '表名','行键' :查询某个行键所对应的的记录
5、count '表名‘ :查询表中多少条记录
6、值过滤器 scan '表名', FILTER=>"ValueFilter(=,'substring:brand')" :查询表中含有brand的所有记录
7、查看表中某一列 :scan 'xjhanalysis_collect_httprequest_20170821',{COLUMNS=>['header']}
8、查询某一列的前5条:scan 'xjhanalysis_collect_httprequest_20170821',{COLUMNS=>['header'],LIMIT=>5}
9、想查询出表下面有多少列族
①echo "desc 'xjhanalysis_collect_httprequest_20170821'" 输出表
②echo "desc 'xjhanalysis_collect_httprequest_20170821'"|/usr/local/hbase/bin/hbase shell 输出表文件|进入hbase shell下
解释:
"/usr/local/hbase/bin/hbase shell" 这条命令是进入hbase的shell 下执行操作
echo "scan 'xjhanalysis_collect_httprequest_20170821'" 这条命令是将scan 'xjhanalysis_collect_httprequest_20170821 作文文本输入到某某地方
| 这个是管道符,建立前后两条命令的连接
整个连接起来的意思是,将scan 'xjhanalysis_collect_httprequest_20170821' 作为文本输入到 hbase shell下执行。③echo "scan 'xjhanalysis_collect_httprequest_20170821'"|/usr/local/hbase/bin/hbase shell|awk '{print $2}'|sort|uniq -c 打印第二部分|进行排序|唯一列
-c代表有多少重复行,
sort是排序,把重复的排列在一起
awk '{print $2}' 打印出第2部分,默认空格为分隔符,如果想打印第1,2部分,就是awk '{print $1,$2}'
10,把输出结果生成文本文件:前一命令>>xx.txt

11、把生成的文件拷贝到自己电脑上:sz xx.txt
把用到的结果截图记录在此,一边查询
1、echo "scan 'xjhanalysis_collect_httprequest_20170821'"

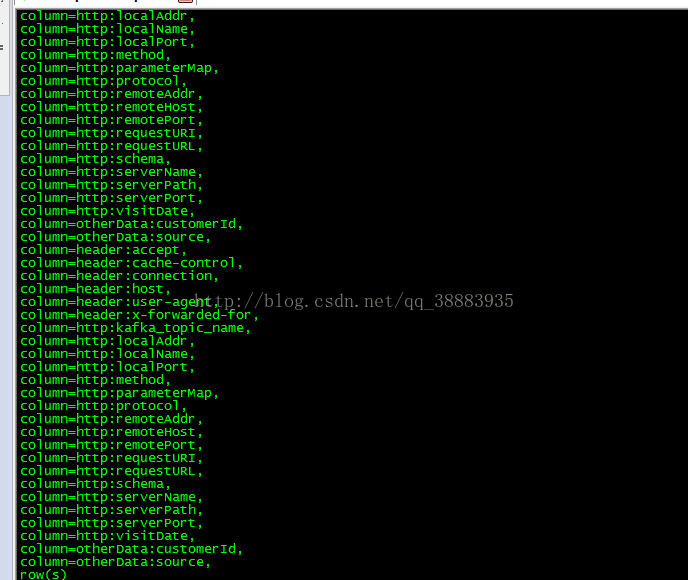
2、echo "desc 'xjhanalysis_collect_httprequest_20170821'"|/usr/local/hbase/bin/hbase shell

3、echo "scan 'xjhanalysis_collect_httprequest_20170821'"|/usr/local/hbase/bin/hbase shell|awk '{print $2}'
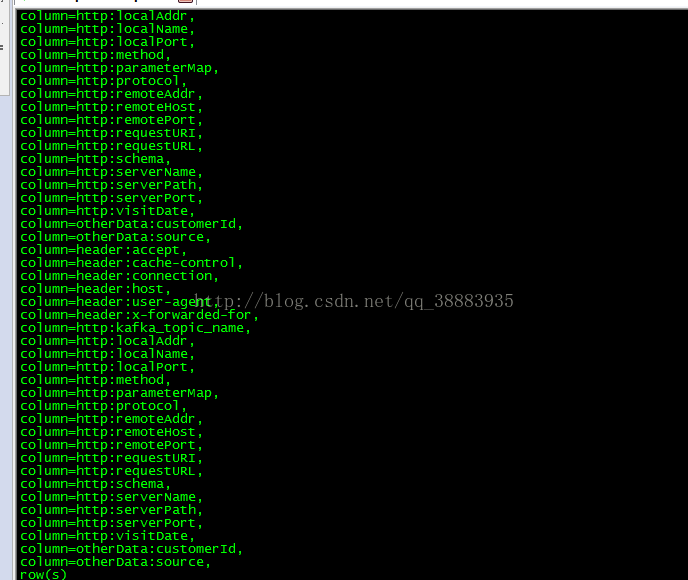
timestamp' '{print $1}':意思是:—F指定分隔符,然后打印第几部分
4、echo "scan 'xjhanalysis_collect_httprequest_20170821'"|/usr/local/hbase/bin/hbase shell|awk '{print $2}'|sort|uniq -c 列族下的不同列