基于百度API,实现图片文字识别功能(Java版)
1、登录百度AI开放平台
网站链接:http://ai.baidu.com/
新手接入指南:http://ai.baidu.com/docs#/Begin/top
(1)在顶部导航栏中,找到控制台选项,并选择文字识别功能,进入管理中心页面
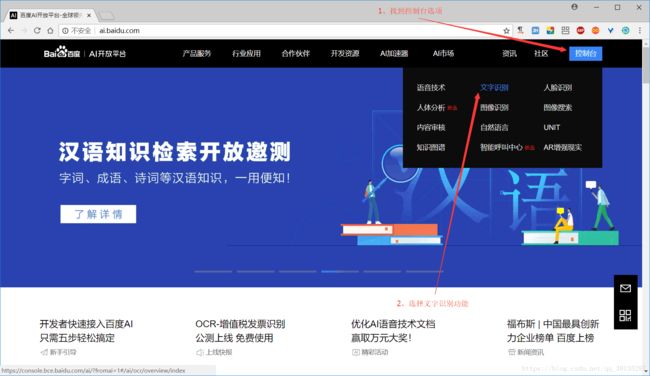
(2)在管理中心页面中,找到创建应用按钮并点击
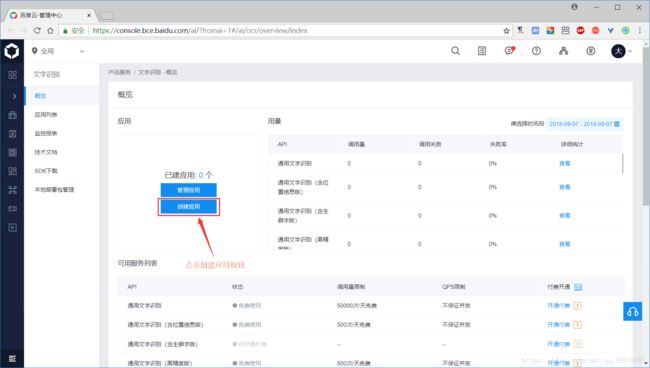
(3)填写应用名名称和应用描述,选择相应的应用类型,勾选自己需要的接口服务(如果选择的是文字识别,则对应的文字识别接口服务默认全部勾选),文字识别包名如果是应用在电脑端,则默认选择不需要即可,如果还需要其他功能,则再勾选其功能对应的相关接口即可,例如:在文字识别的时候,我还需要人脸识别,则再勾选人脸识别对应的所有接口即可
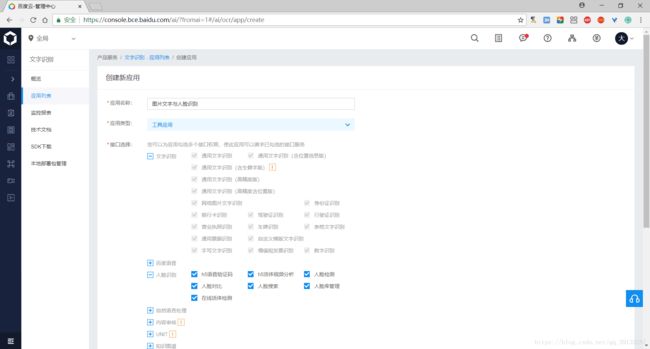

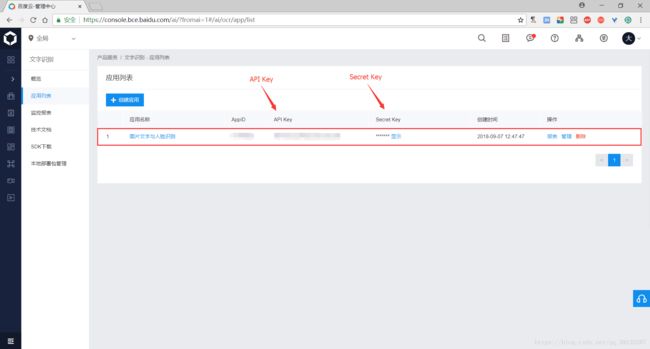
(4)创建完毕之后,点击返回应用列表按钮

(5)在应用列表界面中,即可查看应用对应的 API Key 和 Secret Key
2、获取Access Token
(1)导入Java SDK 和 FastJson工具包
普通工程:
一、下载fastjson.jar工具包 链接:https://pan.baidu.com/s/1RH4-x82G8-sNmn7y5YhdjA
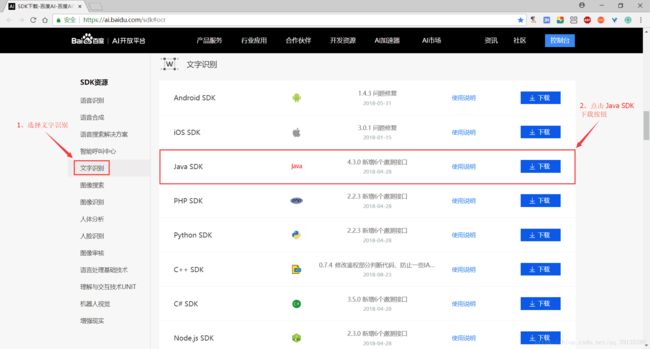
二、进入SDK下载页面 网站链接:https://ai.baidu.com/sdk#ocr
三、找到文字识别,选择Java SDK,点击右边的下载按钮
四、把下载好的Java SDK 和 FastJson工具包 导入到项目中即可
Maven工程:
直接把下面这段代码复制到 pom.xml 中就行
com.baidu.aip
java-sdk
4.5.0
com.alibaba
fastjson
1.2.47
(2)获取Access Token
package com.project.dom;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.List;
import java.util.Map;
import com.alibaba.fastjson.JSONObject;
/**
* 百度文字识别demo
*/
public class baiduOcr {
/**
* 获取权限token
* @return 返回示例:
* {
* "access_token": "24.c9303e47f0729c40f2bc2be6f8f3d589.2592000.1530936208.282335-1234567",
* "expires_in":2592000
* }
*/
public static String getAuth() {
// 官网获取的 API Key
String clientId = "官网获取你的 API Key";
// 官网获取的 Secret Key
String clientSecret = "官网获取你的 Secret Key";
return getAuth(clientId, clientSecret);
}
/**
* 获取API访问token
* 该token有一定的有效期,需要自行管理,当失效时需重新获取.
