一 为什么读这篇
大名鼎鼎的Faster R-CNN,二阶段法的代表,属于目标检测领域的必读之作。
二 截止阅读时这篇论文的引用次数
2019.2.9 6349次。在细分领域里能有这么多,可见影响之广泛。
三 相关背景介绍
15年6月首次挂在arXiv上,就比Fast RCNN晚一个多月,比YOLO v1早几天,比ResNet早半年。中了15年的NIPS。作者还是MSRA时那几个,一作任少卿当时还是MSRA的实习生,现在在Momenta,二作何恺明不用多说了,三作Ross Girshick(rbg)是R-CNN和Fast R-CNN的一作,YOLO v1的三作,四作孙剑也不用多说。拿了2015年的ImageNet和COCO的冠军。
四 关键词
Faster R-CNN
RPN
anchor
五 论文的主要贡献
1 比Fast R-CNN更快
2 提出RPN,统一了候选区域生成和最终的检测为一体
六 详细解读
0 摘要
虽然SPPnet和Fast R-CNN减少了检测网络的运行时间,不过候选区域的计算依旧是瓶颈。本文提出RPN(Region Proposal Network)网络,与检测网络共享整幅图像的卷积特征,从而实现几乎无成本的候选区域计算。RPN是全卷积网络,可以同时预测每个位置上的目标框和目标分数。RPN生成高质量的候选区域,用于Fast R-CNN的检测。通过共享卷积特征将RPN和Fast R-CNN合并为一个网络,这些卷积特征相当于通过"attention"机制,RPN部分告诉网络应该朝哪里看。用VGG16,能到5FPS,(测试时)每张图仅用300个候选区域就达到了VOC2007,2012和COCO的SOTA。
1 介绍
Selective Search是过去最流行的方法之一,它是基于低阶特征贪心地合并超像素,每张图在CPU上要运行2秒。EdgeBoxes提供了候选质量和速度的最佳权衡,每张图要0.2秒。而本文提出的RPN每张图10毫秒。
本文观察到像Fast R-CNN这样基于区域的检测器使用的卷积特征图也可以用来生成候选区域。在这些卷积特征之上,通过增加一些卷积层来构建RPN,这些层可以在常规网格的每个位置处同时回归候选框和目标分数。因此RPN是一种全卷积网络(Fully Convolutional Network FCN),可以针对生成候选区域的任务进行端到端的训练。
RPN旨在有效地预测具有各种尺度和纵横比的候选区域。相比之前方法,如图1a的图像金字塔,图1b的滤波器金字塔,本文引入一种全新的"anchor",作为多种尺度和纵横比的参考(图1c)。这种机制避免了大量的具有多个尺度或纵横比的图像(滤波器)。该模型在使用单尺度图像进行训练和测试时表现都很好,因此有利于提速。
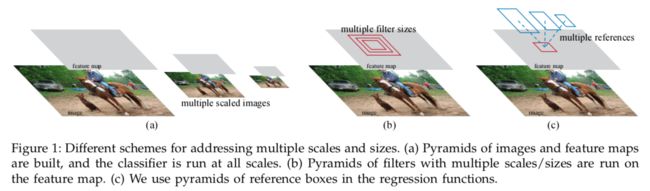
2 相关工作
候选目标
广泛使用的候选目标方法包括基于组超像素(如Selective Search,CPMC,MCG)和基于滑动窗口的方法(如EdgeBoxes)。候选目标方法作为与检测器独立的外部模块提供(如Selective Search,R-CNN,Fast R-CNN)
