
这是菜鸟学Python的第81篇原创文章
阅读本文大概需要5分钟
前面几篇讲了numpy也就是多维数组的用法,接下来几篇我们讲迎来重量级的库Pandas,可以说Python能成为数据分析的主流语言跟这个库有很大的关系,可见pandas在数据分析中的地位是相当的高呀,也说明了这个库很强大,今天我们就来初探一下pandas,并用一个小例子来分析一下基金
Pandas里面有2大非常重要的数据结构,一个是倚天剑Series,一个是屠龙刀DataFrame,这两者有什么作用以及有啥区别,不要急,学习这两大神兵利器其实无非就那么几招,有同学说是不是都是套路啊~~
创建
索引选取,切片
过滤
运算
排序
数据对齐,丢弃
什么是Series
相信大家都知道字典,字典是一种键值对,而且是无序的(有同学说字典也可以有序的,这位同学不要捣乱,那是借助第三方库的),那么有没有一种数据结构可以把键和值分离呢,而且是定长有序的呢,有啊这就是pandas里面的Series,而且功能比字典强大很多~~
1.基本特征及如何创建
有点类似一维数组,有数据内容和索引组成,我们一般引入pandas这个库.如何安装其实前面的数据分析入门篇就讲过了,大家可以看一下历史文章
a).可以用字典来创建
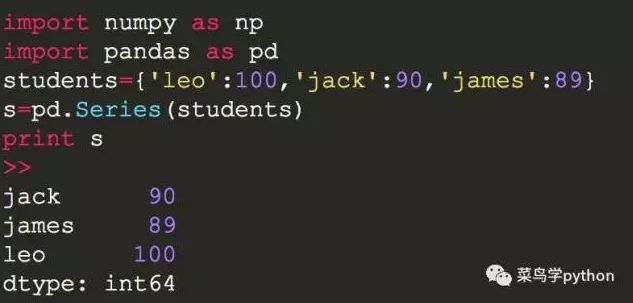
也可以像字典一样取Index和values
print s.index
>>
Index([u'jack', u'james', u'leo'], dtype='object')
print s.values
>>
[ 90 89 100]
b).也可以把键值和value分离,用两个列表来创建,相对独立
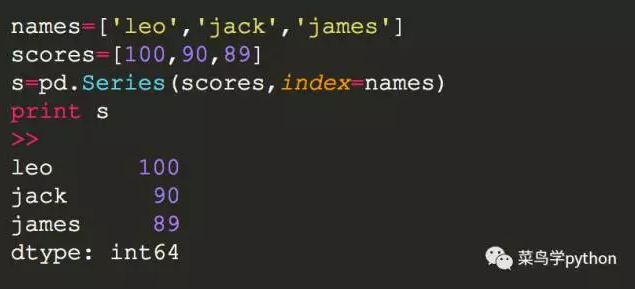
c).当然还可以用numpy的array来构造
n1=np.array([100,90,89])
s=pd.Series(n1,index=['leo','jack','james'])
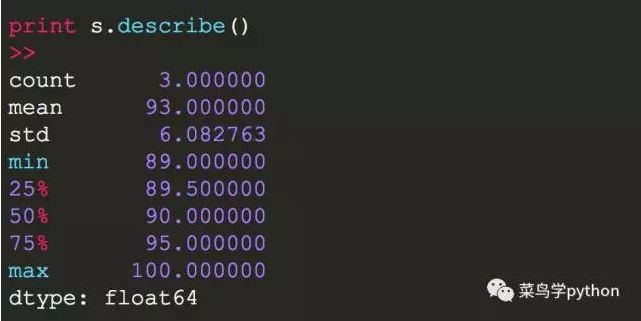
而且pandas有一个非常人性的describe函数,直接把常见的函数结果打出来
比如元素的个数,平均值,均方差,最大,最小等等,一目了然.
疑问:
有同学说这键值和index是不是长度都要对应啊,如果我有4个人,但是只有3个人的成绩怎么建Serier?
