这是阿里巴巴搜索基础设施团队高级总监Xiaowei Jiang的客座文章。这篇文章改编自阿里巴巴在Flink Forward 2016上的演讲,你可以在这里看到会议的原始演讲。
阿里巴巴是全球最大的电子商务零售商。我们2015年的年销售额总计3940亿美元 - 超过eBay和亚马逊的总和。阿里巴巴搜索是我们的个性化搜索和推荐平台,是我们客户的关键切入点,负责我们的大部分在线收入,因此搜索基础架构团队不断探索改进产品的方法。 是什么让电子商务网站上的搜索引擎变得更好?实时的结果对于每个用户而言尽可能相关且准确。
在阿里巴巴的规模上,这是一个非常重要的问题,很难找到能够处理我们用例的技术。 ApacheFlink®就是这样一种技术,阿里巴巴正在使用基于Flink的系统Blink,为其搜索基础设施的关键方面提供支持,并为最终用户提供相关性和准确性。
在这篇文章中,我将介绍Flink在阿里巴巴搜索中的角色,并概述我们选择在搜索基础架构团队中与Flink合作的原因。 我还将讨论如何通过Blink调整Flink以满足我们的独特需求,以及我们如何与数据工匠和Flink社区合作,将这些更改贡献给Flink。一旦我们成功将我们的修改合并到开源项目中,我们正在积极地将我们的系统从Blink转换为vanilla Apache Flink。
第1部分:阿里巴巴搜索中的Flink
文档创建
为用户提供世界级搜索引擎的第一步是构建可供搜索的文档。在阿里巴巴的案例中,该文件由数百万个产品清单和相关产品数据组成。 搜索文档创建是一项挑战,因为产品数据存储在许多不同的地方,并且由搜索基础架构团队将所有相关信息汇集在一起以创建完整的搜索文档。一般来说,这是一个3阶段的过程:
- 将来自不同来源(例如MySQL,分布式文件系统)的所有产品数据同步到一个HBase集群中。
- 使用业务逻辑将来自不同表的数据连接在一起,以创建最终的可搜索文档。这是一个HBase表,我们称之为'Result'表。
- 将此HBase表导出为文件或一组更新。
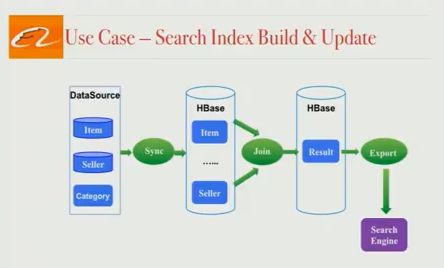
所有这三个阶段实际上都在经典的“lambda架构”中的2个不同的管道上运行:完整构建管道和增量构建管道。
- 在完整构建管道中,我们处理所有数据源,这通常是批处理作业。
- 在增量管道中,我们处理批处理作业完成后发生的更新。例如,卖家可以修改价格或描述,或者库存可用性可能会发生变化。此信息必须尽快反映在搜索结果中。增量构建管道传统上是流工作。
搜索算法的实时A/B测试