用于目标检测的深度网络
OverFeat方法训练全连接层来预测框坐标,而这个任务是假设只有单个对象的定位,后面的全连接层转为卷积层用于检测多个类相关的目标。MultiBox方法并没有共享候选和检测网络之间的特征。
共享卷积计算受到了越来越多的关注。
3 Faster R-CNN
Faster R-CNN主要由两个模块组成,第一个是产生候选区域的全卷积网络,第二个是使用候选区域的Fast R-CNN。用流行词"attention"来说就是RPN模块告诉Fast R-CNN模块应该看哪里。
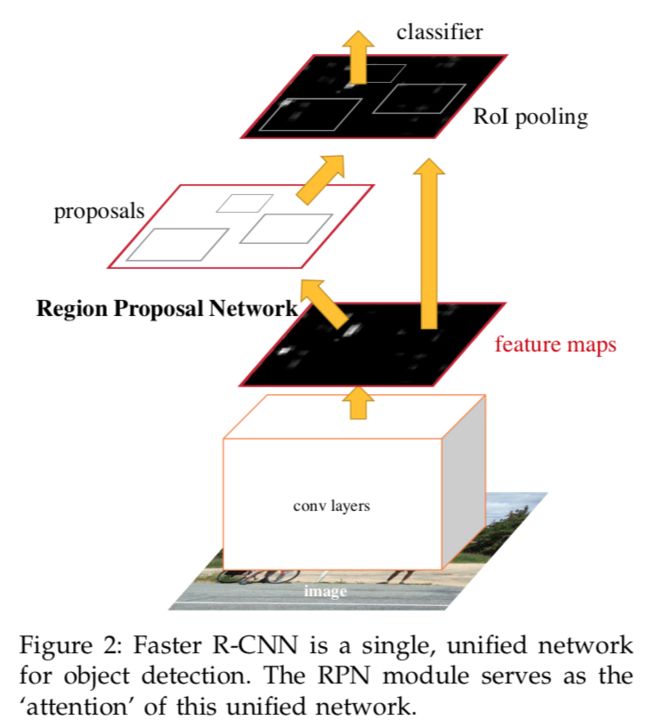
3.1 Region Proposal Network
RPN用任意大小的图像作为输入,输出是一组矩形候选目标,每一个矩形都有是否为目标的分数。
为了生成候选区域,在最后一个共享卷积层输出的特征图上滑动一个小网络。该小网络将特征图的n × n空间窗口作为输入。每个滑动窗口映射为低维特征(ZF 256-d,VGG 512-d,后面跟着ReLU),之后将该特征输入两个并行的全连接层,一个为box回归层(reg),一个为box分类层(cls)。本文设置n=3。这个mini网络在一个位置上的示例如图3左所示。注意该mini网络以滑动窗口方式运行,因此所有空间位置共享全连接层。该架构很自然地用n x n卷积层实现,后面跟着两个并行的1 x 1卷积层(分别用于reg和cls)
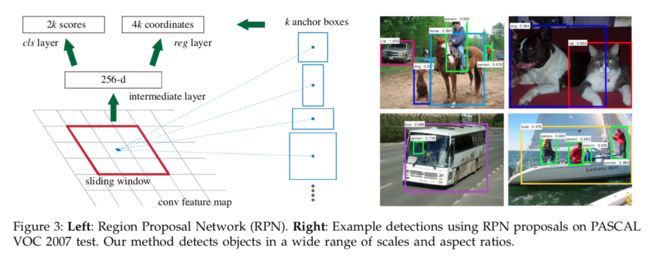
3.1.1 Anchors
在每个滑动窗口位置,同时预测多个候选区域,其中每个位置最大可能侯选数定义为k。因此回归层有4k个输出,用于编码k个box的坐标,分类层有2k个得分,用于估计每个候选是否为目标的概率(本文为了简化实现用了2分类的softmax层,其实也可以用逻辑回归生成k个得分作为预测)k个候选相对于k个参考框(本文称为anchors)参数化。anchor位于滑动窗口的中心,并且与尺度和纵横比相关联。默认在每个滑动位置设置3个尺度和3个纵横比,生成k=9个anchors。对于大小为W x H的卷积特征图,总共有W x H x k个anchors(2400多个)。
平移不变的Anchors
本文方法的一个重要属性就是平移不变性,anchors和计算相对于anchors的候选都有这个特点。如果平移一幅图像上的一个目标,候选也应当平移,在每个位置上预测候选的函数也应一样。这种平移不变性是由FCN的特点保证的。平移不变性也减小了模型的大小,当k=9个anchors时,有(4+2) x 9维的卷积输出层。
作为回归参考的多尺度Anchors
见图1。本文方法仅仅依赖单尺度图像和特征图,单独大小的滤波器(特征图上的滑动窗口)。正是由于这种基于anchors的多尺度设计,本文方法能简单的在单尺度图像上计算卷积特征。多尺度anchors的设计是共享特征的关键组件,而无需额外的成本去解决尺度问题。
3.1.2 Loss Function