回答:
非常好的问题,键和内容确实要成对,我可以用None来补齐,或者是np.nan
2.通过索引选取,切片
比如有一个记录水果的数据序列
fruit=pd.Series([10,12,15,18],index=['Apple','Orange','Banana','watermelon'])
print fruit
>>
Apple 10
Orange 12
Banana 15
watermelon 18
dtype: int64
#取第一行,用loc是表示label
print fruit.loc['Apple']
>>10
#取第一行,也可以用iloc是表示index position
print fruit.iloc[0]
>>10
#取倒数第一行
print fruit.iloc[-1]
>>18
#取第二行,第四行
print fruit[[1,3]]
>>
Orange 12
watermelon 18
#切片
print fruit[2:4]
>>
Banana 15
watermelon 18
dtype: int64
是不是感觉和numpy的索引,切片用法很像
3.排序和过滤
pandas里面有一个非常重要的函数sort_index和reindex可以根据index重新排列
#用sort_index
s1=pd.Series(np.arange(4),index=['d','a','b','c'])
print s1.sort_index()
>>
a 1
b 2
c 3
d 0
dtype: int64
#用reindex
print s1.reindex(['a','b','c','d'])
>>
a 1
b 2
c 3
d 0
dtype: int64
#过滤一些数据,用法和numpy非常类似
print s1[s1>1]
>>
b 2
c 3
4.运算
a).比如两个Series相加,相同索引的时候,行会自动对齐相加
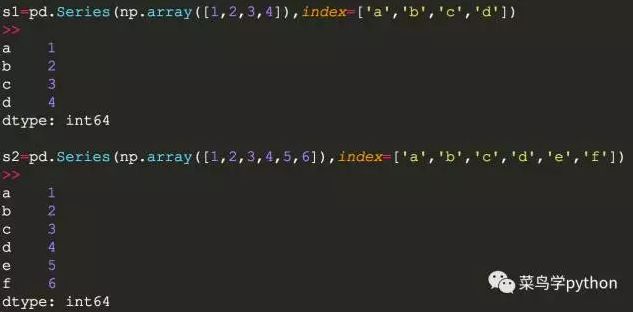
我们想想这两个序列相加会出现什么情况
print s1+s2
>>
a 2.0
b 4.0
c 6.0
d 8.0
e NaN
f NaN
dtype: float64
非常智能啊,把相同的index的数据相加,没有重叠的index数据变成NaN
思考:
如果array里面的内容不同的时候,相加会如何
s1=pd.Series(np.array([1,2,3,4]))
s2=pd.Series(np.array(['a','b','c','d']))
回答:
会报错的呀,因为 'int' and 'str'不能相加
5.数据对齐
比方我们有一个表,里面有apple,orange,banana,tomato
s1=pd.Series({'Apple':100,'Orange':200,'Banana':300,'Tomato':500})
print s1
>>
Apple 100
Banana 300
Orange 200
Tomato 500
dtype: int64
#然后我们从fruits要提取'Apple','Tomato','Cherry'
new_index=['Apple','Tomato','Cherry']
s2=pd.Series(fruits,index=new_index)
print s2
>>
Apple 100.0
Tomato 500.0
Cherry NaN
dtype: float64
我们发现Cherry,是没有的,NaN表示Not a Num意思是未定义
这个功能有什么用的,比如我们有一个暴长的表比如1000行的学生成绩单,我们只想提取其中某5个人的成绩,用这个数据对齐就很容易搞定
实例基金数据初步分析
上面说了这么多,大家好像还是没有看出Series一些特别强大的地方,好吧,是驴子是马拉出来溜溜,我们用实战来看一下Series的威力
1.某个基金的2个月数据
1).获取3,4月份的基金数据
我们通过爬虫可以非常容易的获取基金(3/1-4/28)的数据(爬虫以后会讲)
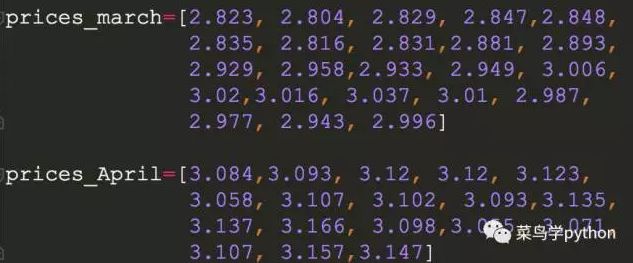
2).构造时间序列
Series很强的功能就是它有index,我们利用Series里的data_range可以非常方便的构造时间序列
rng=pd.date_range(start='2017-03-01',end='2017-04-28',freq='B')#freq=B表示是business day
但是3,4月份有2天虽然是business day但是不是交易日,因为4-3,4-4是清明放假的,所以我们需要做一些数据处理
holidays=['2017-04-03','2017-04-04']
market_rng=rng.delete(map(rng.get_loc,holidays))
好上面都准备好了之后,我们构建序列
fund1=pd.Series(prices_march+prices_April,index=market_rng)
print fund1
>>
2017-03-01 2.823
2017-03-02 2.804
2017-03-03 2.829
2017-03-06 2.847
2017-03-07 2.848
...
