服务器网络故障处理——ping丢包或不通时链路测试说明
前言
当客户端访问目标服务器出现 ping 丢包或 ping 不通时,可以通过 tracert 或 mtr 等工具进行链路测试来判断问题来源。本文先介绍了进行链路测试的相关工具,然后对测试结果分析及测试步骤进行了说明。
链路测试工具介绍
根据操作系统类型的不同,链路测试所使用的工具也有所不同。分别简要介绍如下。
- Linux 环境下链路测试工具介绍
- Windows 环境下链路测试工具介绍
Linux 环境下链路测试工具介绍
traceroute 命令行工具
mtr 命令行工具(建议优先使用)
traceroute 命令行工具
traceroute 是几乎所有 Linux 发行版本预装的网络测试工具,用于跟踪 Internet 协议(IP)数据包传送到目标地址时经过的路径。
traceroute 先发送具有小的最大存活时间值(Max_TTL)的 UDP 探测数据包,然后侦听从网关开始的整个链路上的 ICMP TIME_EXCEEDED 响应。探测从 TTL=1 开始,TTL 值逐步增加,直至接收到ICMP PORT_UNREACHABLE 消息。ICMP PORT_UNREACHABLE 消息用于标识目标主机已经被定位,或命令已经达到允许跟踪的最大 TTL 值。
traceroute 默认发送 UDP 数据包进行链路探测。可以通过 -I 参数来指定发送 ICMP 数据包用于探测。
用法说明:
traceroute [-I] [ -m Max_ttl ] [ -n ] [ -p Port ] [ -q Nqueries ] [ -r ] [ -s SRC_Addr ] [ -t TypeOfService ] [ -f flow ] [ -v ] [ -w WaitTime ] Host [ PacketSize ]
示例输出:
[root@haiyuan ~]# traceroute -I 122.112.248.206
traceroute to 122.112.248.206 (122.112.248.206), 30 hops max, 60 byte packets
1 * * *
2 * * *
3 100.80.0.1 (100.80.0.1) 11.044 ms 10.834 ms 16.801 ms
4 10.39.3.129 (10.39.3.129) 8.574 ms 9.014 ms 23.937 ms
5 192.168.10.2 (192.168.10.2) 9.062 ms 9.004 ms 8.572 ms
6 * * *
7 10.44.2.130 (10.44.2.130) 2.521 ms 2.530 ms 2.494 ms
8 10.44.2.18 (10.44.2.18) 6.319 ms 6.192 ms 5.826 ms
9 10.1.0.146 (10.1.0.146) 2.346 ms 2.391 ms 1.988 ms
10 10.1.0.126 (10.1.0.126) 127.950 ms 126.041 ms 125.266 ms
11 10.1.0.133 (10.1.0.133) 3.891 ms 3.814 ms 3.675 ms
12 106.39.255.77 (106.39.255.77) 66.390 ms 66.165 ms 66.187 ms
13 * * *
14 220.181.0.210 (220.181.0.210) 5.114 ms 5.102 ms *
15 220.181.0.197 (220.181.0.197) 7.653 ms 7.641 ms 7.526 ms
16 * * *
17 * * *
18 * * *
19 101.95.192.5 (101.95.192.5) 34.033 ms 34.029 ms 34.165 ms
20 101.95.192.5 (101.95.192.5) 32.002 ms 32.067 ms 32.161 ms
21 * * *
22 * * *
23 * * *
24 * * *
25 * * *
26 * * *
27 * * *
28 * * *
29 * * *
30 * * *
常见可选参数说明:
-d 使用Socket层级的排错功能。
-f 设置第一个检测数据包的存活数值TTL的大小。
-F 设置不要分段标识。
-g 设置来源路由网关,最多可设置8个。
-i 使用指定的网卡送出数据包。用于主机有多个网卡时。