为了训练RPNs,给每个anchor赋予一个二元标签(是否为目标)。当符合以下条件之一时,赋为正标签:
a. 与真实box有最高IoU的anchor
b. anchor与任意真实box的IoU>0.7
注意一个真实box可以给多个anchors赋予正标签。如果anchor和所有真实box的IoU都小于0.3则赋为负标签。如果Anchor即非正也非负则对训练目标没有贡献。基于这些定义,一幅图像的损失函数定义如下:
式中,i为mini-batch中一个anchor的索引,为anchor i是目标的预测概率。如果anchor是正的,真实标签为1,anchor是负的,则为0。是预测的边界框的4个参数化坐标的向量表示,是与正anchor关联的真实box。分类损失是两个类的对数损失(是否为目标)。对于回归损失,用,其中R是Fast R-CNN定义的健壮损失函数(平滑L1)。意味着仅当用于正anchor时回归损失是激活的。(和mini-batch size一样),(anchor位置的数量),设置,以使分类和回归的权重大致相等。另外发现上式的规范化并不是必需的,也许可以简化掉。。

对于边界框回归,采用R-CNN中的4个坐标的参数化:
其中是box中间的坐标及其宽高。变量分别为预测box,anchor box,真实box。上面的式子可以理解为从anchor box到附近真实box的边界框回归。
然而,本文的边界框回归方法与之前的SPPnet,Fast R-CNN又有所不同。之前方法的边界框回归是对任意大小的RoIs执行特征池化,并且回归权重由所有区域大小共享。本文定义中,用于回归的特征在特征图上有同样的空间大小(3 x 3)。为了考虑不同的大小,学习了一组k个边界框回归。每个回归负责一种尺度和一种纵横比,k个回归不共享权重。
多亏了anchors的设计,即使特征具有固定的尺寸/比例,仍然可以预测各种尺寸的boxes。
3.1.3 训练RPNs
每个mini-batch从一幅图像上生成许多正负anchor样本。对所有的anchor进行优化也是可以的,不过这样会朝着负样本偏移,因为它们占主导地位。取而代之,本文从一张图像上随机采样256个anchors,来计算一个mini-batch的损失函数,其中正负anchors的比例为1:1。当一幅图像上的正样本少于128个时,才用负样本补齐。
对所有新加的层用高斯分布做初始化,其余层用ImageNet预训练权重。基于Caffe实现。
3.2 用于RPN和Fast R-CNN的共享特征
有3种方式来训练共享特征的网络
a. 交替训练
先训练RPN,然后用候选训练Fast R-CNN。通过Fast R-CNN调优的网络再初始化RPN,然后迭代这个过程。
b. 近似的联合训练
如图2所示,在训练期间RPN和Fast R-CNN合并为一个网络。在每个迭代中,前向传播生成的候选区域被视为就好像固定的,预先计算好的候选,用于训练后面的Fast R-CNN。
c. 非近似的联合训练
RoI pooling
4步交替训练
本文采用4步训练算法来学习共享特征
1 如3.1.3节描述,训练RPN。用ImageNet预训练权重,并做基于候选区域任务的微调。