我们的工程师定期测试不同的搜索算法,并且需要能够尽快评估性能。现在,这个评估每天发生一次,但我们想要实时进行分析,因此我们使用Blink构建了一个实时的A/B测试框架。在线日志(展示,点击,事务)由解析器和过滤器收集和处理,然后使用某些业务逻辑连接在一起。接下来,聚合数据,并将聚合结果推送给德鲁伊; 在德鲁伊内部,可以编写一个查询来对数据执行复杂的OLAP分析,并查看不同算法的执行情况。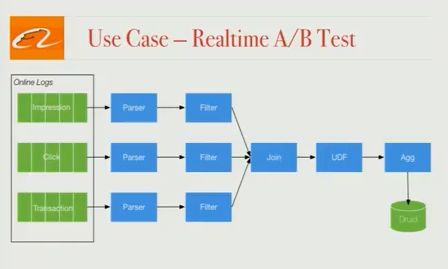
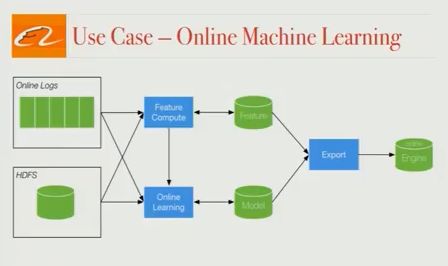
在线机器学习
这里有几个应用程序,首先,我们将讨论实时功能更新。阿里巴巴搜索排名中使用的一些功能包括产品点击率,产品库存和总点击次数。这些数据会随着时间的推移而变化,如果我们可以使用最新的可用数据,我们将能够为用户提供更相关的搜索排名。我们的Flink管道为我们提供在线功能更新,并大大提高了转换率。 其次,一年中有特定的日子(如单身日))产品大幅折扣 - 有时高达50% 。 因此,用户行为发生了巨大变化。交易量巨大,通常比我们在正常日子看到的高很多倍。我们之前训练过的模型在这种情况下毫无用处,因此我们使用我们的日志和Flink流媒体作业来支持在线机器学习,构建考虑实时数据的模型。结果是这些不常见但非常重要的销售日的转化率要高得多。
第2部分:选择一个框架来解决问题
当我们选择Flink为我们的搜索基础设施提供支持时,我们的评估包括以下四个类别。Flink满足了我们四个方面的要求。
- 敏捷性:我们的目标是能够为整个(2管道)搜索基础架构流程维护一个代码库。我们想要一个足够高级的API来表达我们的业务逻辑。
- **一致性: **对卖方或产品数据库的更改必须反映在最终搜索结果中,因此搜索基础架构团队需要至少一次语义(对于公司中的其他一些Flink用例,我们只有一次要求)。
- 低延迟:当库存可用性发生变化时,必须非常快速地反映在搜索结果中; 例如,我们不希望对售罄的产品给出高搜索排名。
- 成本:阿里巴巴处理大量数据,在我们的规模上,效率提升可显着节省成本。我们需要一个能够有效处理高吞吐量的框架。
更广泛地说,有两种方法可以考虑统一批处理和流处理。第一种方法是使用批处理作为起点,然后尝试在批处理之上构建流。但是,这可能无法满足严格的延迟要求,因为模拟流的微批处理需要一些固定的开销 - 因此,当您尝试减少延迟时,开销的比例会增加。在我们的规模上,需要为每个微量接头安排1000个任务,重新建立连接,并重新加载状态。因此,在某些时候,微批方法变得过于昂贵而无法理解。 另一方面,Flink使用流媒体作为基本起点,并在流媒体之上构建批处理解决方案,批处理基本上是流的特殊情况。使用这种方法,我们不会在批处理模式下失去优化的好处 - 当流是有限的时,您仍然可以进行任何您希望进行批处理的优化。
第3部分:什么是Blink?