-I 使用ICMP数据包替代 UDP 数据包进行探测。
-m 设置检测数据包的最大存活数值TTL的大小。
-n 直接使用IP地址而非主机名称(禁用 DNS 反查)。
-p 设置UDP传输协议的通信端口。
-r 忽略普通的Routing Table,直接将数据包送到远端主机上。
-s 设置本地主机送出数据包的IP地址。
-t 设置检测数据包的TOS数值。
-v 详细显示指令的执行过程。
-w 设置等待远端主机回包时间。
-x 开启或关闭数据包的正确性检验。
mtr 命令行工具(建议优先使用)
mtr (My traceroute)也是几乎所有 Linux 发行版本预装的网络测试工具。他把 ping和 traceroute 的功能并入了同一个工具中,所以功能更强大。
mtr 默认发送 ICMP 数据包进行链路探测。可以通过 -u 参数来指定使用 UDP 数据包用于探测。
相对于 traceroute 只会做一次链路跟踪测试,mtr 会对链路上的相关节点做持续探测并给出相应的统计信息。所以,mtr能避免节点波动对测试结果的影响,所以其测试结果更正确,建议优先使用。
用法说明:
mtr [-hvrctglspni46] [--help] [--version] [--report] [--report-cycles=COUNT] [--curses] [--gtk] [--raw] [--split] [--no-dns] [--address interface][--psize=bytes/-s bytes][--interval=SECONDS] HOSTNAME [PACKETSIZE]
示例输出:
mtr 122.112.248.206

常见可选参数说明:
-r 或 --report:以报告模式显示输出。
-p 或 --split:将每次追踪的结果分别列出来,而非如 --report统计整个结果。
-s 或 --psize:指定ping数据包的大小。
-n 或 --no-dns:不对IP地址做域名反解析。
-a 或 --address:设置发送数据包的IP地址。用于主机有多个IP时。
-4:只使用 IPv4 协议。
-6:只使用 IPv6 协议。
另外,也可以在 mtr 运行过程中,输入相应字母来快速切换模式,比如:
?或 h:显示帮助菜单。
d:切换显示模式。
n:切换启用或禁用 DNS 域名解析。
u:切换使用 ICMP或 UDP 数据包进行探测。
返回结果说明:
默认配置下,返回结果中各数据列的说明:
第一列(Host):节点IP地址和域名。如前面所示,按n键可以切换显示。
第二列(Loss%):节点丢包率。
第三列(Snt):每秒发送数据包数。默认值是10,可以通过参数 -c 指定。
第四列(Last):最近一次的探测延迟值。
第五、六、七列(Avg、Best、Wrst):分别是探测延迟的平均值、最小值和最大值。
第八列(StDev):标准偏差。越大说明相应节点越不稳定。
Windows 环境下链路测试工具介绍
TRACERT 命令行工具
WinMTR 工具(建议优先使用)
TRACERT 命令行工具
TRACERT (Trace Route) 是 Windows 自带的网络诊断命令行实用程序,用于跟踪 Internet 协议 (IP) 数据包传送到目标地址时经过的路径。
TRACERT 通过向目标地址发送 ICMP 数据包来确定到目标地址的路由。在这些数据包中,TRACERT 使用了不同的 IP“生存期”(TTL) 值。由于要求沿途的路由器在转发数据包前至少必须将 TTL 减少 1,因此 TTL 实际上相当于一个跃点计数器 (hop counter)。当某个数据包的 TTL 达到零 (0) 时,相应节点就会向源计算机发送一个 ICMP“超时”的消息。
TRACERT 第一次发送 TTL 为 1 的数据包,并在每次后续传输时将 TTL 增加 1,直到目标地址响应或达到 TTL 的最大值。中间路由器发送回来的 ICMP“超时”消息中包含了相应节点的信息。
用法说明:
tracert [-d] [-h maximum_hops] [-j host-list] [-w timeout] [-R] [-S srcaddr] [-4] [-6] target_name
示例输出:
C:\Users\Administrator>tracert -d 122.112.248.206
通过最多 30 个跃点跟踪到 122.112.248.206 的路由
1 1 ms 1 ms 1 ms 192.168.1.1