2 使用第一步RPN生成的候选训练Fast R-CNN。检测网络也用ImageNet预训练权重,此时两个网络还没共享卷积层
3 用检测网络来初始化RPN训练,但是固定共享卷积层,仅微调RPN特有的层。此时两个网络共享卷积层
4 保持共享卷积层固定,微调Fast R-CNN特有的层
3.3 实现细节
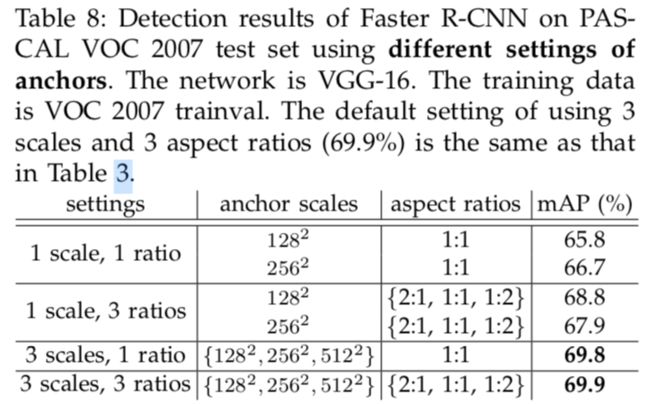
对于anchors,使用3种尺度,3种纵横比。
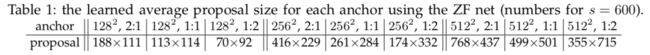
与图像边界交叉的anchors需要仔细处理。在训练时,忽略了所有边界交叉的anchors。测试时对边界交叉anchor做图像边缘的裁剪就行了。
用IoU阈值为0.7的NMS,这样每幅图大约还剩2000个候选区域。再用这2000个候选区域训练Fast R-CNN。
4 实验
4.1 PASCAL VOC
VOC2007包含5千张训练集,5千张测试集,20类。


RPN的剥除实验
见表2下半部分。
尽管anchor有多种尺度和纵横比,对于精确的检测也是不够的。
VGG-16的性能
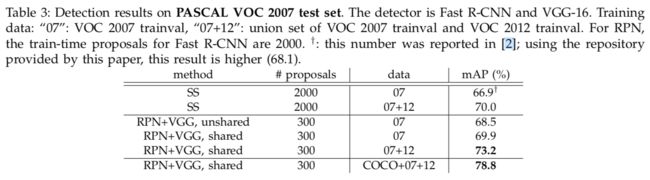
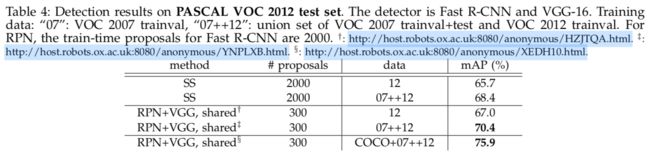
对超参数的敏感性
见表8,表9。
Recall-to-IoU分析
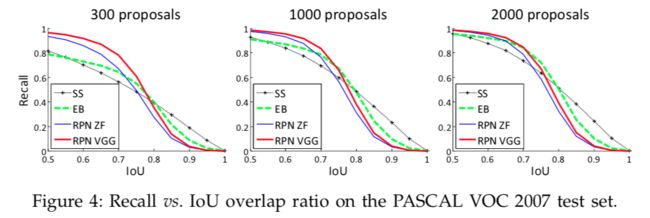
如图所示,当候选数量从2000降到300时,RPN方法表现得很好。这也解释了为什么在使用少至300个候选时RPN仍然有很好的mAP。正如前面分析的,这要归功于RPN的cls。
一阶段检测 vs. 二阶段候选 + 检测
OverFeat是一阶段,类相关的方法。

4.2 MS COCO
VOC2007包含8万张训练集,4万张验证集,2万张测试集,80类。针对这个数据集也做了几点轻微的修改。用8卡GPU实现,RPN的batch size为8(每卡1个),Fast R-CNN的batch size为16(每卡2个)。因为batch size改大了,学习率也跟着调大。对于anchors,用3个纵横比4个尺度(加了64 x 64),主要目的是处理数据集中的小目标。

将VGG-16用ResNet-101替换后,mAP从41.5%/21.2%提升到48.4%/27.2%(basenet的影响还是很明显的)
4.3 从MS COCO到PASCAL VOC
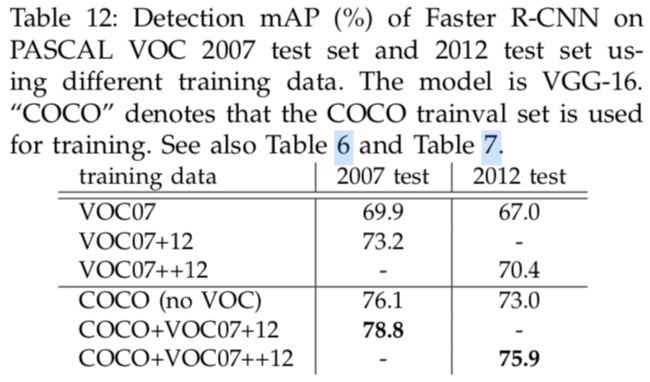
COCO的类别是VOC的超集,所以预测VOC的训练数据可以加上COCO。从表12可以看出,数据集的影响还是很大的。
5 总结
提出RPN用于生成候选区域。通过与下游的检测网络共享卷积特征,生成候选区域这步几乎没有额外的代价。本文方法提供一个统一的,基于深度学习的目标检测系统,可以近实时的运行。因为学习到的RPN提升了候选区域的质量,因此也改进了整个目标检测的准确率。
七 读后感