Blink是Flink的分支版本,我们一直在努力满足我们在阿里巴巴的一些独特要求。此时,Blink正在几个不同的集群上运行,每个集群大约有1000台机器,因此大规模的性能对我们来说非常重要。 Blink的改进通常包括两个方面:
- 使Table API更加完整,以便我们可以为批处理和流式传输提供相同的SQL
- 更强大的YARN模式仍然与Flink的API和更广泛的生态系统100%兼容
表API
我们首先添加了对用户定义函数的支持,以便将我们独特的业务逻辑轻松地引入Flink。我们还添加了一个流到流的连接,这是一项非常重要的任务,但由于Flink对州的一流支持,在Flink中相对简单。接下来,我们添加了一些不同的聚合,最有趣的可能是distinct_count,以及窗口支持。 (编者注:FLIP-11涵盖了与上面列出的功能相关的Flink的一系列Table API和SQL改进,建议读者阅读对该主题感兴趣的任何人。)

接下来,我们将介绍运行时改进,我们可以进入四个单独的类别。
Blink on Yarn
当我们开始我们的项目时,Flink支持2种集群模式:独立模式和YARN上的Flink。在YARN模式下,作业无法动态请求和释放资源,而是需要预先获取所有必需的资源。并且不同的作业可能共享相同的JVM进程,这有利于资源利用而不是资源隔离。 Blink包含一个体系结构,其中每个作业都有自己的JobMaster,可根据作业的要求请求和释放资源。并且不同的作业不能在同一个Java进程中运行,从而在作业和任务之间产生最佳隔离。阿里巴巴团队目前正在与Flink社区合作,将这项工作贡献给开源,并且FLIP-6(除了YARN之外还扩展到其他集群管理器)可以获得改进。

Operator Rescale
在生产中,我们的客户可能需要改变运营商的并行性,但与此同时,他们不想失去状态。当我们开始研究Blink时,Flink不支持在保持状态的同时改变运算符的并行性。Blink将“桶”概念作为国家管理的单位。存在比任务更多的存储桶,并且每个任务将被分配多个存储桶。当并行性发生变化时,我们会将桶重新分配给任务。使用此方法,可以更改运算符的并行性并维护状态。
(编者注: Flink社区同时为Flink 1.2解决了这个问题 - 该功能在最新版本的主分支中可用。Flink关于“关键组”的概念在很大程度上与上面提到的“桶”相同,但实现方式略有不同,数据结构如何支持这些桶。有关更多信息,请查看Jira中的FLINK-3755。)

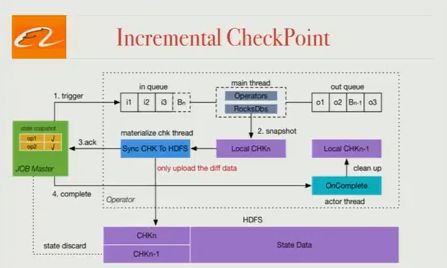
增量检查点
在Flink中,检查点分两个阶段进行:在本地拍摄状态快照,然后将状态快照保存到HDFS(或其他存储系统),并且状态的整个快照与每个快照一起存储在HDFS中。我们的状态太大,不能接受这种方法,因此Blink只将修改后的状态存储在HDFS中,并且我们已经能够大大提高检查点效率。这种修改使我们能够在生产中使用大型状态。
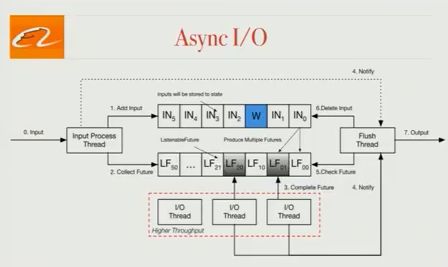
异步I / O.
许多工作的生产瓶颈是访问HBase等外部存储。为了解决这个问题,我们引入了异步I / O,我们将致力于为社区做出贡献,并在FLIP-12中进行了详细介绍。 (编者注:数据工匠认为FLIP-12足够大,可以在不久的将来在某个时候单独写一篇文章。所以我们只是简单介绍一下这个想法,暂时你应该看看如果您想了解更多内容,请参阅FLIP文章。在发布时,代码已经提供给Flink。)
第4部分:阿里巴巴Flink的下一步是什么?
我们将继续优化我们的流媒体作业,特别是更好地处理临时偏斜和慢速机器,而不会否定背压的积极方面和更快的故障恢复。正如Flink Forward的一些不同发言人所讨论的那样,我们认为Flink作为批处理器和流处理器具有巨大的潜力。我们正在努力充分利用Flink的批处理功能,并希望在几个月内实现Flink批处理模式。 会议的另一个热门话题是流式SQL,我们将继续在Flink中添加更多的SQL支持和Table API支持。阿里巴巴的业务继续增长,这意味着我们的工作变得越来越大 - 确保我们可以扩展到更大的集群变得越来越重要。 非常重要的是,我们期待继续与社区合作,以便将我们的工作贡献回开源,以便所有Flink用户都能从我们在Blink中投入的工作中受益。我们期待在Flink Forward 2017上向您介绍我们的进展情况。
本篇文章翻译自 https://www.ververica.com/blog/blink-flink-alibaba-search