2 3 ms 3 ms 3 ms 10.212.0.1
3 7 ms 3 ms 3 ms 182.51.56.137
4 4 ms 3 ms 15 ms 182.51.56.110
5 472 ms 7 ms 8 ms 202.127.112.1
6 * * * 请求超时。
7 12 ms 47 ms 12 ms 10.35.50.2
8 9 ms 10 ms 52 ms 222.223.243.121
9 9 ms 10 ms 13 ms 27.129.6.129
10 10 ms 14 ms 10 ms 27.129.1.253
11 20 ms 20 ms 19 ms 27.129.1.5
12 * 996 ms 23 ms 202.97.25.89
13 51 ms 48 ms 47 ms 61.152.86.241
14 * 50 ms * 101.95.206.218
15 51 ms 52 ms 48 ms 101.95.246.198
16 45 ms 45 ms 51 ms 101.95.192.5
17 * * * 请求超时。
18 * * * 请求超时。
19 * * * 请求超时。
20 * * * 请求超时。
21 * * * 请求超时。
22 * * * 请求超时。
23 * * * 请求超时。
24 * * * 请求超时。
25 * * * 请求超时。
26 * * * 请求超时。
27 * * * 请求超时。
28 * * * 请求超时。
29 * * * 请求超时。
30 * * * 请求超时。
跟踪完成。
常见可选参数说明:
-d:指定不将地址解析为主机名(禁用 DNS 反解)。
-h:maximum_hops,指定搜索目标地址时的最大跃点数。
-j: host-list,指定沿主机列表的松散源路由。
-w:timeout,由每个回复的 timeout 指定的等待毫秒数。
-R:跟踪往返行程路径(仅适用于 IPv6)。
-S:srcaddr,要使用的源地址(仅适用于 IPv6)。
-4:强制使用 IPv4。
-6:强制使用 IPv6。
target_host:目标主机域名或 IP 地址。
WinMTR 工具(建议优先使用)
WinMTR 是 mtr 工具在 Windows 环境下的图形化实现,但进行了功能简化,只支持 mtr部分参数的调整设置。WinMTR 默认发送ICMP 数据包进行探测,无法切换。
WinMTR 可以从其官方网站下载获取。
和 mtr 一样,相比 tracert,WinMTR 能避免节点波动对测试结果的影响,所以测试结果更正确。所以,在 WinMTR 可用的情况下,建议优先使用 WinMTR 进行链路测试。
用法说明:
WinMTR 无需安装,直接解压运行即可。操作方法非常简单,说明如下:
1、如下图所示,运行程序后,在 Host 字段输入目标服务器域名或 IP(注意前面不要包含空格)。
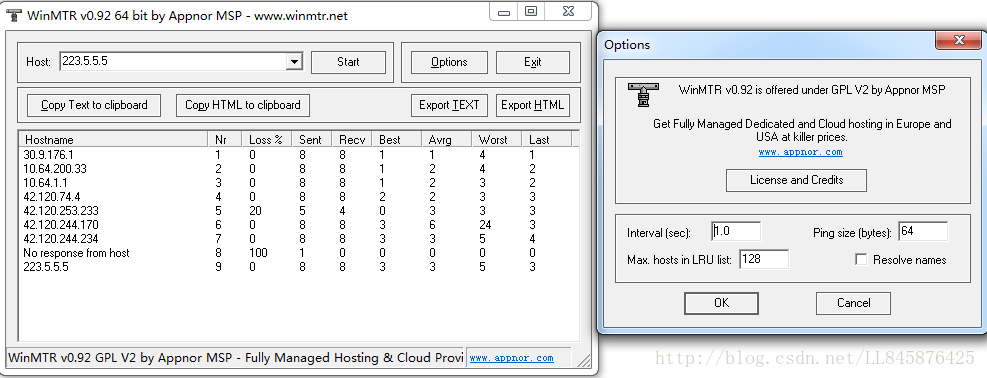
2、点击 Start 开始测试(开始测试后,相应按钮变成了 Stop)。
3、运行一段时间后,点击 Stop 停止测试。
4、其它选项说明:
Copy Text to clipboard:将测试结果以文本格式复制到粘贴板。
Copy HTML to clipboard:将测试结果以 HTML 格式复制到粘贴板。
Export TEXT:将测试结果以文本格式导出到指定文件。
Export HTML:将测试结果以 HTML 格式导出到指定文件。
Options:可选参数,包括:
Interval(sec):每次探测的间隔(过期)时间。默认为 1 秒。
Ping size(bytes): ping 探测所使用的数据包大小,默认为 64 字节。、
Max hosts in LRU list: LRU 列表支持的最大主机数,默认值为 128。
Resolve names:通过反查 IP 以域名显示相关节点。
返回结果说明:
默认配置下,返回结果中各数据列的说明:
第一列(Hostname):节点 IP 或域名。
第二列(Nr):节点编号。
第三列(Loss%):节点丢包率。
第四列(Sent):已发送的数据包数量。
第五列(Recv):已成功接收的数据包数量。
第六、七、八、九列(Best 、Avg、Worst、Last):分别是到相应节点延迟的最小值、平均值、最大值和最后一次值。
第八列(StDev):标准偏差。越大说明相应节点越不稳定。
链路测试结果分析简要说明