这个论文是系列的,还是得看Fast R-CNN和R-CNN,它们分别递进的解决不同的问题。
素质四连
要解决什么问题
生成候选区域和之后的检测网络是割裂的
用了什么方法解决
提出RPN,用一个网络统一生成候选区域和Fast R-CNN
效果如何
共享卷积特征,在提速的同时检测效果也有稍许提升
还存在什么问题
虽然已经是Faster了,相比一阶段还是不够快。
八 补充
基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
从编程实现角度学习Faster R-CNN(附极简实现)
一文读懂Faster RCNN
RoI pooling/Spp和max pooling很像,除了在重叠区域的pooling。(rbg在ICCV15的slides第16页)
因为原始图像上物体大小不一样,所以需要将这些抠出来的Region想办法resize到相同的尺寸,这一步方法很多(pooling或插值都可以,一般采用pooling,因为反向传播时求导方便)
Regoin Proposal的作用:
如果没有,会产生过多的不包含任何有用的类别的region,因为这些region数量庞大,不能为softmax带来有用的性能提升(因为无论怎么预测,其类别都是背景,对于该识别的类别没有贡献)。这些无用的Region都要单独进入分类网络,十分耗费计算时间。
整张图像上,所有的框,一开始就由anchor和网络结构确定了。所有后续的工作,RPN提取前景和背景,其实就是保留包含前景的框,丢掉包含背景的,包括后续的NMS,也是丢掉多余的,并非重新新建一个框。网络输出的两个bbox回归,都是输出坐标偏移量,也就是在初始锚点的基础上做的偏移修正和缩放,并非输出一个原图上的绝对坐标。
每个特征图上的点都有9个anchor,对于下采样16倍,生成(H/16) x (W/16) x 9个anchor,对于一个512x62x37的feature map,大约有2w个anchor,这种做法很像暴力穷举,2w多个哪怕是蒙也能把ground truth蒙中。
SPP的第一个贡献就是将金字塔思想加入到CNN,实现了数据的多尺度输入。在卷积层和全连接层之间加入了SPP层,此时网络的输入可以是任意尺度的,在SPP层中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。
ROI pooling其实就是一个单层SPPNet
rbg自己在slide里说了,当时用4步交替训练法并没有任何基础原则,只是仅仅为了在NIPS deadline前交稿。。。
R-CNN的3个问题:
1 测试时很慢:需要在每一个候选区域运行完整的CNN
2 SVM和回归是后处理:在响应SVM和回归时CNN特征没有更新
3 复杂的多阶段训练流程
Fast R-CNN如何解决的:
1 共享候选区域的卷积计算
2 3 端到端的训练整个系统(multi-task loss)
Fast R-CNN的问题:
测试时速度并不包括候选区域提取
Faster R-CNN如何解决的:
让CNN也来做候选区域提取!