* @param ak - 百度云的 API Key
* @param sk - 百度云的 Securet Key
* @return assess_token 示例:
* "24.c9303e47f0729c40f2bc2be6f8f3d589.2592000.1530936208.282335-1234567"
*/
public static String getAuth(String ak, String sk) {
// 获取token地址
String authHost = "https://aip.baidubce.com/oauth/2.0/token?";
String getAccessTokenUrl = authHost
// 1. grant_type为固定参数
+ "grant_type=client_credentials"
// 2. 官网获取的 API Key
+ "&client_id=" + ak
// 3. 官网获取的 Secret Key
+ "&client_secret=" + sk;
try {
URL realUrl = new URL(getAccessTokenUrl);
// 打开和URL之间的连接
HttpURLConnection connection = (HttpURLConnection) realUrl.openConnection();
connection.setRequestMethod("POST");//百度推荐使用POST请求
connection.connect();
// 获取所有响应头字段
Map> map = connection.getHeaderFields();
// 定义 BufferedReader输入流来读取URL的响应
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String result = "";
String line;
while ((line = in.readLine()) != null) {
result += line;
}
System.err.println("result:" + result);
JSONObject jsonObject = JSONObject.parseObject(result.toString());
String access_token = jsonObject.getString("access_token");
return access_token;
} catch (Exception e) {
System.err.printf("获取token失败!");
e.printStackTrace(System.err);
}
return null;
}
}
调用baiduOcr.getAuth()就能获取到result,result格式如下:
result: {
"access_token": "24.6c5e1ff107f0e8bcef8c46d3424a0e78.2592000.1485516651.282335-8574074",
"session_key":"9mzdDZXu3dENdFZQurfg0Vz8slgSgvvOAUebNFzyzcpQ5EnbxbF+hfG9DQkpUVQdh4p6HbQcAiz5RmuBAja1JJGgIdJI",
"scope": "public wise_adapt",
"refresh_token": "25.5f706c15bfc5799897518ab954b2bc07.1234567890.1843716344.1234567-1234567",
"session_secret": "dfac94a3489fe9fca7c3221cbf7525ff",
"expires_in": 2592000
}其中暂时有用的就access_token和expires_in两个值,access_token是调用文字识别必带的一个参数,expires_in是Access Token 的有效期一般是一个月
3.将本地图片进行BASE64位编码
import sun.misc.BASE64Encoder;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class BASE64 {
/**
* 将本地图片进行Base64位编码
*
* @param imgUrl 图片的url路径,如D:\\photo\\1.png
*
* @return
*/
public static String encodeImgageToBase64(File imageFile) {
// 将图片文件转化为字节数组字符串,并对其进行Base64编码处理
// 其进行Base64编码处理
byte[] data = null;
// 读取图片字节数组
try {
InputStream in = new FileInputStream(imageFile);
data = new byte[in.available()];
in.read(data);
in.close();
} catch (Exception e) {
e.printStackTrace();
}
// 对字节数组Base64编码
BASE64Encoder encoder = new BASE64Encoder();
return encoder.encode(data);// 返回Base64编码过的字节数组字符串
}
}
4.文字识别
package com.project.dom;
import java.io.BufferedReader;
import java.io.File;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import com.alibaba.fastjson.JSONObject;
/**
*
* @版权 : Copyright (c) 2017-2018 *********公司技术开发部
* @author: wubin
* @E-mail: [email protected]
* @版本: 1.0
* @创建日期: 2018年9月8日 上午8:40:34
* @ClassName PictureUtil
* @类描述-Description: TODO(这里用一句话描述这个方法的作用)
* @修改记录:
* @版本: 1.0
*/
public class PictureUtil {
public static String request(String httpUrl, String httpArg) {
BufferedReader reader = null;
String result = null;
StringBuffer sbf = new StringBuffer();
try {
// 用java JDK自带的URL去请求
URL url = new URL(httpUrl);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// 设置该请求的消息头
// 设置HTTP方法:POST
connection.setRequestMethod("POST");
// 设置其Header的Content-Type参数为application/x-www-form-urlencoded
connection.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
// 填入apikey到HTTP header
connection.setRequestProperty("apikey", "uml8HFzu2hFd8iEG2LkQGMxm");
// 将第二步获取到的token填入到HTTP header
connection.setRequestProperty("access_token", baiduOcr.getAuth());