由于 mtr(WinMTR)有更高的准确性。本文以其测试结果为例,对链路测试结果的分析进行简要说明。
后续说明,以如下链路测试结果示例图为基础进行阐述:
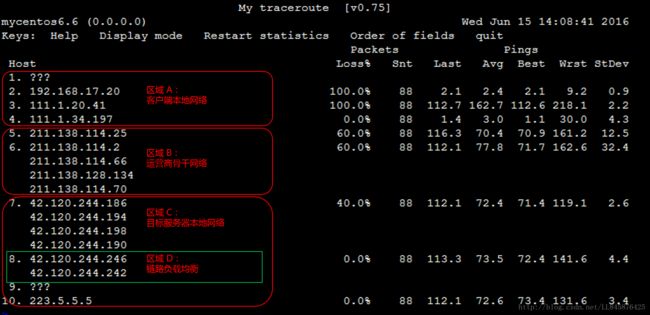
对链路测试结果进行分析时,需要关注如下要点:
网络区域
链路负载均衡
结合Avg(平均值)和 StDev(标准偏差)综合判断
Loss%(丢包率)的判断
关于延迟
网络区域
正常情况下,从客户端到目标服务器的整个链路,会显著的包含如下区域:
- 客户端本地网络(本地局域网和本地网络提供商网络):如前文链路测试结果示例图中的区域 A。如果该区域出现异常,如果是客户端本地网络相关节点出现异常,则需要对本地网络进行相应排查分析。否则,如果是本地网络提供商网络相关节点出现异常,则需要向当地运营商反馈问题。
- 运营商骨干网络:如前文链路测试结果示例图中的区域 B。如果该区域出现异常,可以根据异常节点 IP 查询归属运营商,向相应运营商反馈问题。
- 目标服务器本地网络(目标主机归属网络提供商网络): 如前文链路测试结果示例图中的区域 C。如果该区域出现异常,则需要向目标主机归属网络提供商反馈问题。
链路负载均衡
如前文链路测试结果示例图中的区域 D 所示。如果中间链路某些部分启用了链路负载均衡,则 mtr 只会对首尾节点进行编号和探测统计。中间节点只会显示相应的 IP 或域名信息。
结合Avg(平均值)和 StDev(标准偏差)综合判断
由于链路抖动或其它因素的影响,节点的 Best 和 Worst 值可能相差很大。而 Avg(平均值) 统计了自链路测试以来所有探测的平均值,所以能更好的反应出相应节点的网络质量。
而 StDev(标准偏差值)越高,则说明数据包在相应节点的延时值越不相同(越离散)。所以,标准偏差值可用于协助判断 Avg 是否真实反应了相应节点的网络质量。例如,如果标准偏差很大,说明数据包的延迟是不确定的。可能某些数据包延迟很小(例如:25ms),而另一些延迟却很大(例如:350ms),但最终得到的平均延迟反而可能是正常的。所以,此时 Avg 并不能很好的反应出实际的网络质量情况。
综上,建议的分析标准是:
如果 StDev 很高,则同步观察相应节点的 Best 和 Wrst,来判断相应节点是否存在异常。
-
如果 StDev 不高,则通过 Avg来判断相应节点是否存在异常。
注:上述 StDev “高”或者“不高”,并没有具体的时间范围标准。而需要根据同一节点其它列的延迟值大小来进行相对评估。比如,如果 Avg 为 30ms,那么,当 StDev 为 25ms,则认为是很高的偏差。而如果 Avg 为 325ms,则同样的 StDev(25ms),反而认为是不高的偏差。
Loss%(丢包率)的判断
任一节点的 Loss%(丢包率)如果不为零,则说明这一跳网络可能存在问题。导致相应节点丢包的原因通常有两种:
- 运营商基于安全或性能需求,人为限制了节点的 ICMP 发送速率,导致丢包。
- 节点确实存在异常,导致丢包。
可以结合异常节点及其后续节点的丢包情况,来判定丢包原因:
- 如果随后节点均没有丢包,则通常说明异常节点丢包是由于运营商策略限制所致。可以忽略相关丢包。如前文链路测试结果示例图中的第 2 跳所示。
- 如果随后节点也出现丢包,则通常说明异常节点确实存在网络异常,导致丢包。如前文链路测试结果示例图中的第 5 跳所示。
另外,需要说明的是,前述两种情况可能同时发生。即相应节点既存在策略限速,又存在网络异常。对于这种情况,如果异常节点及其后续节点连续出现丢包,而且各节点的丢包率不同,则通常以最后几跳的丢包率为准。如前文链路测试结果示例图所示,在第 5、6、7跳均出现了丢包。所以,最终丢包情况,以第 7 跳的 40% 作为参考。
关于延迟
延迟跳变
如果在某一跳之后延迟明显陡增,则通常判断该节点存在网络异常。如前文链路测试结果示例图所示,从第 5 跳之后的后续节点延迟明显陡增,则推断是第 5 跳节点出现了网络异常。
不过,高延迟并不一定完全意味着相应节点存在异常。如前文链路测试结果示例图所示,第 5 跳之后,虽然后续节点延迟明显陡增,但测试数据最终仍然正常到达了目的主机。所以,延迟大也有可能是在数据回包链路中引发的。所以,最好结合反向链路测试一并分析。
ICMP 限速导致延迟增加
ICMP 策略限速也可能会导致相应节点的延迟陡增,但后续节点通常会恢复正常。如前文链路测试结果示例图所示,第 3 跳有 100% 的丢包率,同时延迟也明显陡增。但随后节点的延迟马上恢复了正常。所以判断该节点的延迟陡增及丢包是由于策略限速所致。