训练py-faster rcnn的两种方式以及自己模型的迁移学习
faster rcnn训练方式有两种,一种是交替优化方法(alternating optimization),即训练两个网络,一个是rpn,一个是fast rcnn,总计两个stage,每个stage各训练一次rpn和fast rcnn。另外一种训练方式为近似联合训练(approximate joint training),也称end to end的训练方式,训练过程中只训练一个权重网络,训练速度有可观的提升,而训练精度不变。
1. alternating optimization
alternating optimization训练过程分如下四个小阶段:
1. stage 1 RPN proposals
2. stage 1 Fast R-CNN using PRN proposals
3. stage 2 Fine tune RPN proposals of stage 1
4. stage 2 Fine tune Fast R-CNN of stage 1
每个阶段求解器的超参数配置文件在:models/数据集/预训练模型/faster_rcnn_alt_opt下,如stage1_faste_rpn_solver60k80k.pt.
可以修改如下参数:
base_lr: 0.001lr_policy: "step"
gamma: 0.1
stepsize: 60000
display: 20
average_loss: 100
momentum: 0.9
weight_decay: 0.0005
此外每个阶段的back bone基础网络模型也在这个路径下,如stage1_rpn_train.pt
训练准备工作
1. 在训练新模型时候,为防止与之前的模型搞混,需要再训练前完成以下三件事:
(1) output文件夹删除,
(2)删除py-faster-rcnn/data/cache中的文件
(3)删除py-faster-rcnn/data/VOCdevkit2007/annotations_cache中的文件
2. 至于学习率等之类的设置,可在py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt中的solve文件设置,
迭代次数可在py-faster-rcnn\tools的train_faster_rcnn_alt_opt.py中修改:
max_iters = [80000, 40000, 80000, 40000]
分别为4个阶段(rpn第1阶段,fast rcnn第1阶段,rpn第2阶段,fast rcnn第2阶段)的迭代次数。可改成你希望的迭代次数。如果改了这些数值,最好把py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt里对应的solver文件(有4个)也 修改,stepsize小于上面修改的数值。
3. 在训练自建数据集时,需要修改class name,class num参数,参考这里。
4. 数据集准备
解压下载好的voc2007数据集
VOCtrainval_06-Nov-2007.tar VOCtest_06-Nov-2007.tar VOCdevkit_08-Jun-2007.tar
解压后的文件结构如下
$VOCdevkit/ # 开发工具包 $VOCdevkit/VOCcode/ # VOC实用代码 $VOCdevkit/VOC2007# 图片集, 注释, 等等 # 一些其他的目录将VOCdevkit改名为VOCdevkit2007,然后放到data文件夹下
5. 下载预训练模型
cd $FRCN_ROOT
./data/scripts/fetch_imagenet_models.sh6. 训练数据
使用交替优化(alternating optimization)算法来训练和测试Faster R-CNN
cd $FRCN_ROOT
./experiments/scripts/faster_rcnn_alt_opt.sh [GPU_ID] [NET] [--set ...]
# 你可以选择如下的网络之一进行训练:ZF, VGG_CNN_M_1024, VGG16
# --set ... 运行你自定义fast_rcnn.config参数,例如.
# --set EXP_DIR seed_rng1701 RNG_SEED 1701
#例如命令
./experiments/scripts/faster_rcnn_alt_opt.sh 0 ZF pascal_voc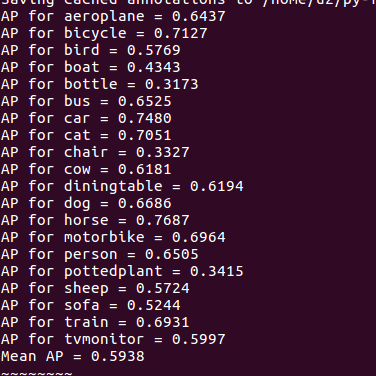
2. approximate joint training
approximate joint training 训练方式的参数配置与alternating optimization方式不同。需要修改如下三个文件(以vgg16训练70000次为例):
1. 修改py-faster-rcnn/lib/datasets/pascal_voc.py 文件中的第30行, self._classes,改成自己的标签。
2. 修改 py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_end2end下两个文件:
train.prototxt 和 test.prototxt。
其中test.prototxt修改:
(1)第567行:num_output:自己数据集标签数+1,
(2)第592行:num_output:(自己数据集标签数+1)*4,
train.prototxt修改要多一些:
(1)第11, 530, 620行 : num_output:自己数据集标签数+1,
(2)第643行:num_output:(自己数据集标签数+1)*4,
训练时输入下列命令:
cd $FRCN_ROOT
./experiments/scripts/faster_rcnn_end2end.sh [GPU_ID] [NET] [--set ...]或
./tools/train_net.py --gpu 0 --solver models/pascal_voc/VGG16/faster_rcnn_end2end/solver.prototxt --weights data/imagenet_models/VGG16.v2.caffemodel --imdb voc_2007_trainval --iters 70000 --cfg experiments/cfgs/faster_rcnn_end2end.yml./tools/test_net.py --gpu 0 --def models/pascal_voc/VGG16/faster_rcnn_end2end/test.prototxt --net /home/u2/py-faster-rcnn/output/faster_rcnn_end2end/voc_2007_trainval/vgg16_faster_rcnn_iter_70000.caffemodel --imdb voc_2007_test --cfg experiments/cfgs/faster_rcnn_end2end.yml读者在参考以上两条命令时,根据自己项目需求注意修改模型类型和训练次数等参数
demo:
1.把 output文件夹下输出的 model 拷贝到py-faster-rcnn/data/faster_rcnn_models 下
2.修改 demo.py 里的第28行的CLASS,下面的NETS。分别改为自己的标签和 步骤1. 中拷贝的训练好模型的名字。
3. 终端输入:
./tools/demo.py
3. transfer learning fron self-train model:对自己模型的迁移学习
有时候我们训练好一个模型A后,想要用类似的数据对模型A fine-tuning,换句话说就是把模型A当做预训练模型再次进行微调训练,这对于数据集风格类似,但数据数量不足的情况比较合适(vgg16,end2end为例)。
1. 首先把模型A 拷贝到py-faster-rcnn/data/imagenet_models下,记名字为a.caffemodel
2. 修改 py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_end2end下两个文件:
train.prototxt 和 test.prototxt。
修改bbox_pred层为bbox_pred1
cls_score 层为cls_score1
3. 终端输入:注意预训练模型名字已经修改成a.caffemodel
./tools/train_net.py --gpu 0 --solver models/pascal_voc/VGG16/faster_rcnn_end2end/solver.prototxt --weights data/imagenet_models/a.caffemodel --imdb voc_2007_trainval --iters 10000 --cfg experiments/cfgs/faster_rcnn_end2end.yml4. 修改py-faster-rcnn/lib/fast_rcnn下的test.py,将173行的bbox_pred改为bbox_pred1.
5. 终端输入
./tools/test_net.py --gpu 0 --def models/pascal_voc/VGG16/faster_rcnn_end2end/test.prototxt --net /home/u2/py-faster-rcnn/output/faster_rcnn_end2end/voc_2007_trainval/vgg16_faster_rcnn_iter_10000.caffemodel --imdb voc_2007_test --cfg experiments/cfgs/faster_rcnn_end2end.yml待续