connection.setDoOutput(true);
connection.getOutputStream().write(httpArg.getBytes("UTF-8"));
connection.connect();
InputStream is = connection.getInputStream();
reader = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String strRead = null;
while ((strRead = reader.readLine()) != null) {
sbf.append(strRead);
sbf.append("\r\n");
}
reader.close();
result = sbf.toString();
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
// 把json格式转换成HashMap
public static HashMap getHashMapByJson(String jsonResult) {
HashMap map = new HashMap();
try {
JSONObject jsonObject = JSONObject.parseObject(jsonResult.toString());
JSONObject words_result = jsonObject.getJSONObject("words_result");
Iterator it = words_result.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
JSONObject result = words_result.getJSONObject(key);
String value = result.getString("words");
switch (key) {
case "姓名":
map.put("name", value);
break;
case "民族":
map.put("nation", value);
break;
case "住址":
map.put("address", value);
break;
case "公民身份号码":
map.put("IDCard", value);
break;
case "出生":
map.put("Birth", value);
break;
case "性别":
map.put("sex", value);
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
return map;
}
public static void main(String[] args) {
// 获取本地的绝对路径图片
File file = new File("D:\\photo\\1.png");
// 进行BASE64位编码
String imageBase = BASE64.encodeImgageToBase64(file);
imageBase = imageBase.replaceAll("\r\n", "");
imageBase = imageBase.replaceAll("\\+", "%2B");
// 百度云的文字识别接口,后面参数为获取到的token
String httpUrl = "https://aip.baidubce.com/rest/2.0/ocr/v1/idcard?access_token=" + baiduOcr.getAuth();
String httpArg = "detect_direction=true&id_card_side=front&image=" + imageBase;
String jsonResult = request(httpUrl, httpArg);
System.out.println("返回的结果--------->" + jsonResult);
HashMap map = getHashMapByJson(jsonResult);
Collection values = map.values();
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
System.out.print(iterator2.next() + ", ");
}
}
}
其中HttpArg中的请求参数我就直接把官网上的弄了下来
| 参数 | 是否必选 | 类型 | 可选值范围 | 说明 |
| detect_direction | false | string | true、false | 是否检测图像旋转角度,默认不检测,即:false。朝向是指输入图像是正常方向、逆时针旋转90/180/270度。可选值包括: - true:检测旋转角度并矫正识别; - false:不检测旋转角度,针对摆放情况不可控制的情况建议本参数置为true。 |
| id_card_side | true | string | front、back | front:身份证含照片的一面;back:身份证带国徽的一面 |
| image | true | string | 图像数据,base64编码后进行urlencode,要求base64编码和urlencode后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式 | |
| detect_risk | false | string | true、false | 是否开启身份证风险类型(身份证复印件、临时身份证、身份证翻拍、修改过的身份证)功能,默认不开启,即:false。可选值:true-开启;false-不开启 |
身份证的文字识别代码就差不多都写完了,我把身份证附上(百度官网上弄下来的测试身份证)

让我们来运行看下效果吧
{
"log_id": 6403608607836186924,
"words_result_num": 6,
"direction": 0,
"image_status": "normal",
"words_result": {
"住址": {
"location": {
"width": 197,
"top": 150,
"height": 37,
"left": 78
},
"words": "北京市海淀区上地十号七栋2单元110室"
},
"出生": {
"location": {
"width": 148,
"top": 111,
"height": 15,
"left": 79
},
"words": "19890601"
},
"姓名": {
"location": {
"width": 63,
"top": 32,
"height": 25,
"left": 77
},
"words": "百度熊"
},
"公民身份号码": {
"location": {
"width": 252,
"top": 243,
"height": 15,
"left": 139
},
"words": "532101198906010015"
},
"性别": {
"location": {
"width": 20,
"top": 76,
"height": 15,
"left": 71
},
"words": "男"
},
"民族": {
"location": {
"width": 12,
"top": 76,
"height": 15,
"left": 172
},
"words": "汉"
}
}
}
其中main方法的map打印为:北京市海淀区上地十号七栋2单元110室, 532101198906010015, 汉, 男, 百度熊, 19890601
如果有遇到不懂或者有问题时,可以扫描下方二维码,欢迎进群交流与分享,希望能够跟大家交流学习!