2017-04-28 3.147
dtype: float64
2.基金的初步数据分析
构成了series之后,我们就可以对这些数据随心所欲的分析了
1).获取基本信息,最大,最小,平均值
print fund1.describe()
>>
count 41.000000
mean 3.003439
std 0.113326
min 2.804000
25% 2.929000
50% 3.016000
75% 3.102000
max 3.166000
dtype: float64
2个月一共41个交易日,最低价是2.804,最高价是3.16,涨幅近12%,相当可观了.
2).进一步分析
#最高价是哪一天
print fund1.argmax(),fund1.max()
>>
2017-04-20 00:00:00 3.166
#最低价是哪一天
print fund1.argmin(),fund1.min()
>>
2017-03-02 00:00:00 2.804
如果说你运气好的话,在3月2号买入,那么你整个3,4月都是赚的,因为那是最低价
#有多少天是高于均价的
print fund1[fund1>fund1.mean()]
>>
2017-03-21 3.006
2017-03-22 3.020
2017-03-23 3.016
2017-03-24 3.037
2017-03-27 3.010
2017-04-05 3.084
2017-04-06 3.093
2017-04-07 3.120
2017-04-10 3.120
2017-04-11 3.123
2017-04-12 3.058
2017-04-13 3.107
2017-04-14 3.102
2017-04-17 3.093
2017-04-18 3.135
2017-04-19 3.137
2017-04-20 3.166
2017-04-21 3.098
2017-04-24 3.055
2017-04-25 3.071
2017-04-26 3.107
2017-04-27 3.157
2017-04-28 3.147
dtype: float64
print len(fund1[fund1>fund1.mean()])
>>
23
23交易日都是高于均价,而且这23天近80%都分布在4月份,也就是说从4月份开始基本都是在涨的,也就是说3月份整个一个月都是好的买入窗口时间好时机
3).波动情况
#查一下基金的3天,周线和月均线
print fund1.resample('3D').mean()
>>
2017-03-01 2.818667
2017-03-04 2.847000
2017-03-07 2.833000
...
2017-04-24 3.077667
2017-04-27 3.152000
Freq: 3D, dtype: float64
#周线
print fund1.resample('W').mean()
>>
2017-03-05 2.818667
2017-03-12 2.835400
2017-03-19 2.918800
2017-03-26 3.005600
2017-04-02 2.982600
2017-04-09 3.099000
2017-04-16 3.102000
2017-04-23 3.125800
2017-04-30 3.107400
Freq: W-SUN, dtype: float64
#月线
print fund1.resample('M').mean()
>>
2017-03-31 2.920348
2017-04-30 3.109611
Freq: M, dtype: float64
发现这个基金波动还是很平滑的,没有大起大落,而且周线基本是稳步上涨,月线也是不错的
用初探Pandas上篇Series运用就讲到这里,上面的基金分析只是九牛一毛,因为是教程举例所以没有展开讲,但是若你有5年的几千只基金的数据,那就有意思了。因为Series是一维序列,所以能分析的维度不多,后面我们会介绍更强大的多维序列DataFrame,那才是数据分析的真正好玩的开始。好,今天的文章希望能给初学者一些启发,若有什么不懂的,也可以留言跟我探讨交流
更多精彩内容,源码分享,请关于微信公众号"菜鸟学python"